- This work is based (obviously) on the widevine-l3-decryptor extension. Many parts are the same, parts of Readme are a verbatim copy, etc.
- I have no working knowledge of Chrome extension structure.
- Some parts of code are copied from RFC documents, wikipedia, etc. shrug
- Tldr: The result seems to work, but relies on code lifting into wasm module and lots of brute-forcing, resulting in about 15-minute wait for a single RSA decryption. UPDATE While writing README, I found encoding tables
- I am too lazy to improve on this.
- Bignum arithmetics was taken from CryptoPP library. I found it the easiest library to work with and easiest to compile into wasm as well.
- Should work with widevine for 64bit Windows of version 4.10.2209. Unlikely to work for any other versions.
Widevine is a Google-owned DRM system that's in use by many popular streaming services (Netflix, Spotify, etc.) to prevent media content from being downloaded.
But Widevine's least secure security level, L3, as used in most browsers and PCs, is implemented 100% in software (i.e no hardware TEEs), thereby making it reversible and bypassable.
This Chrome extension demonstrates how it's possible to bypass Widevine DRM by hijacking calls to the browser's Encrypted Media Extensions (EME) and (very slowly) decrypting all Widevine content keys transferred - effectively turning it into a clearkey DRM.
To see this concept in action, just load the extension in Developer Mode and browse to any website that plays Widevine-protected content, such as https://bitmovin.com/demos/drm . First, extension will try to brute-force input encoding for the code-lifted part. Then, assuming it succeeds, keys will be logged in plaintext to the javascript console. (Update: will avoid brute forcing now)
e.g:
WidevineDecryptor: Found key: 100b6c20940f779a4589152b57d2dacb (KID=eb676abbcb345e96bbcf616630f1a3da)
Decrypting the media itself is then just a matter of using a tool that can decrypt MPEG-CENC streams, like ffmpeg.
e.g:
ffmpeg -decryption_key 100b6c20940f779a4589152b57d2dacb -i encrypted_media.mp4 -codec copy decrypted_media.mp4
NOTE: The extension currently supports the Windows platform only.
It is my honest opinion that DRM is a malignant tumor growing upon various forms of media, and that people that either implement or enforce implementation are morally repugnant and do no good to society. With that in mind, I was sad to learn in May 2021 that the original extension would soon be rendered obsolete. I found myself with some free time on my hands, and so I decided to try and replicate original key extraction. Unfortunately, there was not much data pertaining to what process the original's authors used, and even some confusion as to who was the one who performed extraction. Nevertheless, I decided to give it a go, and hopefully boost my flagging self-confidence a little. I did not succeed in either of those tasks, but I managed to write a barely-functioning decryptor, and decided to document the steps I followed, in case they are of use to somebody else.
In order to deal with executable, I decided to use Ghidra, despite its association with NSA, mostly because it is free and has most features that I wanted. I also wrote a simple snippet to be able to debug dll.
lib = LoadLibrary(L"widevinecdm_new.dll");
if (lib != NULL)
{
InitializeCdmModule init_mod = (InitializeCdmModule)GetProcAddress(lib, "InitializeCdmModule_4");
CreateCdmInstance create = (CreateCdmInstance)GetProcAddress(lib, "CreateCdmInstance");
GetCdmVersion getver=(GetCdmVersion)GetProcAddress(lib, "GetCdmVersion");
printf("%d\n", (ulonglong)init_mod);
init_mod();
printf("%d %s\n", (ulonglong)create,getver());
getchar();
printf("Creating\n");
std::string keys = "com.widevine.alpha";
std::string clearkeys = "org.w3.clearkey";
ContentDecryptionModule_10* cdm =(ContentDecryptionModule_10 *) create(10, keys.c_str(), keys.length(), GetDummyHost, (void*) msg);
printf("Created? %d \n", (ulonglong)cdm);
unsigned int pid = 10;
const char* sid = "Sessid";
//pssh box?
