-
Notifications
You must be signed in to change notification settings - Fork 2
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
- Loading branch information
Showing
5 changed files
with
391 additions
and
4 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,226 @@ | ||
| ## Java概述 | ||
|
|
||
| 什么是 Java 语言? | ||
|
|
||
| Java 语言的特点? | ||
|
|
||
| JVM、JDK、JRE? | ||
|
|
||
| ## Java基础 | ||
|
|
||
| 1. Java有几种数据类型?分别是哪些? | ||
| 2. 怎么理解`&`和`&&` | ||
| 3. 自增运算是怎么理解的? | ||
| ```java | ||
| int i = 1; | ||
| i = i++; | ||
| System.out.println(i); | ||
| ``` | ||
| ## 面向对象 | ||
|
|
||
| 1. 什么是面向对象?有哪些特性? | ||
| 2. 什么是多态?怎么理解多态? | ||
| 3. `==`与`equals`的区别? | ||
| 4. 重写过`equals`和`hashcode`吗?为什么要重写? | ||
| 5. 解释一下深拷贝和浅拷贝。 | ||
| 6. Java创建对象的几种方式? | ||
| 1. new | ||
| 2. 反射 | ||
| 3. clone | ||
| 4. 序列化 | ||
|
|
||
| ## String | ||
|
|
||
| 1. 说说`String`,是基本数据类型吗? | ||
| 2. String、StringBuffer、StringBuilder有什么区别? | ||
| 3. 了解`intern`方法吗? | ||
|
|
||
| ## Integer | ||
|
|
||
| 1. String怎么转Integer?原理? | ||
| 1. | ||
|
|
||
| ## Object | ||
|
|
||
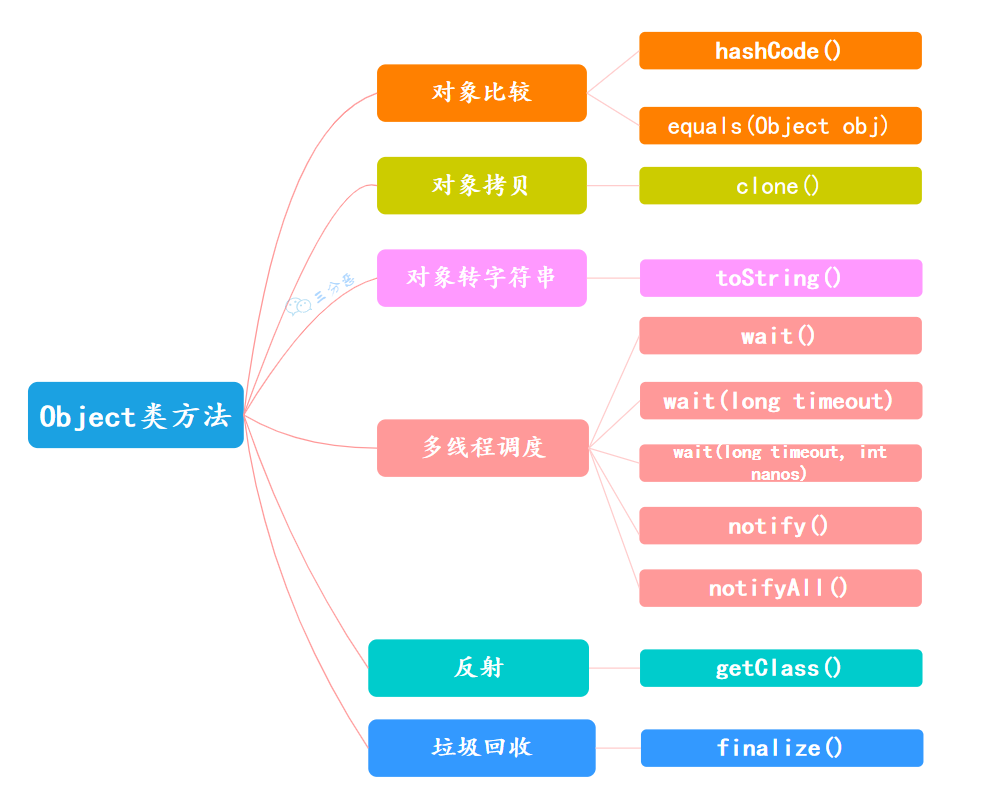
| 1. 了解过`Object`类吗?都有什么方法?你怎么理解`finalize`方法? | ||
|
|
||
|  | ||
|
|
||
| 2. | ||
|
|
||
|
|
||
| ## 异常处理 | ||
|
|
||
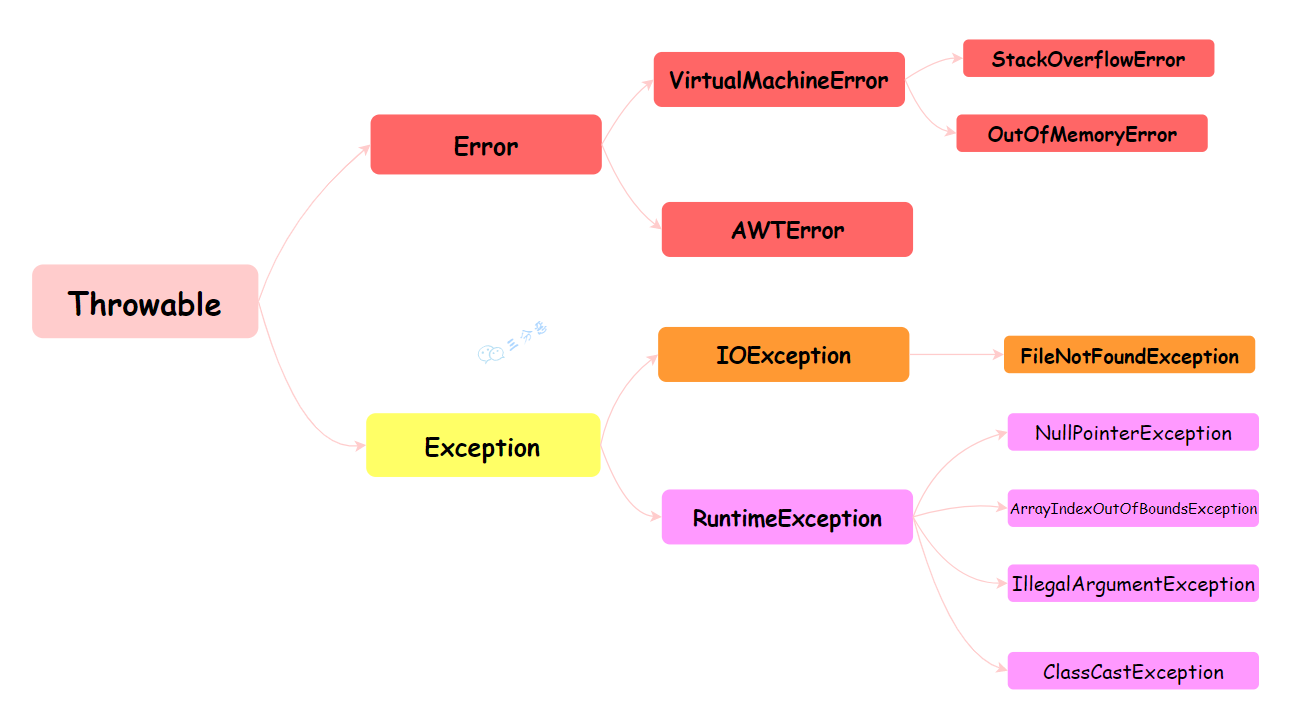
| 1. Java中的异常体系 | ||
