A GUI tool for web-scraping which scrapes the required webpage recursively using CSS Selectors.
Firstly, You must have Python 3.5 or greater available with you. You can download it from here if required.
Next you need pip for Python3, type the following on terminal.
$ sudo apt-get update
$ sudo apt-get install python-pip3
Then, install PyQt5 using the following (Might take some time):
$ sudo pip3 install pyqt5
Finally, install the other dependencies from requirements.txt using the following:
$ cd /path to folder py-scrapper/project
$ sudo pip3 install -r requirements.txt
Firstly to launch the application, do the following
$ cd /path to folder py-scrapper/project
$ python3 gui.py
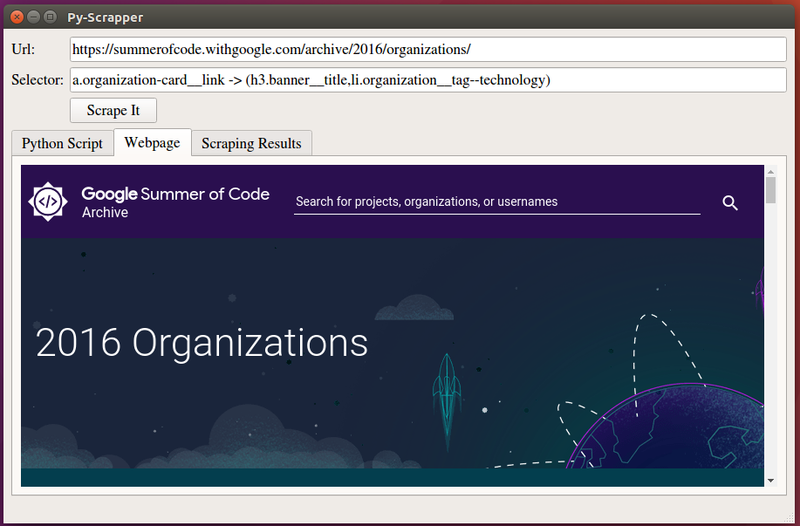
In the Url and Selector Input Boxes, copy the web address of the webpage and the appropriate Selector depending on your scraping requirements. (Check out the preview in the preview section below)
- Supports Recursive Scraping
- Displays the webpage in the GUI itself.
- Also generates python script for required scraping
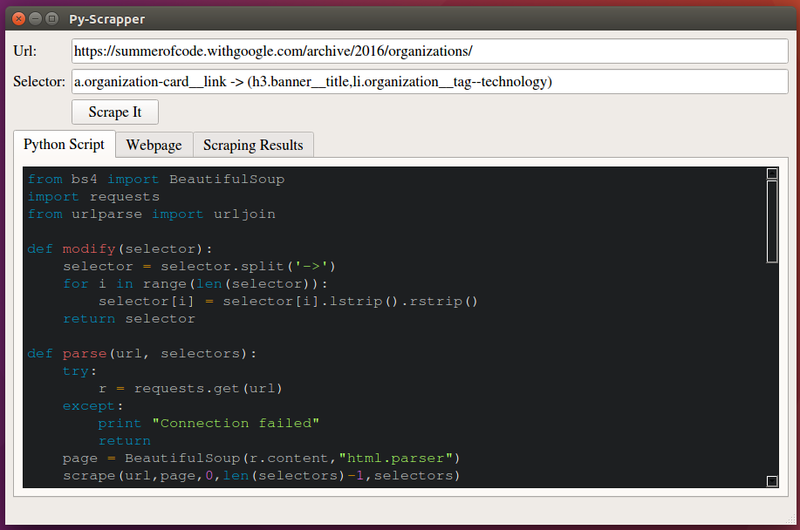

The selector must be a valid CSS Selector. For recursive scraping, use the hierarchical way:
- Use the '->' symbol to separate different elements.
- Wheneven you want some to scrape sibling elements - write them in '()' separating by comma.
Example
-
To scrape the text of the paragraphs with class 'title' and 'description' for all the items of each subcategory and category classed links starting with the url given as input, the selector will look something like as given below:
a.category -> a.subcategory -> div.item -> (p.title, p.description) -
You can also refer to the screenshot above for another example along with the results of scraping.
-
You can also use another way of using nested CSS Selectors by using ">". For example, if you want to scrape the text of a span tag with class "text" inside a div with class "details".
div.details > span.text
NOTE:
- Once installed, you can check out the Help menu for any help.
- Sometimes response is not sent by the webpage which may lead to output of "Connection Refused".
- More Examples will be updated soon.