Important
VTok 2.0 is still under development, so bugs are to be expected.
Note
The program has been tested on videos from the YouTube channel VALORANT Daily. Depending on how the videos posted on other channels, the program may or may not work without any further modification.
-
This project has been developed and tested on Ubuntu 22.04 (WSL). A Linux distribution is preferred to run the program. Future updates will include Windows support.
-
An account on Roboflow to use the model for detection of the streamer's camera. Visit app.roboflow.com, go to settings and copy the Private API Key
-
Set the API_KEY environment variable:
export API_KEY=YOUR_ROBOFLOW_API_KEY
- Python 3.9 or greater
-
Clone the repository
git clone https://github.com/Techie-Ernie/vtok2.git
-
Install requirements
cd vtok2 pip install -r requirements.txt -
Run main.py. Further configuration can be done by editing config.ini
python main.py -
The videos will be placed in the videos/ folder as video{x}_final.mp4. The original clips can be found in the vtok2 folder as video{x}.mp4. Will add option to remove these temporary files in a future update.
Tip
You can run the videos produced by the program through autosub to burn subtitles generated by faster-whisper into the video.
- youtube_download.py
- Uses the yt_dlp library to download the video from the YouTube link the user has provided
- scraper.py
- Contains the scrape_stats() function, which uses Selenium to count the number of kills in each round. This returns a dict highlight_rounds, which are the rounds where kills >= MIN_KILLS (as defined in config.ini)
- extract_images.py
- Contains the extract_images() function which takes in the downloaded video and reads the frames using OpenCV, skipping forward by frame_interval (as defined in config.ini) number of frames.
- PaddleOCR is used to read the numbers corresponding to the player's team score and the opponent's score, adding it to score_dict, along with its timestamp. Identical scores and scores which don't make sense (e.g. from 10-7 to 10-6) will not be added.
- score_dict is returned
- This part is still buggy, as contrast between the numbers and the background is sometimes too low and the numbers are inaccurate or not recognised.
- extract_video.py
- convert_rounds() takes in the score_dict from extract_images() and simply iterates through score_dict to replace the key (initially something like '0:0' in score_dict to '1' instead - essentially getting the round number). The new dict returned is round_dict
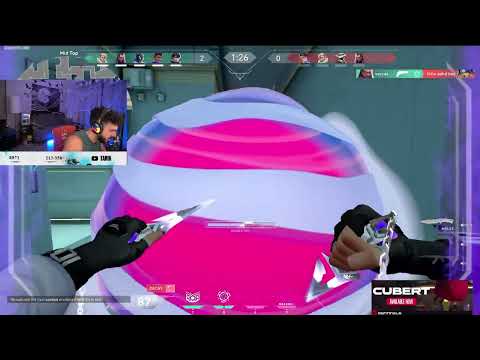
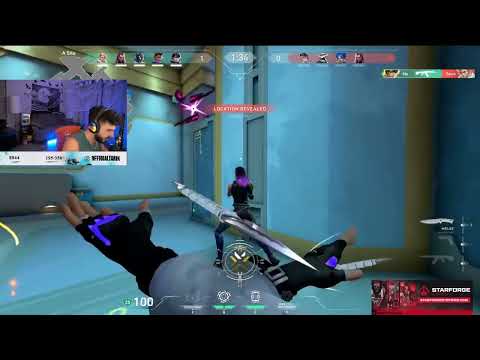
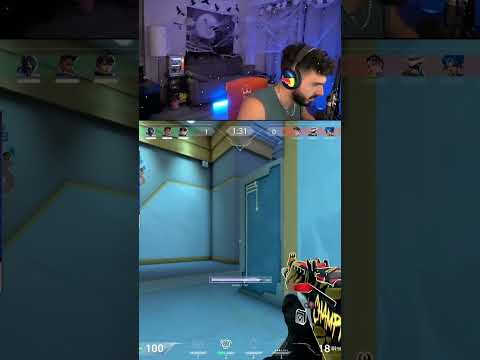
- extract_clip() parses the round_dict and highlight_dict in order to determine the timestamps where there are highlights that need to be extracted. It then uses moviepy to extract a subclip of the original downloaded video and writes the subclip to a file. The result will look like the CLIP_EXTRACTED video at the top of this file.
- edit.py
- edit.py converts the video into a TikTok-friendly format.
- get_predictions() uses a model from Roboflow to detect the streamer's camera in a particular frame of the video. (set to 150th frame - an arbitary number - check predictions_img.png if the function fails - may fix this later)
- The model locates the bounding box of the streamer's camera and these coordinates are sent to the edit_video() function
- edit_video() uses moviepy to create the final TikTok-friendly video by combining the streamer's camera at the top of the video and the gameplay at the bottom.
6.find_match_stats.py
- Finds the link to the match stats on valorant.op.gg by checking the last frames of the downloaded video to find the final match score.
- As many VODs of the games (on YouTube) have the map name in their titles, it checks for that. If not able to find the map name, you will have to key in the name manually.
- Input the Riot ID of the player
- Selenium is used to find the match (searches past 20 matches) : if it can't find the match, you will have to key the link in manually.
- Why use valorant.op.gg and not tracker.gg / blitz.gg?
- Unfortunately, tracker.gg blocks web scrapers and blitz.gg does not provide enough information for the program to extract. While I would have preferred to use tracker.gg for convenience, valorant.op.gg was the only suitable option I found that provided stats which I could scrape with Selenium.
- Why PaddleOCR instead of EasyOCR, pytesseract, etc?
- I've tested with EasyOCR, pytesseract, PaddleOCR, keras-OCR, but PaddleOCR produced the most accurate results. EasyOCR often failed recognising single digits. As mentioned above, the detection is still not perfect and I'll be working on improving it.
- Moviepy is slow
- From testing, moviepy takes rather long (about 5 minutes, not more than 10 minutes) to render a ~1 min video.
- However, I haven't found a way to fix this. Perhaps using the ffmpeg_tools directly in the moviepy library may work better (will try in the future)
- More customisation options in config.ini
- Integrating the original VTOK 1.0 into this new version - will need to update moviepy as well since VTOK 1.0 used moviepy 1.x, which has been updated to 2.x + support for VCT matches (however, vlr.gg and valorant.op.gg don't currently provide the stats I need, and rib.gg has shut down on 1st Dec 2024)
- Better OCR accuracy
- Support for Twitch vods on top of YouTube
Finding the match stats on valorant.op.gg directly from the YouTube videoAdded on 5/12/24