
Welcome to the repository of Benchmark for Anonymous Video Analytics (AVA) for digital out-of-home audience measurement. AVA aims to enable real-time understanding of audiences exposed to advertisements in order to estimate the reach and effectiveness of each advertisement.
AVA relies on person detectors or trackers to localize people and to enable the estimation of audience attributes, such as their demographics. The benchmark is composed of:
- a set of performance scores specifically designed for audience measurement and an evaluation tool;
- a novel fully-annotated dataset for digital out-of-home AVA;
- open-source codes including detectors, trackers, and age and gender estimation baseline algorithms, evaluation codes; and
- benchmarking of the baseline algorithms and two commercial off-the-shelf solutions in real-world on-the-edge settings.
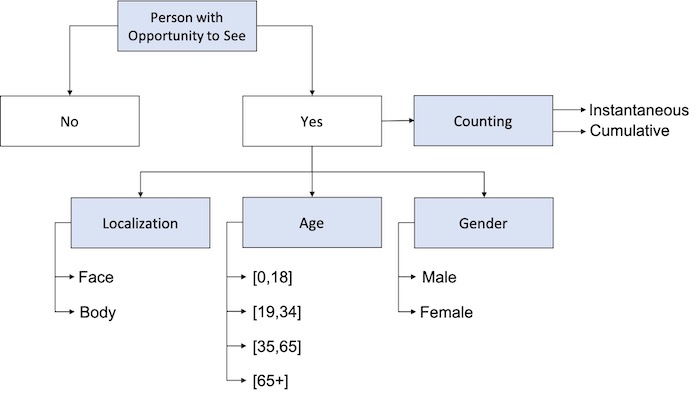
The benchmark considers localization, count, age, and gender as attributes for the analytics. The taxonomy is depicted in the figure below. AVA algorithms should ensure the preservation of the privacy of audience members by performing inferences and aggregating them directly on edge systems, without recording or streaming raw data.
A person has Opportunity to See (OTS) the signage when their face is visible from the left profile to the right profile, and the person is not heading opposite to the location of the camera, as shown in the figure below. We consider only the attributes of people with OTS.

The dataset was collected in settings that mimic real-world signage-camera setups used for AVA, and it is composed of 16 videos recorded at different locations such as airports, malls, subway stations, and pedestrian areas. Outdoor videos are recorded at different times of the day such as morning, afternoon, and evening. The dataset is recorded with Internet Protocol or USB fixed cameras with wide and narrow lenses to mimic the real-world use cases. Videos are recorded at 1920x1080 resolution and 30fps. The dataset includes videos of duration between 2 minutes and 30 seconds, and 6 minutes and 26 seconds, totaling over 78 minutes, with over 141,000 frames. The videos feature 34 professional actors. A sample frame of each location is shown below. For the mall location, two videos are at different times: indoors (Mall-1/2) and outdoors (Mall-3/4).
| Airport-1 | Airport-2 | Airport-3 | Airport-4 |
|---|---|---|---|
 |
 |
 |
 |
| Mall-1/2 | Mall-3/4 | Pedestrian-1 | Pedestrian-2 |
 |
 |
 |
 |
| Pedestrian-3 | Pedestrian-4 | Pedestrian-5 | Subway-1 |
 |
 |
 |
 |
| Subway-2 | Subway-3 | ||
 |
 |
The algorithms have been tested on Ubuntu 16.04 and MacOS 10.15.6 with the libraries on the version requested in requirements.txt and with OpenVINO 2020.1. The installation instructions below are for Intel/AMD based systems.
The creation of a single conda environment suffices for running all baseline algorithms and evaluation codes present in the repository.
-
(Optional) Install OpenVINO 2020.1 link. This is only required if CPU OpenVINO optimization is wanted.
-
Download and uncompress AVA dataset [1.31 GB]
wget http://ava.eecs.qmul.ac.uk/resources/AVA_dataset.zip
unzip AVA_dataset.zip
-
Install miniconda: link
-
Create conda environment with Python 3.7
conda create -n AVA python=3.7
- Activate AVA conda environment:
source activate AVA
- Clone the AVA repository
git clone https://github.com/QMUL/AVA.git
- Install requirements
pip install -r requirements.txt
- Download the desired model weigths, for all algorithms
bash get_all_weights.sh
The algorithms have also been tested in NVIDIA Jetson Nano. Follow the below resources to:
- Setup NVIDIA Jetson Nano. Steps 8/9 are specially useful for setting up a virtual environment.
- Install PyTorch
- Authors: Ricardo Sanchez-Matilla and Andrea Cavallaro
- Created date: 21/09/2020
- Version: 0.1
- Resource type: software
This work is licensed under the Creative Commons Attribution-NonCommercial 4.0 International License. To view a copy of this license, visit http://creativecommons.org/licenses/by-nc/4.0/ or send a letter to Creative Commons, PO Box 1866, Mountain View, CA 94042, USA.