Implement a text frontend #678
Labels
Comments
|
变调规则 #632 |
需要有两种方案的lexicon文件。 |
|
This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions. |
|
This issue is closed. Please re-open if needed. |
Jackwaterveg
pushed a commit
to Jackwaterveg/DeepSpeech
that referenced
this issue
Jan 29, 2022
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
TTS 文本前端任务
我们参考一般的流程,把文本前端分为4个阶段
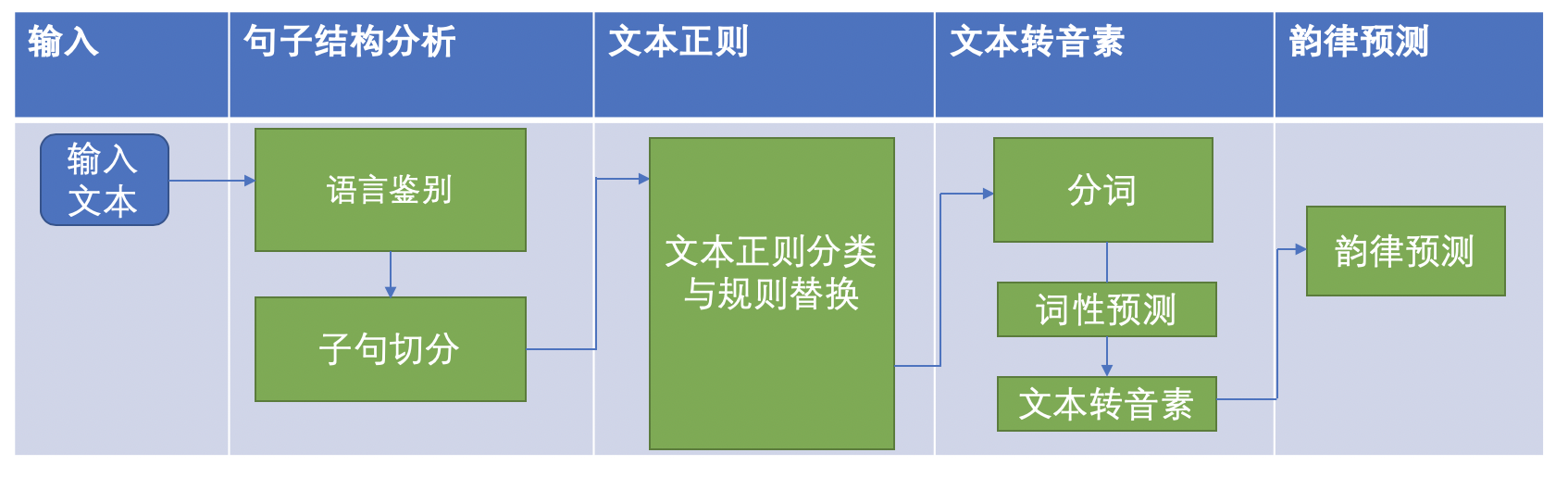
我们给系统输入一个文本,系统要先判断这个文本是什么语言,只有知道是什么语言才知道接下来如何处理。然后把文本划分成一个一个的句子。这些句子再送给后面的模块处理。
在中文场景下,文本正则的目的是把那些不是汉字的标点或者数字转化为汉字。比如「这个操作666啊」,系统需要把「666」转化为「六六六」。
也就是把文本转化为拼音,由于中文中多音字的存在,所以我们不能直接通过像查新华字典一样的方法去找一个字的读音,必须通过其他辅助信息和一些算法来正确的决策到底要怎么读。这些辅助信息就包括了分词和每个词的词性。
用于决定读一句话时的节奏,也就是抑扬顿挫。但是一般的简化的系统都只是预测句子中的停顿信息。也就是一个字读完后是否需要停顿,停顿多久的决策。
其中文本正则化分为三个阶段:
文本转音素分为两个阶段:
下面分阶段说明我们希望它如何运作:
文本正则化
Tokenization
一般来说,tokenization 并不等于分词,Multiple Word Token 是存在的,对于 TTS 领域尤为如此,把 4/5, 2020 分开之后,4/5 单独来看可能就难以分清是分数还是比率还是日期了。在基于规则的 Kestrel 系统中,也同样存在。日期,时间,货币,度量短语等是被作为一个单独的 token 处理的,这样也更加符合 TTS 领域的需求。
对于中文领域,如果能复用现有的分词工具是最理想的选择。但现有的中文的分词工具,在分词时,对于 NSW 或者非汉语片段的处理方式值得注意,并没有明确或者统一的处理方式。
NSW 分类
按照 Kestrel 的做法,对于每个 token 进行三分类,
目前我们计划支持的类别有
整数 CARDINAL
基础组件,在其他类型的 NSW 基本都需要。
序数 ORDINAL
汉语里面基本和基数读法没有差别,除了前附的“第-” ,以及序数中不使用“两”表示数字
2.浮点数 DECIMAL
整数部分按整数读法,小数部分按编号读法。
百分数 PERCENTAGE
百分比的部分按照浮点数读法,前附“百分之”。
分数 FRACTION
分子和分母按照浮点数读法,分母 + “分之” + 分子。
如果有前附整数,先读整数部分,中间加“又”。
比值 RATIO
两部分按浮点数读法,中间加比。
时间 TIME & DURATION
分时间点和时间段两种读法。同时还需要判断是时分秒齐全还是仅有时分还是仅有分秒。
时间段的读法,几小时几分钟几秒即可,各个部分按照整数读法。
时间点的读法,几点几分几秒,各个部分按照整数读法,但是,从第二个数字开始,前附的 0 需要读出。
日期 DATE
需要判断是年月日各段齐全还是仅包含年月还是月和日,各个部分按照整数的读法。
货币 CURRENCY
判断是仅包含一种货币单位的浮点数读法。
还是十元五角这种包含多个货币单位的读法,按照文本的实际写法读出。各个部分按照整数读法。
度量短语 MEASUREMENT EXPRESSION
按照浮点数读法加上对应的度量即可。但是部分度量可能影响符号的读法,比如零下三度一般不读作负三度。度量则需要一个词典。
编号 DIGITS
按照各个数位读出即可。
电话 PHONE
一般按照编号的读法,但是可能存在
一读作yao1的惯例。邮箱 EMAIL
网址
邮箱和网址主要都是涉及英文的读法,所以目前还没有很好的处理方式。
我们的方案是:
一个规则采用
f: NSW -> normalized words的方法实现。NSW 里面可以根据不同的类别设定不同的字段,并且把字段填充上,这样 verbalization 的时候就可以无需再进行解析。填充的过程可以使用正则表达式做分组匹配。目前需要做的是,对每一个类别实现一个类型,约定其需要填充的字段,并且写好对应的正则表达式规则去匹配。
Verbalization
Verbalization 的部分是对于每一类提供单独的规则进行展开。其中大部分可以调用数字的 verbalization 方法。各个类别的 Verbalization 方法已经写在上面一节。
G2P
汉字转拼音
目前使用的方案就是先分词(对正则化后的文本分词),然后把分词的结果交由 pypinyin 处理。自定义可以通过自定义单字字段和短语字典的方式来实现。目前主要的问题有多音字和变调。
多音字目前主要通过扩增短语词典的方式来实现,这样我们可以通过扩增词典来修改 bad case.
轻声可以通过词典解决.
“一” “不” 变调的问题相对简单,只要看其后面的字的声调即可。
三声变调问题相对复杂一些。对于连续的上声字组成的短语,需要分析内部的结构才能准确标注变调。
拼音转音素
目前我们有两个方案,但是大同小异,其中一套和汉语拼音更为相近,只需要做简单的处理,另一套则则是识别领域的方案。
Reference
The text was updated successfully, but these errors were encountered: