Fix getDefinition not working for modified/new procedures #4798
Conversation
tests/mocha/procedures_test.js
Outdated
| delete Blockly.Blocks['nested_proc']; | ||
| }); | ||
|
|
||
| test('New definition', function() { |
There was a problem hiding this comment.
Nit: Could you make this name more descriptive e.g. "Custom procedure block" or "non-built-in procedure block"?
|
Two comments:
|
I guess you could think about it as hoisting yeah! As you know, Blockly has no concept of scope/everything is global scope. So even when outside devs add top and bottom connections to the procedures (so that they can be defined in some nested place) Blockly still treats those procedures as having global scope (ie you can call them from anywhere). But this is fine because when the text-code is generated, the procedures will be globally scoped, so no errors occur and it's not a problem. In my mind, it's all internally consistent (and consistent with the history of not providing scoping) so it shouldn't cause any problems. Wrt scoping: I think that merging this does support the idea that if scoping were to be added it should support nested function scoping and hoisting appropriately. But in my opinion, that's just something that Blockly should support, because it's something text-based languages support. Trying to avoid properly handling those future cases by not allowing the current non-scoped function blocks to be nested doesn't seem like the way to go.
Will do o7 |
|
Ok I think I've got the interface added! Please check over it to make sure it's in the right form. I'm also not sure if it needs to be |
core/interfaces/i_procedure_block.js
Outdated
|
|
||
| 'use strict'; | ||
|
|
||
| goog.provide('Blockly.Procedures.ProcedureBlock'); |
There was a problem hiding this comment.
Make this interface Blockly.IProcedureBlock instead--that way it's not adding something onto a namespace that's defined somewhere else.
If we need to keep the Blockly.Procedures.ProcedureBlock typedef around you can do a typedef in procedures.js, where it was previously, to make it equal to IProcedureBlock.
An interface needs to be required if there is code that is implementing it (@implements), but otherwise can just be used with requireType.
|
Ok so I renamed the new interface, and added the old type def back in (if that's not what I was supposed to do just tell me haha). But looking at it, I'm wondering if both are actually wrong. Both "types" contain |
|
I think you're correct about actually needing two interfaces, and now I'm wondering how helpful an interface is here (over a typedef) given that in any case it's instantiated as a block, with no regard for annotations. I'll file an issue to discuss that. Can you go back to the code that Maribeth originally LGTMed? Sorry for the churn. |
Hehe no problem, this has actually been a nice break from getting generic parameters to type check properly :D I think I reverted everything properly, but tell me if I didn't! |
|
I have a feeling that this is not going to really make the folks that add add top and bottom connections to the procedure blocks happy. Presumably, they are doing so in order to support nested definitions with local scope, since that's how most languages treat nested definitions. Consequently, I suspect that this will end up just causing confusion. Just my two cents. -Mark
|
I see where you're coming from. This PR doesn't address creating locally scoped procedures (on its own), which is probably what most people want. And I can see how allowing this, but "hoisting" the functions to the global scope could create confusion. But despite that, I still feel like it should go in, because this behavior is a prerequisite for creating those locally scoped procedures. If we make sure that getDefinition works with modified and new procedure blocks, then people can build on that to create scoping rules, or a scoping plugin. For example, they could disable procedure call blocks that aren't within the same scope as their definition. If we do not make sure that getDefinition works properly for modified procedure blocks, then there is no possibility for scoping at all. So even if this PR does not solve the major problem, I still think it's a good step towards an "ideal" model of procedures (which do support different levels of nesting and hoisting). How do you feel about this? Also, I'd like to stay that I do feel your point about this behavior being confusing. Perhaps there should be a page somewhere that describes how scoping in Blockly works. I feel like this is confusing for both variables and procedures, which is why I think a document somewhere might help. But maybe that's not necessary, or there's a different way to approach it. Do you have any thoughts on the communication? |
|
I would lean toward waiting until someone can create a more consistent PR which enabled the top and bottom connections and also supported nested procedures in some form. That said, I endorse your idea for some additional documentation about Blockly scoping. I think that developers sorta know that Blockly only supports global scope, but I think that they don't quite understand how deeply engrained that support is. |
Cleaning up procedures is (currently) an "iceboxed" project--that is, we agree that it's interesting and useful, but it's not on my list of projects for the team in the next ~year, unless something changes priorities significantly. That said, I'm happy to discuss what this could look like. Getting more details on a project lets us nibble at the edges, and eventually the problems become tractable. I think there are two ways to approach this, both of which involve the developer tossing out the default procedure definition blocks and creating their own. They might also need to toss out the generator. Route 1: explicit procedure definitionsAs I see it one of the big problems with procedures is that there's no stored list of procedures--instead we inspect the workspace to build the list every time we need to reference procedures. This, combined with in-place editing of procedure definition blocks (e.g. updating parameter names as the user types) makes state management really tricky, and also makes serialization/deserialization kind of a pain. This contrasts with variables, where there's a stored list of variable objects, each of which contains some extra information. They are serialized in a These definitions could then include explicit scope information, which would be used both by the blocks and by the generator. The big question for this route is, how do we store the scope information? Route 2: Dynamic scope based on block stack inspectionThe other way to do this is to have every procedure block look through the block stack to figure out what other procedures are in scope, and disable (or something) when a procedure isn't in scope. The block code and generator code would have to look these up dynamically at every change/every code generation, to make sure that the workspace is still valid. Each block would have to have enough information stored on the block (and serialized) to make sure that this lookup works. The big question for this route is, what is the lookup algorithm for checking if a procedure is in scope? Other considerationsIn both cases, a big question is what you do with calls to functions that are out of scope. This is more of a philosophical question, but it has to guide this work.