byte initdata[92]= { 0, 0, 0, 91, 112, 115, 115, 104, 0, 0,
0, 0, 237, 239, 139, 169, 121, 214, 74,
206, 163, 200, 39, 220, 213, 29, 33, 237, 0, 0,
0, 59, 8, 1, 18, 16, 235, 103, 106, 187, 203, 52,
94, 150, 187, 207, 97, 102, 48, 241, 163, 218, 26, 13,
119, 105, 100, 101, 118, 105, 110, 101, 95, 116, 101,
115, 116, 34, 16, 102, 107,106, 51, 108, 106, 97, 83,
100, 102, 97, 108, 107, 114, 51, 106, 42, 2, 72, 68,50, 0};
gcdm=cdm;
printf("First compare: %d\n",(int)((byte *)gcdm)[0x92]);
cdm->Initialize(true, false, false);
printf("Sc compare: %d\n", (int)((byte*)gcdm)[0x92]);
getchar();
cdm->CreateSessionAndGenerateRequest(pid,SessionType::kTemporary,InitDataType::kCenc,initdata,91);
}
All structures in the above snippet are copied from Chromium eme sources, for example here.
First things first, I tried running the resulting program, producing proper signature as an (intermediate) result. Trying to trace it in debugger, however, caused problems. At first, it just crashed with access violation. After modifying BeingDebugged field in PEB, it instead went into infinite loop.
Looking at the decompiled code revealed a large amount of strange switch statements in most API functions. It looked somewhat like the following (from Ghidra decompiler):
while(true)
{
uVar5 = (longlong)puVar3 + (longlong)(int)puVar3[uVar5 & 0xffffffff];
switch(uVar5) {
case 0x1800f489e:
uVar5 = 5;
goto LAB_1800f488e;
case 0x1800f48ad:
local_20 = local_2c + 0x47b0e7d4;
uVar5 = 3;
goto LAB_1800f488e;
case 0x1800f48c1:
uVar5 = 0x17;
goto LAB_1800f488e;
case 0x1800f48c8:
local_28 = local_20 - local_2c;
bVar1 = (int)(uint)local_21 < (int)(local_28 + 0xb84f182c);
unaff_RSI = (undefined *)(ulonglong)bVar1;
uVar5 = (ulonglong)((uint)bVar1 * 5 + 2);
goto LAB_1800f488e;
case 0x1800f48f4:
local_28 = local_2c + 0xd689ea6;
uVar5 = 0x16;
goto LAB_1800f488e;
case 0x1800f4908:
uVar5 = 0x19;
goto LAB_1800f488e;
case 0x1800f491a:
local_2c = local_2c & local_28;
uVar5 = 1;
goto LAB_1800f488e;
case 0x1800f492c:
if (true) {
*(undefined *)¶m_1->_vtable = *unaff_RSI;
unaff_RSI[1] = unaff_RSI[1] - (char)(uVar5 >> 8);
/* WARNING: Bad instruction - Truncating control flow here */
halt_baddata();
}
...
After several days of investigation, it became obvious that that is a form of code obfuscation, breaking down code flow into small segments and arranging them in switch statement in order defined by a primitive PRNG. PRNG can be controlled to execute if/else statements and loops. The halt_baddata portion causes access violation crash when reached. Any jump table index outside bounds leads to while(true) executing indefinitely. Since switch is driven by PRNG, decompiler cannot seem to find limits of jump tables, resulting in invalid switch statements or mangled decompilation. I tried to ameliorate that by fixing jump tables, but results were not encouraging. I then tried to follow the instruction flow by using Ghidra Emulator API. AFter a lot of experimentation, I drew the following conclusions:
- Many of the switch cases are almost-duplicates, and some are either never reached or only reached in case of failed check, crashing program or sending it into infinite loop.
- The anti-debugging code is hidden within the switch statements.
- Most of anti-debugging code seems to be similar to what is decribed here. The list of the debugger windows names is exactly the same, which is amusing (and outdated).
- Some functions actually use memory checksums as PRNG seeds which makes guessing where it would go after impossible without knowing the checksum. And how many iterations it took to calculate it. And results of various checks in the middle. Etc...
- None of the anti-debugger tricks are activated by emulation, but emulation is literally hundreds, if not thousands of times slower than direct CPU execution, so that checksum calculation can take several hours (depending on log verbosity).
- Emulating just one function does not help much, since flow might depend on input parameters :( .
After that, I tried to reverse Protobuf encoding/decoding functions found in the code. While I did manage to find some of them (using getchar as a convenient breakpoint to attach debugger), they did not match Protobuf functions in the original repository, leading me to believe that the source file was changed. For example, SignedMessage now has more than 9 fields, rather than original 5. Luckily, protocol seems backward compatible enough, so the necessary signatures/keys can still be extracted. To parse protobuf messages, I used either original extension or this convenient website.
In any case, that investigation did not seem to lead anywhere, and in the end (after several weeks and lots of cursing), I decided to emulate the whole program in Ghidra. To that end, I developed a simple script that emulated system and host calls made by DLL. Necessary system calls were extracted by just running emulation until it came to the code it could not execute and replacing that with python function. As an aside, script executes one instruction at a time, so it is slower than using Ghidra breakpoints, but easier for me to manage. Manipulating it allowed me to dump logs of program flow and memory contents, as well as save and restore simulator state. Eventually, I managed to reach point where emulator formed a valid signature and called into fake host code with it. It took several days, though, with the longest part being something that seemed to be jump table and calculation table generation. After that, it was just a matter of tracing signature back to generation function.
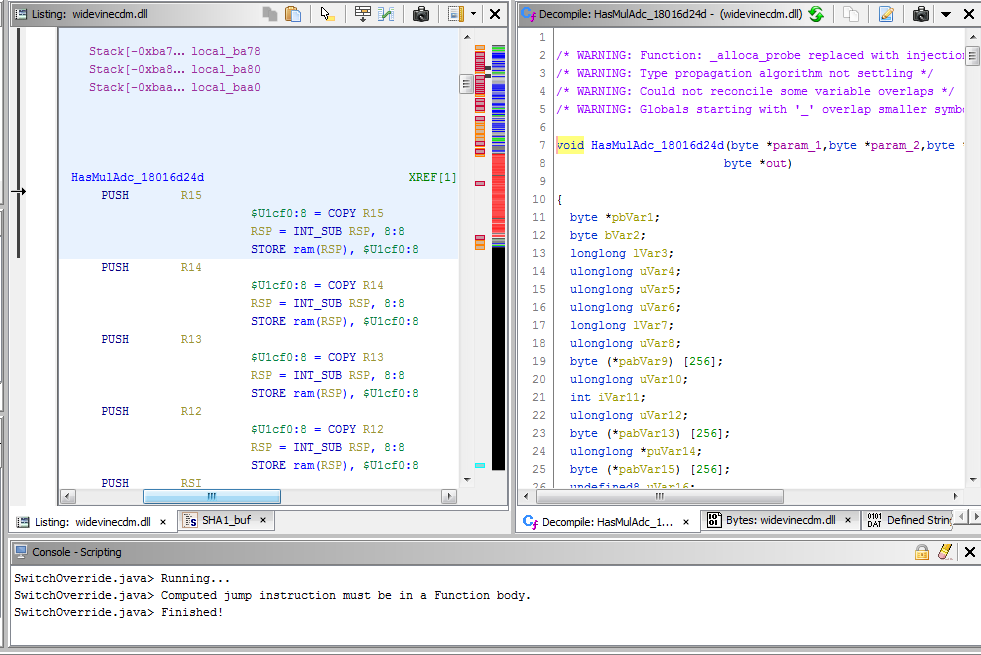
After staring at the wall of poorly decompiled code for a while, I realized that parts of it implement a simple Bignum multiplicaion algorithms, but instead of using linear arrays, they used arrays permuted by PRNG-like functions, so every arithmetic operation was preceded by permutation generator looking kind of like this:
uint * PFUN_180119595(uint *param_1,uint *out,uint length,int param_4)
{
byte *pbVar1;
uint uVar2;
ulonglong uVar3;
uint uVar4;
uint uVar5;
ulonglong uVar6;
bool bVar7;
uVar6 = (ulonglong)(length * 4);
if (*(char *)((longlong)out + uVar6) != '\x02') {
do {
pbVar1 = (byte *)((longlong)out + uVar6);
bVar7 = *pbVar1 == 0;
*pbVar1 = *pbVar1 ^ bVar7 * (*pbVar1 ^ 1);
} while ((byte)(!bVar7 * *pbVar1) == '\x01');
if (bVar7) {
if (length != 0) {
uVar5 = param_4 * 0xe286515;
uVar3 = 0;
do {
uVar2 = param_1[uVar3];
uVar4 = uVar2 ^ uVar5;
out[uVar3] = uVar4;
uVar5 = uVar5 + uVar2 * uVar4;
uVar3 = uVar3 + 1;
} while (length != uVar3);
}
*(undefined *)((longlong)out + uVar6) = 2;
}
}
return out;
}
Same function was used most of the time, but with different offsets and initial arrays, resulting in a variety of permutations. Regardless, I was able to roughly identify montgomery multiplications, subtractions and additions performed on 256-byte arrays (implying the use of 2048 bit keys). One of the most important factors was the use of "ADC" assembler command, mostly restricted to two areas of the code, which I tentatively identified as "signature generation" and "session key decryption". I concentrated on the former, since I could access and verify the output. Which did however raise the question about what kind of input the function took. More about that later.
Of course, sick, sadistic minds behind the obfuscation did not use a straightforward exponentiation algorithms. As described in Google patent US20160328543A1, they multiply input by constant and output by reversing constant, use permutation function to confuse memory layouts, and seem to use "split variables" at times, though not often in this case. In any case, resulting exponentiation function also has some additions which cancel each other in the end.
In order to extract the exponent from the code, I first logged most of the inputs and outputs of the functions that seemed to operate on bignum, unscrambling the permutation using the already generated tables in memory. Then, I used python script to guess the operations performed on the numbers, and a separate script to map those operations into a tree. The second script went through several iterations as I tried various things, including adding dual number support in order to extract exponent from the result's derivative. Ultimately, I settled on simple single-variable tracing. Finding a route that did not lead to exponential explosion in number of polynomial powers was somewhat of a challenge, but eventually (after,once again, a week or two of work :| ) I succeeded in extracting an exponent and multiplicative constant:
Integer sec_pwr("3551441281151793803468150009579234152846302559876786023474384116741665435201433229827460838178073195265052758445179713180253281489421418956836612831335004147646176505141530943528324883137600012405638129713792381026483382453797745572848181778529230302846010343984669300346417859153737685586930651901846172995428426406351792520589303063891856952065344275226656441810617840991639119780740882869045853963976689135919705280633103928107644634342854948241774287922955722249610590503749361988998785615792967601265193388327434138142757694869631012949844904296215183578755943228774880949418421910124192610317509870035781434478472005580772585827964297458804686746351314049144529869398920254976283223212237757896308731212074522690246629595868795188862406555084509923061745551806883194011498591777868205642389994190989922575357099560320535514451309411366278194983648543644619059240366558012360910031565467287852389667920753931835645260421");
Integer sec_mul("0x15ba06219067ebfbe9ed0b5f446f1dca81c3276915b6cd27621bfefe5cf287146c108442d6a292d7fb2a74fe560c1a57ada6d586250ecf339ee05bc86b762a448c18748c701f15d1ec5c5d1e18e406cfda1466300c5e6bcfe3133b03f296c219c1064da6d8108cbb4974d697faacc1d84207b4554accc45654225bf1dd257726eab616a1abe7e49e1182fb3ad8530b90bad454fe27088653fee80dd11dce148490c5344b0bb307050d35ff2fccaeff59f754bc2b28d780fc328e801f5b9371c35f12916f2ba89b3ae9c16e3fbaaf9a45e59b25b34ac1e0650cc6989ca7e3cac5f80feefd47c5ae684f6b82c45c735d57d884519e52eae19ee41e9aa9d336451e");
An example of log and script output can be found in log_parsing folder.
One can easily see that the exponent is 3072 bits in length, which is a lot longer than expected (2048). Obviously, since exponent is periodic, it can be extended to any length. It can be also confirmed that this is not a complete exponent, since the first bignum-like structure in the function does not match the encryption input. (Decryption of the RSA is easily done using public exponent, 65537). There is also no linear. or quadratic, or... (I checked polynomials to about 128th power) dependency. Which leads me to the following stage.
If one were to look at the function where exponentiation takes place, one would not that it has far too many input parameters.
void HasMulAdc_18016d24d(byte* param_1, byte* param_2, byte* param_3, byte* param_4, byte * param_5,byte * out)
In there, Param_1 seems to be constant, or at least input-independent. It is still necessary to get the correct result, but can be represented by static array. Parameters from 2 to 5, however, do depend on input... somehow. They are also permuted excessively in loops by ConstUser_18016b077 functions. These functions represent half of the input obfuscation, and are the reason why this repo id called "guesser". They use a sequence of runtime-generated lookup tables to perform a variety of functions on oddly encoded inputs. Sequences are also runtime generated or unpacked, I am not sure. Every call to that function contains sequence offset, processing length, etc, all combined together into a single 64bit number. Odd encoding in this case refers to the following: each X-byte number is split into X*4 chunks of 2 bits each, two more chunks are appended with what seems to be arbitrary numbers and the result is passed through one of the above Const functions, resulting in 3 bit(!) stored in each byte, like so (hex representation of 256-byte number into 1026 bytes): (I will call it long form from now on)
010506030600040701030601060303060006010000030100000301030004050106010006010106010300030600030100060101000103000606030303010001060600030301060303060300030601000100000006010103010300010101010101060100030300030303010006000003000301060100060106000000000600000003030402050003010001010003000600060106010601010100030601010303000103010405010003000303000601040506040506000606060600030600000103030300010601030006030000030001000600000601010603000001010001010000010001000000030603030000060006030303000001030405060306060401060000010301030601000600010001030103060101010606000006000004050001060006030304050600030306010001000606060600000003060006000301060600000100060003030001060600010306030003010300010303000001010606010300010101010006030000010103000301010101060001010405040207020205010000030603000606000100000006030600030104050001060300000600030000030303060003060600030606060000000001060606010003030101010104070205040506010600060004010603060300030101010303030300010301000000010001010300000600030101000601030300040501010600010001000000060000000000060301060301060100010101030000060405040501010106060006010001030103010101010106030600060104050103000001060604050006010100060306010300030000030600010101030606060301060301000100000003030100010103000003030405060601030000060106010600000000060000030600000601000001010006030004010601000006010000010001060301000103060106030003010306010601030101060106040702050000010300030300010601060103000004050103060405000401000000040501000303060006000106060306030606060103000003060301010000000606000300030003000104050103060303010606000601000100060301000601030103060600060004010000000304010301030000010003000603000100060006010000010303030600030104050006000601060006010600040503000001060306010300060000010003010606010401030103060301060006000000010303000003000006010304070501010405030100000300000000040101060000010600000106030306010103060000010001060601060000000303000300010303030101060601030001010300000301030106010600000601000006030000010100000604050001030603010006010106000601010601030301000001010601030000000001000603040106010306060101010000
Lookup tables in ConstUser_18016b077 essentially map 11 bit number(2x3 bit+5bit "carry") to 8-bit number(3-bit output plus carry). There are also other tables in the code that work on larger number of bits. But, since input and outputs are permuted in random order (and possibly have a carry bit), I could not for the life of me figure out what each of the (several thousands of) tables actually did. Each operation seemed to invoke a new table, or at least, a new sequence offset.
In any event, we have 4 or those numbers somehow generated from input and presented to exponentiation function. Where they are split into 18-bytes overlapping increments, processed in a loop, compressed back to 4-byte integers and passed on into yet another function:
void ManyMutiplies_1801720e0
(byte* param_1, byte* param_2, byte* param_3, byte* param_4, byte* param_5, byte* out)
Where... I have no idea :( I've spent a lot of time looking at the code, but to this day I have no idea what exactly it does to 4 input buffers. Those buffers do not seem to be representations of 256-byte bignums ( buffer length vary, but are mostly multiples of 90). A lot of operations involve preparations like
do {
*(int*)(local_8f90 + lVar6 * 4) =
*(int*)(local_8f90 + lVar6 * 4) +
*(int*)(local_8500 + lVar6 * 4) *
*(int*)((longlong)DAT_18091b030 + (ulonglong)((uint)lVar6 & 7) * 4);
lVar6 = lVar6 + 1;
} while (lVar6 != 0x4a);
Which seem perform multiplication and addition of 4-byte integer while discarding the carry? Then there are operations like this:
do {
uVar8 = (uVar8 >> 4) + *(longlong*)(DAT_18091af30 + (ulonglong)((uint)uVar8 & 0xf) * 8);
*(ulonglong*)(local_8f90 + lVar12 * 8 + 8) = uVar8;
lVar12 = lVar12 + 1;
} while (lVar12 != 0x10);
iVar46 = (int)lVar6;
lVar6 = *(longlong *)(&local_8f90[128]) * 0x434c3d5000000000 + *(longlong*)(&local_8f90[56]) * 0x7c7bcb1aebcb3c2b +
0x7ffc6ede4fe88090;
Which seem to use lookup tables (DAT_18091af30) to look up 8-byte carries? Yeah, to my great shame, I have no idea what I am looking at. The only thing that comes to mind is highly obfuscated Schönhage–Strassen algorithm, or something from that family, that is, something that involves Fourier or Number theoretic transform. That would allow some operations to be performed modulo power of two, or modulo power of two plus one, without using carry as much as simpler multiplication algorithms. So, if anyone has any good ideas, please raise an issue or pull request? Code is available...
After spending far too much time staring dumbly on decompiler and trying to run code modifications in Ghidra emulator, I decided to try dumping decompiled code into c++ file and making it compile again, with the "bright" idea of "maybe manipulating inputs will give me some insight". I believe that is what is called "code lifting"? That came with its own set of challenges. The major one was the fact that decompiler was confused by overlapping buffer accesses, and could not separate local variables properly. Other was that somebody in Ghidra decompiler team thought that accessing, say, last two bytes in uint64 should be represented as variable._6_2 instead of, say ((short*)&variable)[3]. One of those is not proper C... So I had to go through code and replace that. As well as guess at stack variable overlaps and split those, which took weeks of painstaking register comparison.
Next hurdle was a function that took two buffers already encoded into long form and spat out long form of almost-output. That one first ran table generation (unpacking?) and then jumped to runtime-generated point. Then it used a long array of addresses and values to jump over 6(?) possible code points and execute a variety of operations on data. The structure in the array looked somewhat like:
struct jumper
{
uint64 par1;
short par2;
short par3;
short par4;
short next_jump_offset;
};
And the array was long... 5153 operations long. If my guess about Fourier transformation is correct, that would probably be the function that performs inverse transformation, but once again, no idea ;(
The final hurdle of the code-lifting, and the one that contributed the most to the wasm size, was constant extraction. Some constants were available from the beginning, while others, such as lookup tables, were generated at various points at runtime. There were over 600 constants used, so in the end I just automatically grabbed them from memory dumps with a python script without checking the appropriate length, which resulted in a lot of overlap (it is better to have a too-long constant than access violation of undefined behavior). It is probably possible to cut the wasm size by at least half by carefully removing overlaps (and checking afterwards, since some seem necessary).
After performing all that, I managed to recreate HasMulAdc_18016d24d in c++ code. Unfortunately, I did not gain any insight. The dependencies of actual input number on input buffers seemed highly non-linear as well. After a lot of trial and error(s), I was left with no recourse but to recreate input function for signature, which, luckily, was not obfuscated by switch statement. Unlike previous version, however, actual RSA message to be exponentiated was never in memory during runtime, so I had to trace its creation from protobuf message.
One of the first ideas I came with, which eventually proved to be the most fruitful, was tracking SHA1 invocations. All SHA1 invocations should use the same starting values, as per wiki:
h0 = 0x67452301
h1 = 0xEFCDAB89
h2 = 0x98BADCFE
h3 = 0x10325476
h4 = 0xC3D2E1F0
By searching for those values or round constants in memory and tracking references to them, I managed to find a few areas that appeared to calculate SHA1, one of them quite near the exponentiation code(abridged):
void Longstringproc_18017e3b0(byte **param_1,stdstring *data,uint len,stdstring *param_4)
{
byte *charbuffer;
longlong lVar1;
undefined8 local_24b8;
byte output_24b0 [512];
byte local_22b0 [2056];
byte local_1aa8 [2056];
byte local_12a0 [1040];
byte local_e90 [1040];
byte local_a80 [1032];
byte local_678 [1032];
byte local_270 [82];
SHA1_buf buffer;
ulonglong local_50;
undefined8 uStack72;
lVar1 = 0x100;
STLStringResizeUninitialize(param_4,0x100,0);
charbuffer = (byte *)GetStrOffset_1801d456e(param_4,0);
local_24b8 = *param_1;
FUN_18011394e();
Fill_SHA_buffer_18016ae81(&buffer);
LooksLikeSha1_1801695b1((byte *)data,len,&buffer);
Shabuf_Transform_18016b9ac((uint *)local_270,&buffer);
Crazery_18016c0bb((char *)local_270,local_678,local_a80,local_e90,local_12a0);
OtherConstUser_180169484(0x10004020000345e1,local_678,local_678,local_1aa8);
OtherConstUser_180169484(0x1000402000007410,local_a80,local_a80,local_22b0);
Maybe_MEMSET_180512a50((char *)output_24b0,0xaa,0x200);
HasMulAdc_18016d24d(local_24b8,local_1aa8,local_22b0,local_e90,local_12a0,output_24b0);
do {
*charbuffer = output_24b0[lVar1 + -1];
charbuffer = charbuffer + 1;
lVar1 = lVar1 + -1;
} while (lVar1 != 0);
}
Indeed, that proved to be a signing function, with data being the message to be signed. LooksLikeSha1_1801695b1 calculates message hash, while other functions encode and decode normal hash to and from longform. As I mentioned before, at no point does the exponentiated value itself (that is, message hash padded as per RSA-PSS gudelines with "0xbc" appended) appear in memory in "normal" form, even permuted. Neither is the MGF1 calculated "in the clear". So whereis it calculated? Why, in the function using runime-generated jump tables, of course" That is, Crazery_18016c0bb... That function also uses the same functionality as ConstUser_18016b077, but with a twist: they use modulo arithmetics to permute the byte order in memory. Otherwise, the procedure is the same.
Unfortunately (for me), Ghidra was confused by missing jump table and produced garbage in decompiler, do I had to decompile the function mostly by hand. Fortunately, it only had ~6 jump entries which were not very long. After that, I ran the function while logging data inputs and outputs. In there, the first part is mostly MGF1 dunction, and of particular interest are these entries, since the data manipulated is 256 bytes, the size of RSA input:
0x3f9 Total length: 1026 Zeros1: 84 Chunk1: 942 Input: 330 Output: 11218 Cnt: 26762
0x812 First len: 86 Second len: 940 Source 1: 1402 Source 2: 11218 Destination: 19942 Cnt: 26763
0x60f Initial skip: 3 Processed len: 1023 Second len: 3 Input: 19942 Output: 11218 Cnt: 26764
0x812 First len: 1026 Second len: 0 Source 1: 7530 Source 2: 11218 Destination: 7530 Cnt: 26765
0x812 First len: 1026 Second len: 0 Source 1: 19942 Source 2: 7530 Destination: 11218 Cnt: 26766
0x812 First len: 1026 Second len: 0 Source 1: 3582 Source 2: 11218 Destination: 3582 Cnt: 26767
0x812 First len: 1026 Second len: 0 Source 1: 15058 Source 2: 7530 Destination: 7530 Cnt: 26768
0x812 First len: 1026 Second len: 0 Source 1: 7530 Source 2: 3582 Destination: 15058 Cnt: 26769
0x812 First len: 1026 Second len: 0 Source 1: 1490 Source 2: 7530 Destination: 1490 Cnt: 26770
0x812 First len: 1026 Second len: 0 Source 1: 11218 Source 2: 1490 Destination: 7530 Cnt: 26771
0x812 First len: 1026 Second len: 0 Source 1: 15058 Source 2: 15058 Destination: 3582 Cnt: 26772
0x812 First len: 1026 Second len: 0 Source 1: 7530 Source 2: 7530 Destination: 1490 Cnt: 26773
0x2b4 Length skip: 0 Length proc: 1026 Len 00: 12 Input1 7530 Input 2 7530 Output 23150 Cnt: 26774
After that, the input is somehow split into 4 parts of 259 bytes each. Part of the division is just splitting original input into sum of two numbers. The exact nature of further manipulation remains a mystery to me.
With this, the whole signing process is in c++ code!... so I can sign license requests, but cannot create custom inputs for decryption... yet.
By this point, i HaVe fAiLeD AlReaDy iN My gOaL oF eXtRaCtInG RsA key <_< IaM pRoBaBLy mISsinG soMeThINg trIViAl. AGAIN
All that i had left for me was to maybe find a way to modify input so that it would approach the encoded value, thereby decrypting ciphertext with section key. To do that, I tried to modify values at various steps above, then running the whole encryption/decryption cycle to see what the input is like. Some modifications did not produce any input differences at all, hinting at redundancies/ variable splitting (meaning, I was modifying something that was used as obfuscation and then cancelled out). Eventually, I found a few values (steps/memory offsets) that produced "linear" modifications to the input, linear in this case meaning that modification to a single byte resulted in localized modifications to the "input", not affecting previous input bytes unless wrapping was involved. Unfortunately, try as I may, I could not figure out the actual encoding used... Also, there were several locations affecting input (last 21 bytes of seed+padding and first 235 bytes were split into different variables). Eventually,I gave up and decided to brute-force input in 2-bit increments. Since one "decryption" operation took about ~1 second, that took... Quite a while.
Failure, failure, FaIlURe <_< But better than nothing?
Update: While writing this ReadMe, I kept fiddling with input encoding, and found out that just an operation later the output was XORed with another buffer to form original input. I also realized that whitebox engineers (that I would rather do something more moral, like human experimentation) were lazy, and used the same buffer to long form encoding tables in all locations instead of chaining them. So, after brute forcing table order, I managed to work out encoding procedure that seems to work for most inputs (maybe all, but I cannot prove that), so only a single decrypting operation is needed instead of ~4000 on average.
Now I had a chunk of c++ code doing "decryption" and "encryption" given a long-form input guess. I needed a way to connect in into Chrome browser. The obvious way, of course, is to use Emscripten to compile c++ code into WebAssembly, support for which was added to Chrome... recently enough. Emscripten also provides an initial JS wrapper for the exported functions.
Luckily, a single command managed to compile c++ file with some CryptoPP support after a few minor modifications. Originally, I put the brute-forcing code out into Javascript so it could be more easily interrupted and monitored. Unfortunately, while the program was working, it was unbearably slow and tended to freeze video playback. AnoTHer faIlUre <_< At least that one was later resolved.
The last thing was to remove OAEP padding. Why is it so hard to get a proper info on those formats outside of RFC? Unfortunately, original repository used library that combined decryption with padding removal, so I decided to simply put a rough implementation of RFC into c++ code, since it was already plenty bloated. That seemed to work well enough for the purpose.
In the end, I only extracted about half of the RSA key. I am not sure how long is the key that remains in whitebox, though I have checked values up to about 64000 (power value, not bits). Neither I am sure why or how input was split into 4 buffers. I am leaving this ReadMe and scripts here in some hope that they may help when Google inevitably changes key again. As an additional reference, author of original repo, Tomer8007, uploaded writeup on original extraction method, seemingly somewhere around the time I was uploading my repo. It is a lot better than mine here, so give it a read as well.
All in all, it was a decent, albeit somewhat depressing exercise that I have little desire to ever repeat. I will probably cease updating repo soon after Readme is finished, so for people that want it modified: please fork or copy it and modify as you see fit. Attribution is appreciated, though ;)
The end.