|
|
||
|  | ||
|
|
||
| 2. 怎么处理异常? | ||
| 1. 捕获try{}catch{}finalize{} | ||
| 2. 抛出throw、throws | ||
| ## I/O | ||
|
|
||
|
|
||
|
|
||
| | BIO--Blocking IO | 同步阻塞IO(一个连接一个线程,发起请求一直阻塞,一般通过连接池改善) | 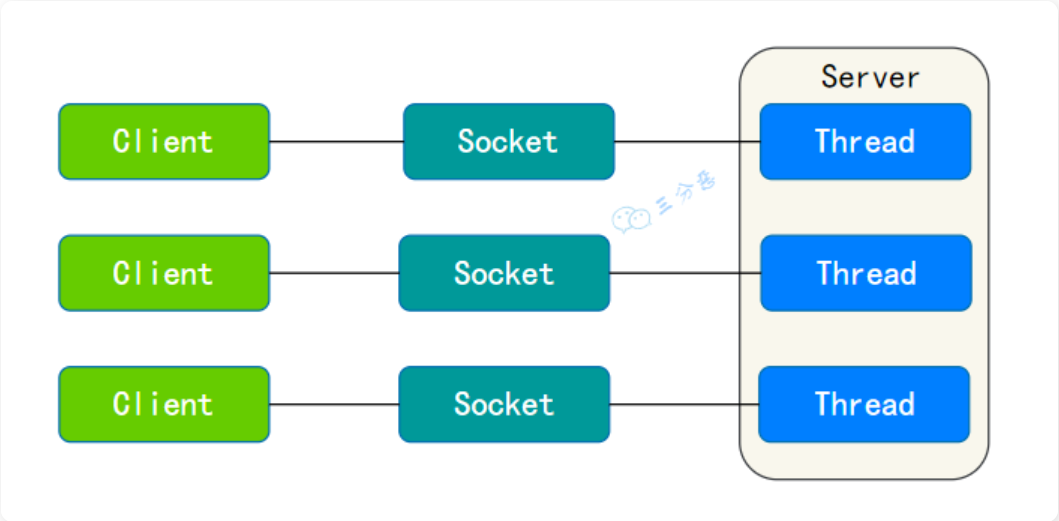 | | ||
| |--- | --- | --- | | ||
| | NIO--Non-blocking IO | 同步非阻塞IO(多个连接复用一个线程,一个请求一个线程) | 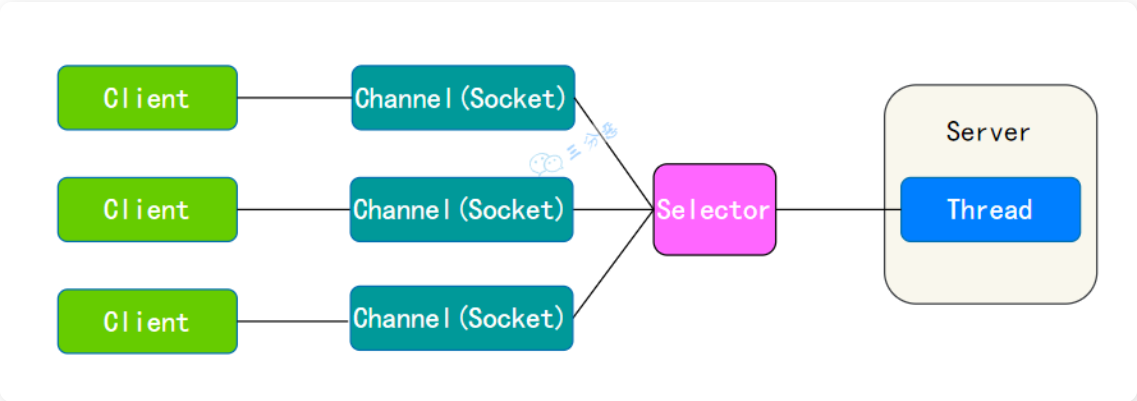 | | ||
| | AIO--Asynchronous IO | 异步非阻塞IO(一个有效请求一个线程,IO请求立即返回,操作结束后,回调通知) |  | | ||
|
|
||
|
|
||
|
|
||
| 1. IO流体系结构 | ||
|
|
||
| 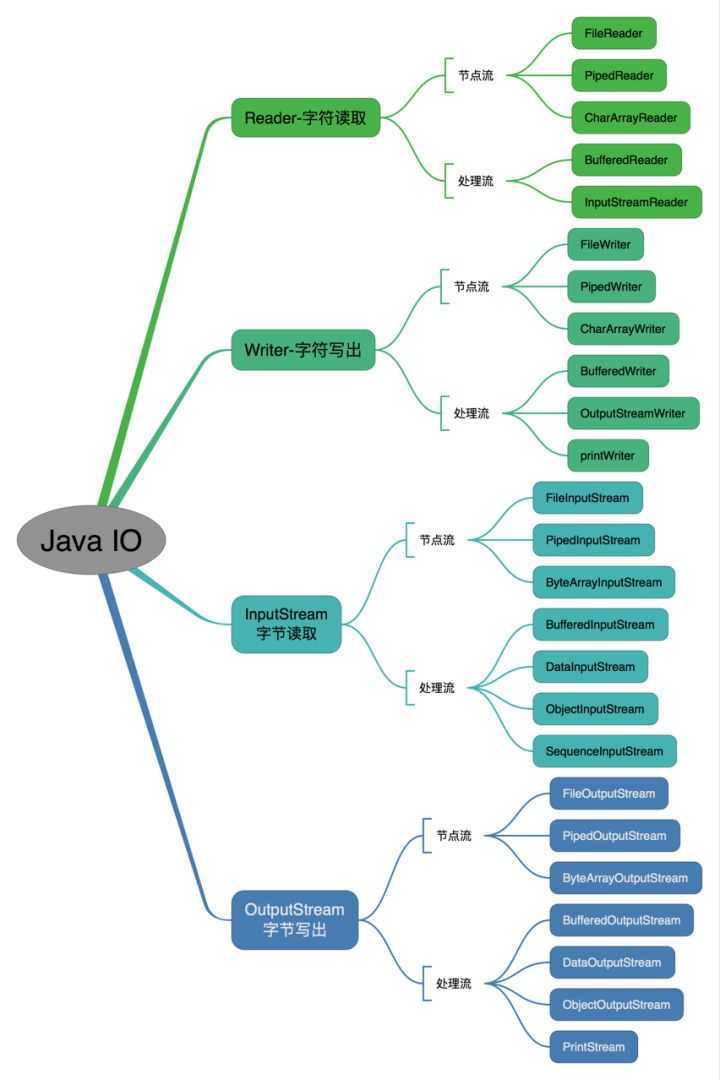 | ||
|
|
||
| 2. 什么是装饰器模式? | ||
| > 我对装饰器的理解就是继承,然后增加新功能,但它们的核心区别在于装饰器模式是通过“添加”新的功能,而不是通过“重写”原有功能来实现扩展的。 | ||
| 在IO流中,这种模式被广泛应用。例如,在java.io包中,InputStream和OutputStream是两个基础的输入输出流类,它们定义了输入输出流的基本行为和接口。然后,有许多其他的类和接口继承自InputStream和OutputStream,并添加了新的功能。这些新类可以看作是装饰器,它们可以增强原有类(被装饰类)的功能。例如,BufferedInputStream和BufferedOutputStream可以在原有类的基础上添加缓冲功能,提高IO性能。 | ||
| 总的来说,装饰器模式是一种灵活且强大的设计模式,它允许我们在运行时动态地添加或删除功能,而无需修改原始的类。这种设计模式提高了代码的复用性和可扩展性。 | ||
| _**手撸装饰器模式:**_ | ||
| ```java | ||
| public interface Printer { | ||
| void print(); | ||
| } | ||
|
|
||
| public class StandardPrinter implements Printer { | ||
| @Overvide | ||
| public void print() { | ||
| System.out.println("Standard print!"); | ||
| } | ||
| } | ||
|
|
||
