Description
Related: (#804)
In the BVH code, the leaf nodes aren't placed in an AABB containing just one object when object_span==2. For the case of ray-sphere intersection, not placing the leaf nodes in AABBs improves performance slightly but, for more complicated ray-intersection tests, the AABB rejection can be very useful.
*Note: In the figures below, BVH nodes perform the hit test with AABB and objects perform arbitrary hit tests.
Before:
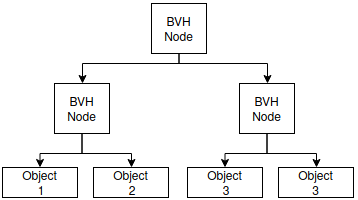
After:
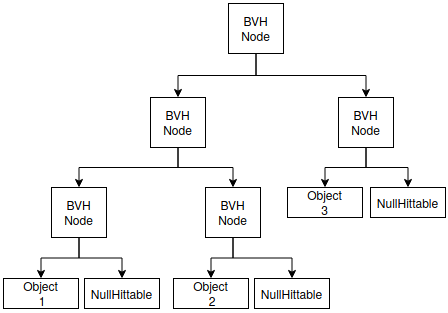
Proposal to change this section of code in BVHNode constructor:
if (object_span == 1) {
left = objects[start];
right = dummy;
left->bounding_box(box);
return;
}
// else if (object_span == 2) {
// if (comparator(objects[start], objects[start+1])) {
// left = objects[start];
// right = objects[start+1];
// } else {
// left = objects[start+1];
// right = objects[start];
// }
// }Add this class to Hittable.h (Null object pattern)
class NullHittable : public Hittable
{
public:
virtual bool hit(const Ray& /*ray*/, double /*min_ray_length*/, double /*max_ray_length*/, HitRecord& /*hit_rec*/) const override {return false;}
virtual void bounding_box(AABB& output_box) const override {output_box = AABB();}
};I make the dummy a static const member of the BVH Node class to make sure only one dummy exists and cannot be changed.
static const std::shared_ptr<Hittable> dummy; and then in the BVHNode.cpp I add to initialise it:
const std::shared_ptr<Hittable> BVHNode::dummy = std::make_shared<NullHittable>();This solution is cleaner and faster than performing the bounding_box collision test in, for example the Sphere::hit function, as each Hittable::hit child would be responsible to perform its own coarse collision first (error prone and code duplication).
Secondly, the left->hit right->hit code can be left in tact with no conditionals and the dummy just returns false instead of performing the collision test on the same object twice, which depending on the complexity of the object can be slow. I agree with @trevordblack (#804) that branch code should be avoided but not that this is a non-issue, from my tests with optimisations turned on -O3 and a pseudo complex hit test. Return value caching would add more complexity than this approach and may lead to bugs and would be slower.
Additionally, is the sorting even necessary in the case (object_span == 2) since right->hit is always called after left->hit.
If you would like, I could create a pull request for this according to book's code style? My current implementation differs from that in the book and would need to be modified to fit the book's style.