BERT 的全称是基于 Transformer 的双向编码器表征,其中「双向」表示模型在处理某一个词时,它能同时利用前面的词和后面的词两部分信息。这种「双向」的来源在于 BERT 与传统语言模型不同,它不是在给定所有前面词的条件下预测最可能的当前词,而是随机遮掩一些词,并利用所有没被遮掩的词进行预测。 因此BERT的任务主要有以下两个:
- 二分类任务:在数据集中抽取两个句子A和B,B有50%的概率是A的下一句,这样通过判断B是否是A的下一句来判断BERT模型
- Mask预测任务:传统语言模型是给定所有前面词来预测最可能的当前词,而BERT模型则是随机的使用「mask」来掩盖一些词,并利用所有没有被掩盖的词对这些词进行预测。论文中是随机mask掉15%的词,并且在确定需要mask的词后,80%的情况会使用「mask」来掩盖,10%的情况会使用随机词来替换,10%的情况会保留原词,例如:
- 原句:xx xx xx xx hello
- 80%:xx xx xx xx 「mask」
- 10%:xx xx xx xx world
- 10%:xx xx xx xx hello
预训练的流程如下图:
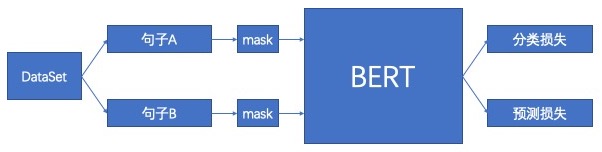
Bert4Rec时基于以上,将bert应用到推荐系统:
原文链接:BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer
参考链接:https://aistudio.baidu.com/aistudio/projectdetail/122282?channelType=0&channel=0
|-- bert4rec # 用于存放model文件
|-- |-- dataset.py # 使用bert模型进行分类任务的模型
|-- |-- bert4rec.py # bert模型 paddle2.0修改
|-- |-- transformer_encoder20.py # transformer模型的encoder部分,bert是基于该网络进行的 paddle2.0修改
|-- trainrec.py # bert4rec模型的训练脚本
|-- train.sh # 训练脚本
|-- bert_train
|-- |-- gen_data_fin.py # 数据预处理,将原始数据处理为飞桨模型读取的数据
|-- |-- bert_config_ml-1m_256.json # 配置文件
处理原始数据,生成ml-1m-train.txt ml-1m-test.txt
!cd ./bert_train/ && python gen_data_fin.py
模型结构:
"attention_probs_dropout_prob":float0.2
"hidden_act":string"gelu"
"hidden_dropout_prob":float0.5
"hidden_size":int256
"initializer_range":float0.02
"intermediate_size":int1024
"max_position_embeddings":int200
"num_attention_heads":int8
"num_hidden_layers":int2
"type_vocab_size":int2
"vocab_size":int3420
train.sh 超参设置
--BATCH_SIZE=256
--WARMUP_STEPS=200
--LR_RATE=1e-3 # 原文的lr为 1e-4, 这里设置为1e-3发现模型能够更快收敛,且top-10 精度超过原文很多
--WEIGHT_DECAY=0.01
--MAX_LEN=200
--TRAIN_DATA_DIR=bert_train/data/ml-1m-test.txt
--VALIDATION_DATA_DIR=bert_train/data/ml-1m-test.txt
--CONFIG_PATH=bert_train/bert_config_ml-1m_256.json
--VOCAB_PATH=data/demo_config/vocab.txt
开启训练:
!chmod +x train.sh
!./train.sh -local y
使用ml-1m数据进行复现,调整初始lr为1e-3,训练150个epoch后, ml-1m HR@10=0.98
