Term: Fall 2016
-
Team Name: Data Kings
-
Team members
- Guanzhong You (gy2224)
- Yinxiang Gao (yg2424)
- Chencheng Jiang (cj2451)
- Wenhang Bao (wb2304)
- Chang Liu (cl3388)
-
Project summary: This project is the last project of Applied Data Science. The objective is to generate a melody with RNN-LSTM model, with or without specifying the starting part of the wanted melody. With this machine, we can produce infinite number of musics. This could be as amazing as afa go if we have high quality music data. (Doubt? After hearing the generated songs you will not!)
-
Data Form:
- ABC notation is our input. It's a shorthand form of musical notation, which uses the letters A through G to represent the given notes, with other elements used to place added value on these - sharp, flat, the length of the note, key, ornamentation. To know more about ABC notation. A typical ABC notation is like:

- ABC notation is our input. It's a shorthand form of musical notation, which uses the letters A through G to represent the given notes, with other elements used to place added value on these - sharp, flat, the length of the note, key, ornamentation. To know more about ABC notation. A typical ABC notation is like:
-
Data Source:
-
Hand-made data: We got the melody data from popiano.org. The raw data is in .ove format, which contains music score information. We first transformed them into MID format, then into ABC notation format.
-
Ripe data: In the website ABC notation, we used R crawler to get the data. In Notingham Music We copied and pasted them together.
-
-
Environment: We use Ubuntu + Python 2.7.12 + Tensorflow to construct and run this model.
-
Model: We used Recurrent Neural Network to generate("predict") the melody. This model was originally used in generating a text that looks like the training data. We import this model in generating music, since they are both sequence and both have "grammer" to some degree. We chose this method also because it creates an internal state of the network. Unlike feedforward neural networks, RNNs can use their internal memory to process arbitrary sequences of inputs. To make this idea work, we still need a text representation of music. And as stated above, the ancient ABC notation greatly help us out! Then we chose the LSTM, one specific kind of recurrent neural network, to train the model because it can well capture the notation dependency. A simple demo is:

-
Model setting and training: We used Long Short-Term Memory (LSTM) RNN model with 2 hidden layers, 128 nodes in each hidden layer, 100 epoch and 50 chars memory. The logistic function as our loss function.

-
Generation: We generated the melody based on a given piece of melody(which could be empty though). Users are also allowed to choose the music style. We offered four chioces: Nottingham, Chinese Pop, Chinese Shange and ACG. Each generator is a RNN-LSTM model trained with the musics from that style. Details is in the ppt file in doc folder. After getting the words result, we use Colin Hume's website to convert to music.

-
Result: The generated music is really amazing. The machine seems neither copy pieces from training data and combine them, nor generate some smooth but random music. Instead, from the behavior, the machine seems to have understood some underlying structure of the music components. Here are some examples we generated. If you want to listen more, please look at the output folder.
-
More Fun Play: To test how the machine work and testify the judgement stated above, we ask the machine to extend a given piece of melody. This piece is taken out from a Chinese folk melody, which is not included in the training dataset. The machine is trained with Nottingham music. So the production should be a hybrid of Chinese folk and Nottingham, which is supposed to be a whole mess. But it turns out not that case!!
- The original Chinese melody from where we take the starter
- Chinese Folk Extended in Nottingham style
- With the same idea, we made a Modified Ode of Joy
-
Visualization:
- We developed a website application for this model. In this website, we trained 4 models with different styles of training data, and the user can choose any style they want to generate. If the starter input is left blank, the machine will composed all on its own.
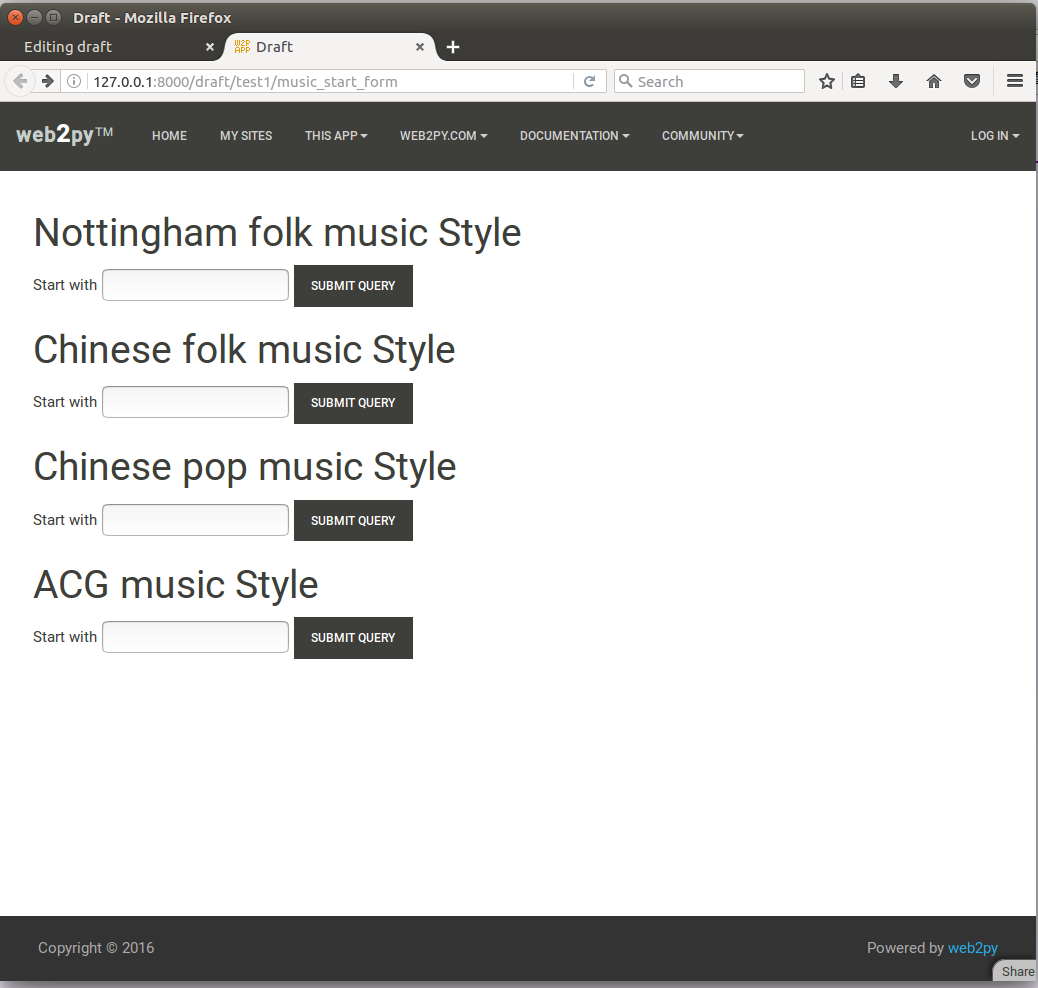
-
Reflection:
- The performance of neural network may highly depends on the data format fed into it, i.e. the features and pattern should be easy to learn by machine. ABC notation from our ancestor happens to meet this condition. For further development, if there comes to be a tidy presentation of multi-track music(in our example, only 1 or 2 tracks), this model could perform in a higher platform.
- The structure (# of layers, # of batchs, # of hidden layer states, etc) design is actually a bias variance trade-off. With more data, one can get a less biased (smarter) neural network by adding more nodes.
- The quality of generated music, in this state now, depends highly on the quality of training data. This model learn from the training data, so it's generated music has a similar style as them. It is a pity that we can’t find the ABC notation of the most popular music, otherwise it could be more fun.
-
Further improvement: In order to predict a more beautiful melody, we could improve by:
- Add more data and styles in the training step, and select better music.
- Adjust the parameter in the training model----with more data we can allow a larger network
- If you are interested now, you may want to glance at what similar things DeepMind has done.
-


Contribution statement: (default) All team members contributed equally in all stages of this project. All team members approve our work presented in this GitHub repository including this contributions statement.
Following suggestions by RICH FITZJOHN (@richfitz). This folder is orgarnized as follows.
proj/
├── lib/
├── data/
├── doc/
├── figs/
└── output/
Please see each subfolder for a README file.