fixing "invalid permission" segfault from #5077 by only starting the amount of thread, memory was allocated for. #5087
Conversation
…rting the amount of thread, memory was allocated for. L717-L718 allocated memory for a batch-throttled number of threads in the TMP buffer, but L1235-L1238 started an unthrottled number of threads, causing the segfault at L995 for threads over the throttled threshold.
|
Thanks for all this great detail. LOL at the last sentence. The comments in I'm thinking it's the |
|
This I was thinking that all Maybe the problem in general is that we call |
I mean, from what I've seen, it looks pretty unlikely to me to end up with a dataset fulfilling all the requirement to hit this error. And there is a saying where I'm from, that when you manage to do something very unlikely by pure chance, than you have enough luck to gamble or more specifically to play the lottery (even though mathematically this would make no sense). But that's besides the point :)
To be honest, I'm not completely sure which would be the correct value in either place. The code is quite hard to read, and it took me a good week to understand it enough to find this error. Also throttling the parallel region, to fix the problem, seamed least intrusive to me, as throttling seamed to be applied for a good reason in the first place.
Fair enough, allocating the upper bound of what could possibly be used will definitely also solve the problem. It looks like, the overhead would be about 256kB per additional thread, which is arguably not optimal but probably also not too bad.
I agree, that it would probably be best to reuse the value where possible and not calculate it again to prevent mismatching option and therefore calculations. I will take a look at that. Maybe using the minimum of |
|
Okay so I traced back the values and found, that
now for the first call of
And for the yellow box
While during allocation of
So it looks like usually one more thread is started than memory was allocated for. So when the additional conditions to reach L995 are met, the buffer overflow occurs. It also looks like this global |
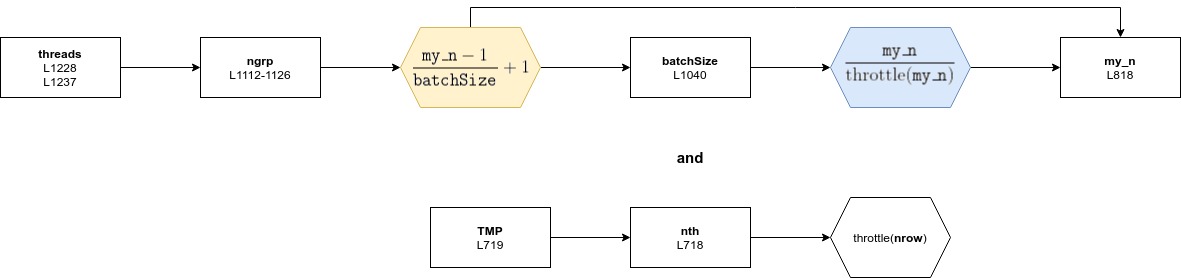
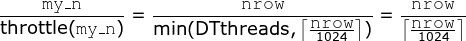
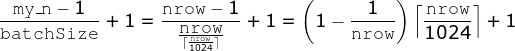
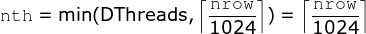
…t start too many threads where the buffer might be used. Also renaming the global TMP as such. see Rdatatable#5077 and Rdatatable#5087
|
Have invited you to be project member so among other things you can create branches in the main project in future. The invite should be a button you need to click to accept in GitHub in either your projects or profile page. Have also added you to the contributors list. Thanks again! |
remove reference to radix_r as users won't know what that internal function is for consistency with other news items: just link to issue (those interested can get to the PR from the issue) just your name in news item. folk can get to your profile by clicking the link to the issue
…es are static global in this file (shared between functions just in this file) so adding a prefix to just one is inconsistent
src/forder.c
Outdated
| // all groups are <=65535 and radix_r() will handle each one single-threaded. Therefore, this time | ||
| // it does make sense to start a parallel team and there will be no nestedness here either. | ||
|
|
||
| int threads_to_run = MIN(nth, getDTthreads(ngrp, false)); // the parallel regions below might reach code |
There was a problem hiding this comment.
Calling getDTthreads() again here still leaves the same door open that this value of throttle needs to be the same as the value used to allocate on line 718. We can use nth on the #pragma line, avoid the new variable, avoid the extra call to getDTthreads() and reduce from 3 places to 2 places. Will do...
There was a problem hiding this comment.
I don't think calling it again here with the MIN limiting it to the value of nth is necessarily the same problem. But thinking about it again and seeing the last commits you added, I'd say it was redundant, as getDTthreads w/ throttle=false, basically only limits to the number of configured threads, which is already done w/ nth. So if configured threads are the limiting factor, this already resembled in nth so there is no need to apply it again to ngrp as it can then only play a role here if ngrp < threads, but then also ngrp < nth would be true. So doing like you did with MIN(nth, grp) is more efficient as it saves the function call.
src/forder.c
Outdated
| static int **gs_thread=NULL; // each thread has a private buffer which gets flushed to the final gs appropriately | ||
| static int *gs_thread_alloc=NULL; | ||
| static int *gs_thread_n=NULL; | ||
| static int *global_TMP=NULL; // UINT16_MAX*sizeof(int) for each thread; used by counting sort in radix_r() |
There was a problem hiding this comment.
I renamed the variable, because it made it easier to distinguish from the other block-local TMP(s?) during debugging. But yes, for consistency I probably should have named it back, after I was done.