|
|
I think the question is bigger than how procedure scoping is handled. I think that if you tackle scoping, you need to tackle scoping for identifiers in general. This includes identifiers for variables, procedures, types, classes, etc. And I think it also includes situtation like:
It seems like to get all of this variable behavior within one system, you'd need to do some sort of dynamic inspection of the workspace. I think that App Inventor's system is a good example of some of this behavior (although the code is tricky to read, and not very generalized). If you were to implement a dynamic inspection system, I think you could do it entirely with plugins (and maybe you could with an explicit def system as well). The block definitions would need to have methods so that they could provide info about what names they provide, and where they are scoped. Something like Then the effects (eg disabling or disconnecting) could be handled by (a) an event listener or (b) a connection checker. I don't think core would need to be modified to support the connection checker. You could probably implement it as a decorator pattern. The outer layer would be the connection checker that handles the scoping, and then you would parameterize that object with another connection checker (default, nominal, strict, etc) that handles the typing. This doesn't address issues with loading the workspace though. Does that desired behavior seem to broad? I'm kind of of the opinion that blockly should be able to do whatever text-based languages do. So I lean towards really general solutions haha. |
|
I think that @BeksOmega is pretty much right on this. I haven't though it through, but I think that if core provided the block-->identifier map perhaps plugins could then provide specific scope implementations. I'll also point out that some languages also have a notion of namespaces which affect which IDs can be used where (e.g. C++ namespace, JavaScript module import, Java packages). Some languages also have implicit namespaces where, for example, functions and variables are in different namespaces and therefore a variable can have the same name as a function, but refer to different things. I've been thinking about all these issues for a while because I have a project in mind to implement a blocks language for Scheme. This presents a number of challenges. Scoping, of course, is one of them, but so is the namespace issue. Core Blockly for example, assumes multiple namespaces so you can have something like the following:
In Scheme, though, there is only one namespace. That makes the default Blockly Toolbox problematic, since you can redefine even the primitive (i.e. toolbox) procedures so, for example they change their arity or even there procedure-ness! Moreover, you need to have a way to choose between the block representing the procedure call versus the block representing the variable value. |
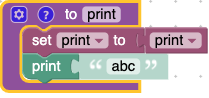
|
Could you solve the namespace issue by prefixing the different spaces in the generated code? Eg: (define (proc-print)
(let ((var-print 'abc))
(print var-print)))Forgive me if my scheme is incorrect - it's been a while haha. |
I believe that the Blockly core actually does what you describe, @BeksOmega. My point was really just to demonstrate that Blockly more-or-less considers variables, procedures and built-ins to be in separate namespaces. But what if you don't want that behavior? In my Blockly version of Scheme I wouldn't want it. The idea of a single namespace is core to Scheme and I wouldn't want to obscure it. |
|
If we assume that getting scoping right requires dynamic inspection of the workspace (and I think it does) and we set aside UI issues, the key idea here (that Blockly is missing for variables) is declaration. If that's the case, then it's actually possible to do scoped procedure calls now, because procedures (unlike variables) do actually have explicit definition blocks. It is perhaps not neat, and procedures cannot have local variables--but limiting where you can call a procedure is actually just fine, if you use procedure blocks with previous and next connections. As Beka said, the rest can mostly be done with the connection checker. We would need to introduce the concept of declaration for variables, such that a variable model includes a pointer to the block that declares it, which is allowed to be any type of block at all. I think with just that addition to core you could also get scoped variables for everything but let bindings. I'm not super familiar with Scheme, so I'll need to do a bit of catching up on the namespaces question. And point taken that this is about namespaces generally, and Scheme is just one example. |
Scheme happens to be my pet language, but in this regard it is actually quite similar to the situation with JavaScript, where functions and variables are in the same namespace and you can redefine standard (or other) functions with simple assignment. Blockly currently hides that from you by renaming things under the covers, but imagine that you wanted to provide a version of Blockly for JavaScript which was true to "real" JavaScript. Interesting questions arise as to:
FWIW, Snap! (Berkeley's Scheme+Scratch mashup) blocks language) has some answers to these questions, though I'm not sure that I really like them. Obviously, we are getting a bit far afield from the original issue. Sorry if I've drawn this all out too long. |
The basics
The details
Resolves
N/A but two forum posts:
Proposed Changes
Changes that getDefinition function so that it doesn't require procedures to be top blocks.
Reason for Changes
Not all procedures will be top blocks. Lots of languages (javascript included) support nested functions. No reason blocks languages shouldn't support them as well :D (besides Blockly's lack of scoping support).
Test Coverage
A test for procedures with previous and next connections.
A test for a procedure with a different block type name than the normal ones, to make sure no one tries to rely on that in the future.
I also tried to replicate the issue from the second forum post, and I could not get it to reproduce.
Tested on: