Examining Jefferson (KY) Census Tracts' Social Vulnerability Through the Lens of the CDC Social Vulnerability Index (SVI)
The CDC SVI refers to social vulnerability as the potential negative effects on communities caused by external stresses on human health, furthermore that by reducing social vulnerability human suffering and economic losses could improve.
What is the CDC Social Vulnerability Index? The CDC SVI is a tool (to help local officials), which uses U.S. Census data (American Community Survey data) to determine the social vulnerability of every census tract. Census Tracts are subdivisions of counties for which the Census collects statistical data. The first version of the SVI was created in 2011 by ATSDR's Geospatial Research, Analysis, and Services Program. GRASP continues to create and maintain the SVI. The most current data is the 2018 SVI data, which was released in March 2020.
The data used here was acquired from the Centers for Disease Control and Prevention/ Agency for Toxic Substances and Disease Registry/ Geospatial Research, Analysis, and Services Program's site, https://www.atsdr.cdc.gov/placeandhealth/svi/data_documentation_download.html. The data selections from this site for this project are as follows:
- Years: 2014, 2016, and 2018
- Geography: Kentucky
- Geography Type: Census Tracts
- File Type: CSV Type The CDC SVI Documentation was also available on the same site page.
Once the data was downloaded to the local HD (Windows 10) the Data and Project-KY folders were created inside Project_KY and were opened with Anaconda/Jupyter Lab, https://docs.anaconda.com/anaconda/install/, with Python3 Programming Language, https://www.python.org/downloads/, and the project's repository is at GitHub, https://desktop.github.com/. You can go to any of these sites to install any of these products.
Pandas and Numpy were installed to read the CSV files and to clean and sort data, for example by using functions like, 'replace', to change incalculable -9.99e+02 with Nan (incalculable for this data because 0 TOTPOP or unavailable values), 'unique', to determine the original unique id when first created (for year 2014 ' Jefferson' was created with a blank space before Jefferson, and it changed in the following years to 'Jefferson', no blank space). This project examines Jefferson Census Tracts' vulnerability numbers, which requires redefining the Kentucky DataFrame to County and selecting Jefferson Census Tracts only. The total population and total square miles were checked against other sources to ensure the proper values were in placed and the 15 vulnerability factors were segregated by their respective themes and examined within 2014, 2016, and 2018 data in preparation for graph visualization.
Some of the libraries and functions used in this project's data visualization (graph):
- %matplotlib notebook
- matplotlib
- get_backend()
- pyplot
NOTES: -inline was used here to work with JupyterLab, if using Jupyter Notebook try %matplotlib notebook -in some instances numpy had to be re-imported
The code for graph visualization was intended to capture the number of factor estimates (i.e., four under theme 1) within their respective themes, (i.e., Socialeconomic theme 1) in 2014, 2016, and 2018 data years, all within one graph. The mean was calculated and used for these graphs.
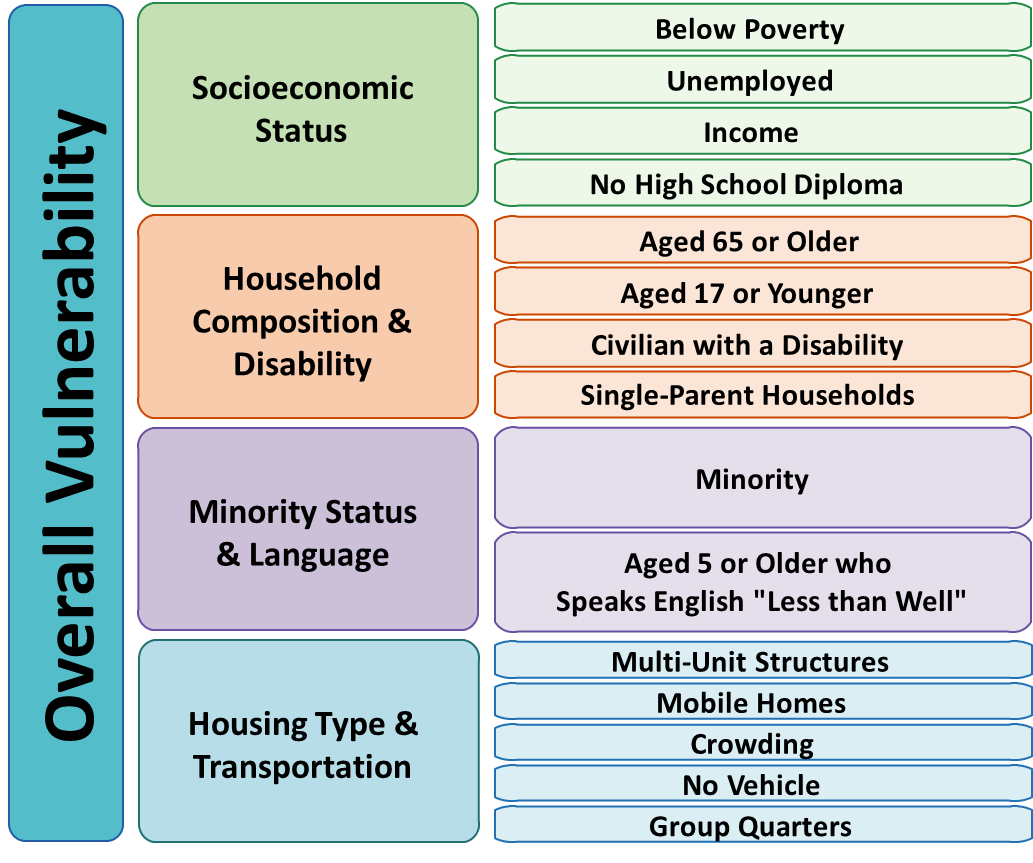
Let's take theme 1, Socialeconomic Status and its four factors; Below Poverty (persons below poverty), Unemployment (age 16+ unemployed), Income (per capita income), and No High School Diploma (age 25+ with no high school diploma). Does the data indicate substantial changes during these periods? Are the changes increases or decreases or no changes? Are the changes material? Will the opinions about this data change once one theme and its factors are compared to other individual themes' numbers, or compared against the overall numbers? Theme 1-Socialeconomic Status' graph shows a consecutive drop of all but income--a consecutive increase around the three years graphed. What does this mean? Some observations could be, the drop in 'no high school diploma' assisted with higher incomes, or higher incomes helped lift unemployment and below poverty numbers, for example.
The same process was applied to theme 2, theme 3, and theme 4, with their respective social factors and overall statements will continue on the conclusion section below.
The model is performed with 2018 data only. The data was again segregated by themes and after modeling the four themes the overall numbers were plotted (i.e., X as the themes as factors and y as the percentile rankings as labels. A percentile ranking represents the proportion of tracts that are equal to or lower than a tract, re: social vulnerability, (i.e., an 0.85's CDC SVI ranking signals that 85% of tracts in KY are less vulnerable than the tract you are examining and that 15% of tracts in KY are more vulnerable.
Some of the libraries and functions used in this project's models (plotting):
- Pandas
- seaborn
- scikit-learn
- model_selection
- train_test_split
- neighbors
- KNeighborsRegressor with n=5
- matplotlib
- cm or colormap
- plotting
- scatter_matrix
After the X=factors and y=labels are defined, X as THEME# and y as RPL_THEME#, the training and test split process follows with its default of 75% training and 25% test. Note: a random_state of zerro (0) was used throughout, on the split.
After the scatter_matrix a KNeighborsRegressor was applied. Note: n_neighbors = 5 was used here but it was also tested with the values of 1, 10, and 20. You may try these versions of the code to test the model. The X_train and y_train were applied to the fit function and a score of 0.86936 was achieved after running the X_test and y_test under the score function.
Two single tracts from the Jefferson data were additionally tested with the prediction function after each theme model.
The final model consisted of all themes as overall vulnerability as the X or factors and y as the overall percentile rankings or RPL_THEMS.
The following links provide access to KY, Jefferson Census Tracts, and other maps:
https://svi.cdc.gov/Documents/CountyMaps/2018/Kentucky/Kentucky2018_Jefferson.pdf
https://svi.cdc.gov/prepared-county-maps.html
What are the observations after examining Jefferson (KY) Census Tracts through the lens of the CDC Social Vulnerability Index and our graphs and models?
The data visualization indicates Socioecomomic Status, theme 1, was the only substantial data change among the four themes. Income increases and decreases on 'no high school diploma' on all three consecutive years could be the high drivers of lower 'unemployment' and 'below poverty' levels. Although something to consider is the total population numbers for those same years:
- 2014: 751,485
- 2016: 759,724 an increase of 8,239 from 2014
- 2018: 767,154 an increase of 7,430 from 2016 A total population increase of 15,669 from 2014 to 2018 survey.
One could suggest an entry to Jefferson Census Tracts averaging higher income earners and/or with higher education levels. Perhaps crediting higher education graduation and technology and trade certification rates could of also contributed to these positive changes (this data does not contain higher education or technology and trade certification data).
Housing Type and Transportation, theme 4. indicates an increase in crowding and a decrease in 'no vehicle'. Which might indicate individuals merging households and sharing resources.
The good news in Household Composition and Disability, theme2, is a reduction on single-parent households. but this might also be part of the crowding increase on theme 4.
Minority Status and Language, theme 3, only offered partially reliable data in that 2014 and 2016 data are equal, which seems unlikely.
The separation by theme number was followed for the models on this project, except that only one year was run, 2018. After the split function on X and y values and the scatter_matrix, the fit (X and y train) in a regression model with n = 5, and score (X and y test) functions provided score 0.8693644598259345, for Socioecomomic Status, theme 1. Just as with the graphs, these models examined the rest of the themes' scores:
- Household Composition and Disability, theme2, score 0.5446
- Minority Status and Language, theme 3, score 0.3993
- Housing Type and Transportation, theme 4, score 0.7077
Two single tracts from the Jefferson data were additionally tested with the prediction function, after each theme number model.
The final model consisted of all themes, overall vulnerability, using the X as all the factors and y as the overall percentile rankings or RPL_THEMES.
- score (X and y test) resulted in 0.8404901315184258 score.
- rpl_themes_prediction using all fifteen factors [303,51,15089,235,25,196,312,329,96,0,0,139,10,9,0] resulted in 0.94632 how good is the prediction?
Our model shows a high score and the prediction grade does too.
To review the significance of this cumulative themes model or overall vulnerability, its data, and the percentile ranking within Kentucky remember that a percentile ranking represents the proportion of tracts that are equal to or lower than a tract on a scale of zero to one, re: social vulnerability, (i.e., an 0.85's CDC SVI ranking signals that 85% of tracts in KY are less vulnerable than the tract you are examining and that 15% of tracts in KY are more vulnerable.
This project could serve as your interactive CDC SVI, as you navigate to the different sites provided in this project, including maps. You could search for your own tract and evaluate the data. You could match other tracts within this county or any other county in Kentucky.
The additional code at the end of the project could also be examined:
Within Jefferson Census Tracts:
| Socioeconomic Status | west9_2018_df | anchorage2018_df |
|---|
- tract FIPS | # 27 21111002700 | # 104.03 21111010403
- Below Poverty | 1252 | 251
- Unemployed | 52 | 156
- Income | 57759 | 15178
- No High School Diploma| 101 | 401
| Household Composition & Disability | west9_2018_df | anchorage2018_df |
|---|
- Aged 65 or Older | 1022 | 230
- Aged 17 or Younger | 775 | 799
- Civilian with a Disability | 455 | 693
- Single-Parent Households | 47 | 289
| Minority Status & Language | west9_2018_df | anchorage2018_df |
|---|
- Minority | 724 | 2011
- Speaks English “Less than Well” | 4 | 81
| Housing Type & Transportation | west9_2018_df | anchorage2018_df |
|---|
- Multi-Unit Structures | 158 | 189
- Mobile Homes | 10 | 7
- Crowding | 11 | 70
- No Vehicle | 50 | 405
- Group Quarters | 151 | 148
Outside of Jefferson Census Tract:
- oldhamco2018_df tract #21185030801 in Oldham Co., 5.381 square miles, population 4589, persons below poverty 86
- martin2018_df tract #21159950100 in Martin Co., 36.306 square miles, population 3723, persons below poverty 1002
The examination of data in this project is only the beginning. Much more can be determined by either exploring clusters of tracts, like the West End and Anchorage are within Jefferson Co., which could tell more about those pockets of data and life realities. In addition, other counties could be added, or the entire state of Kentucky could be examined for a more clear picture of the vulnerability in the state.