NEWS.md
Outdated
| 28. `dplyr::arrange(DT)` uses `vctrs::vec_slice` which retains `data.table`'s class but uses C to bypass `[` method dispatch and does not adjust `data.table`'s attributes containing the index row numbers, [#5042](https://github.com/Rdatatable/data.table/issues/5042). `data.table`'s long-standing `.internal.selfref` mechanism to detect such operations by other packages was not being checked by `data.table` when using indexes, causing `data.table` filters and joins to use invalid indexes and return incorrect results after a `dplyr::arrange(DT)`. Thanks to @Waldi73 for reporting; @avimallu, @tlapak, @MichaelChirico, @jangorecki and @hadley for investigating and suggestions; and @mattdowle for the PR. The intended way to use `data.table` is `data.table::setkey(DT, col1, col2, ...)` which reorders `DT` by reference in parallel, sets the primary key for automatic use by subsequent `data.table` queries, and permits rowname-like usage such as `DT["foo",]` which returns the now-contiguous-in-memory block of rows where the first column of `DT`'s key contains `"foo"`. Multi-column-rownames (i.e. a primary key of more than one column) can be looked up using `DT[.("foo",20210728L), ]`. Using `==` in `i` is also optimized to use the key or indices, if you prefer using column names explicitly and `==`. An alternative to `setkey(DT)` is returning a new ordered result using `DT[order(col1, col2, ...), ]`. | ||
|
|
||
| 29. A segfault could occur when grouping or sorting in some circumstances with a large number of threads such as 80, [#5077](https://github.com/Rdatatable/data.table/issues/5077). Thanks to Bennet Becker for reporting, debugging at C level, and fixing. | ||
| 29. A segfault could occur when grouping or sorting in some circumstances with a large number of threads such as 80 on a server with 256 logical cores, [#5077](https://github.com/Rdatatable/data.table/issues/5077). Thanks to Bennet Becker for reporting, debugging at C level, and fixing. |
There was a problem hiding this comment.
When mentioning the processor used, I think it would be better to use 128 threads as the example, as this would be the default value on such a machine. The other values mentioned (such as 80 or 96) were manually configured to initially find the error threshold. And I don't know how common it is for people to manually set the amount of threads to be used.
There was a problem hiding this comment.
Thanks, I see. I'm going to try and create a test which reliably fails under ASAN (the commands are in CRAN_Release.cmd). I suspect it's not failing very often currently because there's space after the end of TMP within the last page that's effectively ok to write to (or something like that). Turning on ASAN should trap that in more cases given a suitable test. I never like using the words "in some circumstances" in the news items because I sense the reader thinking "well, what circumstances, and might my circumstances be affected?". So once the test is ready I'll go back and replace that phrase and the number of threads and cores with more detail.
There was a problem hiding this comment.
Yes with ASAN it should not be too hard to find a reliably failing example. The examples I have on my work PC might even produce the error with this, but I will not be able to access them until tomorrow noon (CEST time). But I think even this example required at least 6 threads or something like that, and I don't know what is possible in the test environment or what the limits are.
And I wouldn't call it "effectively ok to write to" but "possible to write to, without the environment noticing", as buffer overflows are always inherently problematic, as it may overwrites other data for other program parts or the overflown data is unexpectedly overwritten by other parts of the program, especially if the data is small enough for heap allocation to occur.
There was a problem hiding this comment.
Yes that is better wording. I do know that.
There was a problem hiding this comment.
This is enough to segfault and doesn't need ASAN:
DT = data.table(grp=sample(65536)) # >=65536 necessary
setDTthreads(throttle=nrow(DT)) # increase throttle to reduce threads to 1 for this nrow
DT[, .N, by=grp] # segfault
setkey(DT, grp) # segfault
There was a problem hiding this comment.
Oh ok, I didn't know (or find) the throttle value is adjustable like this. I tried to find an example with the default 1024 value, which made it much harder, to find a small example that would even remotely reach the protected page.
Closes #5077
After first finding that the allocated amount of memory for the
TMPbuffer seamed too low,0x13c0000vs80*UINT_16_MAX*sizeof(int) = 0x13ffec0and was followed by a protected 0-page withsetDTthreads(threads = 80), it turned out that in L717-L718 the allocated memory was actually only79*UINT_16_MAX*sizeof(int) = 0x13bfec4, becausegetDTthreadswas called withthrottle = true.But later when starting the parallel threads, in L1235-L1238 the number of threads to start was determined with
throttle = false, causing the segfault at L995 for threads over the throttled threshold, while trying to access memory past theTMPbuffer.Starting only the throttled amount of threads, fixes that. This also seamed fixed the random
double free or corruptionerrors as they are currently not occurring anymore for 80 threads like before.Unfortunately, it seems to be quite difficult to find a reasonably small dataset and requirement in thread count to write a test for, as quite some things need to happen, that this error occurs. The requirement I currently found are
R_DATATABLE_THROTTLE)), that less memory is allocated than usedmalloc()in L718 will internally usemmap()instead of the defaultbrk()/sbrk()so that the protected page is not moved by new heap allocationsIn other words it seems to be a very specific edge case and the scientist that created the dataset that causes the crash, should maybe start to gamble :)