PyTorch implementation of SimCLR: A Simple Framework for Contrastive Learning of Visual Representations by T. Chen et al. Including support for:
- Distributed data parallel training
- Global batch normalization
- LARS (Layer-wise Adaptive Rate Scaling) optimizer.
Open SimCLR in Google Colab Notebook (with TPU support)
Open SimCLR results comparison on tensorboard.dev:
![]()
This downloads a pre-trained model and trains the linear classifier, which should receive an accuracy of ±82.9% on the STL-10 test set.
git clone https://github.com/spijkervet/SimCLR.git && cd SimCLR
wget https://github.com/Spijkervet/SimCLR/releases/download/1.2/checkpoint_100.tar
sh setup.sh || python3 -m pip install -r requirements.txt || exit 1
conda activate simclr
python linear_evaluation.py --dataset=STL10 --model_path=. --epoch_num=100 --resnet resnet50
wget https://github.com/Spijkervet/SimCLR/releases/download/1.1/checkpoint_100.tar -O checkpoint_100.tar
python linear_evaluation.py --model_path=. --epoch_num=100 --resnet=resnet18 --logistic_batch_size=32
SimCLR for PyTorch is now available as a Python package! Simply run and use it in your project:
pip install simclr
You can then simply import SimCLR:
from simclr import SimCLR
encoder = ResNet(...)
projection_dim = 64
n_features = encoder.fc.in_features # get dimensions of last fully-connected layer
model = SimCLR(encoder, projection_dim, n_features)
Simply run the following to pre-train a ResNet encoder using SimCLR on the CIFAR-10 dataset:
python main.py --dataset CIFAR10
With distributed data parallel (DDP) training:
CUDA_VISIBLE_DEVICES=0 python main.py --nodes 2 --nr 0
CUDA_VISIBLE_DEVICES=1 python main.py --nodes 2 --nr 1
CUDA_VISIBLE_DEVICES=2 python main.py --nodes 2 --nr 2
CUDA_VISIBLE_DEVICES=N python main.py --nodes 2 --nr 3
These are the top-1 accuracy of linear classifiers trained on the (frozen) representations learned by SimCLR:
| Method | Batch Size | ResNet | Projection output dimensionality | Epochs | Optimizer | STL-10 | CIFAR-10 |
|---|---|---|---|---|---|---|---|
| SimCLR + Linear eval. | 256 | ResNet50 | 64 | 100 | Adam | 0.829 | 0.833 |
| SimCLR + Linear eval. | 256 | ResNet50 | 64 | 100 | LARS | 0.783 | - |
| SimCLR + Linear eval. | 256 | ResNet18 | 64 | 100 | Adam | 0.765 | - |
| SimCLR + Linear eval. | 256 | ResNet18 | 64 | 40 | Adam | 0.719 | - |
| SimCLR + Linear eval. | 512 | ResNet18 | 64 | 40 | Adam | 0.71 | - |
| Logistic Regression | - | - | - | 40 | Adam | 0.358 | 0.389 |
| ResNet (batch_size, epochs) | Optimizer | STL-10 Top-1 |
|---|---|---|
| ResNet50 (256, 100) | Adam | 0.829 |
| ResNet18 (256, 100) | Adam | 0.765 |
| ResNet18 (256, 40) | Adam | 0.719 |
python linear_evaluation.py --model_path=. --epoch_num=100
The LARS optimizer is implemented in modules/lars.py. It can be activated by adjusting the config/config.yaml optimizer setting to: optimizer: "LARS". It is still experimental and has not been thoroughly tested.
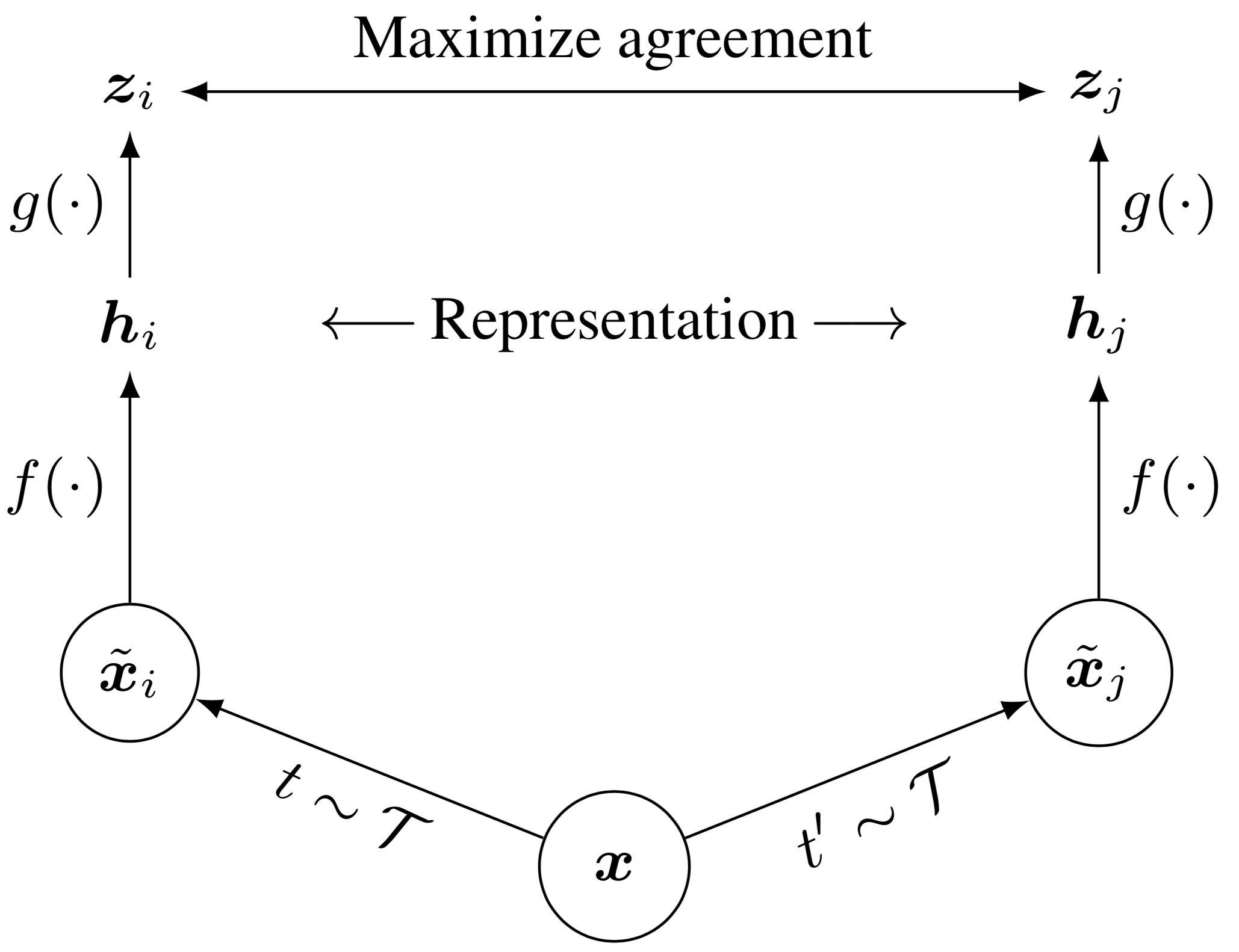
SimCLR is a "simple framework for contrastive learning of visual representations". The contrastive prediction task is defined on pairs of augmented examples, resulting in 2N examples per minibatch. Two augmented versions of an image are considered as a correlated, "positive" pair (x_i and x_j). The remaining 2(N - 1) augmented examples are considered negative examples. The contrastive prediction task aims to identify x_j in the set of negative examples for a given x_i.
Run the following command to setup a conda environment:
sh setup.sh
conda activate simclr
Or alternatively with pip:
pip install -r requirements.txt
Then, simply run for single GPU or CPU training:
python main.py
For distributed training (DDP), use for every process in nodes, in which N is the GPU number you would like to dedicate the process to:
CUDA_VISIBLE_DEVICES=0 python main.py --nodes 2 --nr 0
CUDA_VISIBLE_DEVICES=1 python main.py --nodes 2 --nr 1
CUDA_VISIBLE_DEVICES=2 python main.py --nodes 2 --nr 2
CUDA_VISIBLE_DEVICES=N python main.py --nodes 2 --nr 3
--nr corresponds to the process number of the N nodes we make available for training.
To test a trained model, make sure to set the model_path variable in the config/config.yaml to the log ID of the training (e.g. logs/0).
Set the epoch_num to the epoch number you want to load the checkpoints from (e.g. 40).
python linear_evaluation.py
or in place:
python linear_evaluation.py --model_path=./save --epoch_num=40
The configuration of training can be found in: config/config.yaml. I personally prefer to use files instead of long strings of arguments when configuring a run. An example config.yaml file:
# train options
batch_size: 256
workers: 16
start_epoch: 0
epochs: 40
dataset_dir: "./datasets"
# model options
resnet: "resnet18"
normalize: True
projection_dim: 64
# loss options
temperature: 0.5
# reload options
model_path: "logs/0" # set to the directory containing `checkpoint_##.tar`
epoch_num: 40 # set to checkpoint number
# logistic regression options
logistic_batch_size: 256
logistic_epochs: 100
To view results in TensorBoard, run:
tensorboard --logdir runs
This implementation features the Adam optimizer and the LARS optimizer, with the option to decay the learning rate using a cosine decay schedule. The optimizer and weight decay can be configured in the config/config.yaml file.

torch
torchvision
tensorboard
pyyaml