| public class ColorPrinter implements Printer { | ||
| private Printer printer; | ||
|
|
||
| public ColorPrinter(Printer printer){ | ||
| this.printer = printer; | ||
| } | ||
|
|
||
| @Overvide | ||
| public void print() { | ||
| System.out.print("Color print!"); | ||
| Printer.print(); | ||
| } | ||
| } | ||
|
|
||
| public class Main { | ||
| public static void main(String[] args) { | ||
| Printer sPrinter = new StandardPrinter(); | ||
| sPrinter = new ColorPrinter(sPrinter); | ||
| sPrinter.print(); | ||
| } | ||
| } | ||
| ``` | ||
|
|
||
| ## 序列化 | ||
|
|
||
| 1. 什么是序列化与反序列化 | ||
| 2. 序列化有哪几种方式? | ||
| 1. Java对象流序列化 | ||
|
|
||
| 一般会用Java原生IO 进行转化,一般会用ObjectIO | ||
|
|
||
| 2. JSON序列化 | ||
|
|
||
| JSON序列化的方式有很多,一般会选择使用`jackson`包中的`ObjectMapper`类来将Java对象转化为byte数组或将json串转化为对象 | ||
|
|
||
| 3. ProtoBuff序列化 | ||
|
|
||
| 是一种轻便高效的结构化数据存储格式,通过其序列化对象可以很大程度的把对象进行压缩,大大减小数据传输大小,提高性能。 | ||
|
|
||
| ## 泛型 | ||
|
|
||
| 1. 什么是泛型? | ||
| 2. 什么是类型擦除?为什么要擦除? | ||
| 3. 为什么泛型不可以被重载? | ||
|
|
||
| ## 注解 | ||
|
|
||
| 1. 什么是注解?注解的生命周期? | ||
| 2. 说说`@Override`和`@Autowired`的源码 | ||
|
|
||
| ## 反射 | ||
|
|
||
| 1. 怎么理解反射? | ||
|
|
||
| 通过new来创建对象就是正射,是在编译时就会确定创建的对象类型;而反射就是动态地获取类信息、构造器进而`newInstance`创建对象的过程。 | ||
|
|
||
| 2. 怎么通过反射来创建一个对象? | ||
|
|
||
| 无参实例化:`Object obj = Class.forName(类名).getConstructor().newInstance();` | ||
| 有参实例化:`Object obj = Class.forName(类名).getConstructor(String.class).newInstance("汪汪");` | ||
| ```java | ||
| public class Main { | ||
| public static void main(String[] args) { | ||
| try { | ||
| // 获取Dog类的Class对象 | ||
| Class<?> dogClass = Class.forName("Dog"); | ||
|
|
||
| // 获取Dog类的构造器 | ||
| Constructor<?> dogConstructor = dogClass.getConstructor(); | ||
|
|
||
| // 通过构造器创建Dog对象 | ||
| Object dog = dogConstructor.newInstance(); | ||
|
|
||
| // 如果需要初始化参数,可以使用带有参数的构造函数 | ||
| Constructor<?> dogConstructorWithParams = dogClass.getConstructor(String.class); | ||
| Object dogWithName = dogConstructorWithParams.newInstance("旺财"); | ||
|
|
||
| } catch (ClassNotFoundException | NoSuchMethodException | IllegalAccessException | InstantiationException | InvocationTargetException e) { | ||
| e.printStackTrace(); | ||
| } | ||
| } | ||
| } | ||
| class Dog { | ||
| private String name; | ||
|
|
||
| public Dog() { | ||
| name = "小黄学长"; | ||
| } | ||
|
|
||
| public Dog(String name) { | ||
| this.name = name; | ||
| } | ||
|
|
||
| public String getName() { | ||
| return name; | ||
| } | ||
| } | ||
| ``` | ||
|
|
||
| ## 源码 | ||
|
|
||
| 1. 说说你对 HashMap 数据结构的理解? | ||
|
|
||
| 首先,hashmap 的数据结构是基于数组和链表的,如图: | ||
|
|
||
| 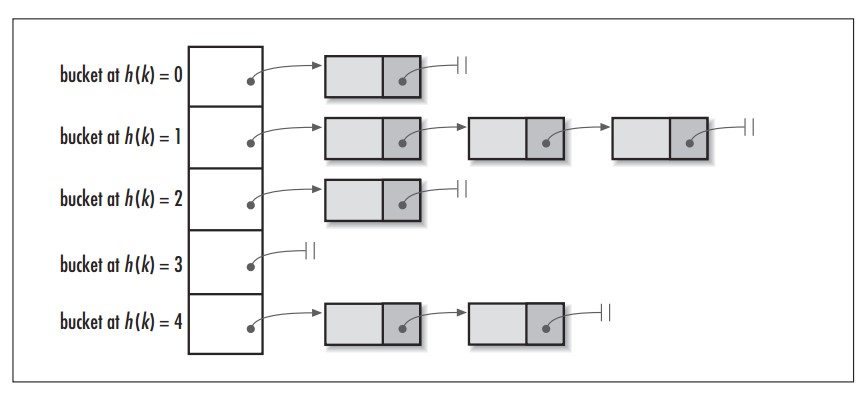 | ||
|
|
||
| so,既然是基于数组和链表的,那就说明数组和链表的特点也就是 HashMap 的特点: | ||
|
|
||
| **数组:寻址快,直接根据索引访问元素,插入和删除慢;** | ||
|
|
||
| **链表:寻址慢,需要从头节点开始遍历,插入和删除快。** | ||
|
|
||
|
|
||
|
|
||
| 说到 HashMap 就要说到 Java 8 了,Java 8 之前,HashMap 使用一个数组加链表的结构来存储 【K,V】 键值对。 | ||
|
|
||
| 如果发生 hash 冲突,那么 | ||
|
|
||
| 这将导致在处理 hash 冲突的时候性能不高,尤其是链表很长的时候。因此,Java 8 中的 HashMap 引入了红黑树来替代链表,这样当链表变长的时候,会自动转换为红黑树,从而提高了增删改查的性能。 | ||
|
|
||
|
|
||
|
|
||
| 2. 什么是 Hash 冲突?怎么解决? | ||
| 3. 为什么阿里巴巴Java开发者手册中有一条建议是**强制禁止**使用构造方法把 BigDecimal(double) 的方式把 double 的值转化为 BigDecimal 对象? | ||
|
|
||
| > 说明:因为会存在精度损失风险,如:BigDecimal(0.1F),实际存储值为0.10000000149, | ||
| > | ||
| > 正确的方法应该怎么做? | ||
| > | ||
| > 一:String入参:BigDecimal bd = new BigDecimal("0.1") | ||
| > | ||
| > 二:使用内部的 valueOf 方法:BigDecimal bd1 = BigDecimal.valueOf(0.1); |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,163 @@ | ||
| ## 基础篇 | ||
| > ### Q:什么是数据库第一二三范式? | ||
| A: | ||
|
|
||
| - 第一范式:又称专一范式,字段不能再拆分; | ||
| - 第二范式:又称 MySQL 家规,必须完全依赖顺从主键,若有与主键无关字段者,设置为联合主键; | ||
| - 第三范式:又称恋爱脑范式,遵守家规,远离小三。 | ||
|
|
||
|  | ||
| 一般来说,“`小企`”这个渣男(也可能不止`小企`)在日常开发中都是违反`范式家规`标准的,要为了性能,通过一些冗余的数据,空间换时间。 | ||
|
|
||
| > ### Q:MySQL 有几种字段类型? | ||
| A:字段类型大致可以分为三类:数值类型、字符类型、时间类型 | ||
|
|
||
| - 数值类型: | ||
| - 整数类型:微小TYNYINT、小SMALLINT、中等MEDIUMINT、INT、大整型BIGINT; | ||
| - 小数类型:FLOAT、DUBBLE、DECIMAL、NUMERIC | ||
| - 字符类型:(还有好几种) | ||
| - CHAR | ||
| - VARCHAR | ||
| - BINARY | ||
| - VARBINARY | ||
| - BLOB | ||
| - 二进制大对象类型,用于存储二进制数据(如文档、图像、音频等),有两个分支,小TINYBLOB和长LONGBLOB | ||
| - TEXT | ||
| - 文本类型,不许预设长度,可根据需要动态划分空间。也分为 TINYTEXT 和 LONGTEXT,以适应不同大小的文本数据 | ||
| - ENUM | ||
| - 枚举类型,限制了字段存储的值 | ||
| - SET | ||
| - 集合类型,不可重复 | ||
| - 日期/时间类型 | ||
| - DATE | ||
| - TIME | ||
| - DATETIME | ||
| - TIMESTAMP | ||
| > ### Q:CHAR 和 VARCHAR 字符类型的区别? | ||
| A: | ||
|
|
||
| - `char`长度固定,所以存取速度快,甚至快varchar一半;如果长度没有达到预设值,用空格补充。因为定长,所以浪费一些空间,属于空间换时间。最多可存`255`个字符; | ||
| - `varchar`字符长度可变,所以不浪费空间,属于时间换空间。最多可存放`65532`个字符串,至于为什么是`65532`,那就需要看相关存储引擎`InnoDB`的知识了。 | ||
| > ### Q:说一说两个时间类型的区别 | ||
| A: | ||
|
|
||
| - 时间起始范围不同,`TIMESTAMP`为`1970-2028`,`datetime`为`1000-9999` | ||
| - 存储空间不同,`TIMESTAMP`存储空间为`4字节`,`DATETIME`存储空间为`8字节` | ||
| - 时区,`TIMESTAMP`存储时间依赖于时区显示,`DATETIME`存储时间与时区无关 | ||
| - 默认值,`TIMESTAMP`不为空,后者为空 | ||
| > ### Q:什么类型可以用于存储二进制数据? | ||
| A:blob,Blob常常是数据库中用来存储二进制文件的字段类型。通常用于存储大量的数据,例如音频、视频、图片等文件,由于它们的大小,必须使用特殊的方式来处理(例如:上传、下载或者存放到一个数据库)。 | ||
| > ### Q:怎么存储`emoji`表情? | ||
| A: | ||
| > ### Q:你了解 SQL 的执行流程吗? | ||
| A:为了更加直观,借用`三元表达式`的语法来描述一条 SQL 执行的流程。 | ||
|
|
||
| 1. 首先检查 SQL 是否有执行的权限? 查询结果缓存 :返回报错信息; | ||
| 2. 是否有缓存? 直接返回结果 :检查 SQL 是否有语法错误; | ||
| 3. 语法正确? MySQL 的服务器对语句进行优化,确定执行方案 : | ||
| 4. 确定方案?调用数据库引擎接口,执行方案,返回执行结果。 | ||
| > ### Q:什么是 DDL 与 DML ? | ||
| A:是 DBMS 中的不同类型的语言指令集。 | ||
|
|
||
| - DDL:database definition language,定义或修改数据库结构的命令,例如:CREAT、ALTER、DROP、TRUNCATE(截断,命令用于快速删除表中的所有数据但不删除表本身。) | ||
| - DML:database manipulation language,用于操作数据库中的数据的命令,例如CURD | ||
| > ### Q:MySQL 怎么进行优化? | ||
| A: | ||
|
|
||
| 1. **索引优化:**基于最经常查询的字段或数据,合理的进行创建索引。例如一个用户表(id, name, email),其中基于 email 查询的语句很多,所以可以在 email 字段上创建一个索引:`CREATE INDEX idx_email ON user(email);` | ||
| 2. **查询优化:**尽量避免全表扫描、减少表连接的操作。例如 `SELECT * FROM user WHERE name = '张三' LIMIT 1;` | ||
| 3. **数据库设计优化:**根据数据访问模式和业务需求设计数据库结构,如何选择合适的数据类型、如何进行数据规范化、什么时候需要反范式设计? | ||
|
|
||
| **实际上,一般互联网公司的设计都是反范式的,通过冗余一些数据,避免跨表跨库,利用空间换时间,提高性能。** | ||
|
|
||
| 4. **分区:**对于大数据量的表,我们可以使用分区技术提高查询效率。分区就是把大表拆分为一个个小表,减少单次查询数据量,提高单次查询的效率 --> 进而提高效率! | ||
| 5. **硬件和配置优化:**除了 SQL 语句和数据库设计,硬件和 MySQL 的配置也会对性能造成影响。所以我们可以根据服务器的硬件状况和业务需求对MySQL的连接数以及内存使用进行配置。 | ||
|
|
||
| > ### Q:MySQL 数据类型有哪些?Java 中有哪些字段与之对应? | ||
|
|
||
|
|
||
| ## 架构篇 | ||
|
|
||
| 首先,收起你自认为架构篇很难理解的想法,我们还是从 MySQL 是一个房子入手。 | ||
|
|
||
| > Q:你是怎么理解 MySQL 的架构的? | ||
| A:MySQL 就相当于一个档案室,存放不同的档案,一个数据库好用,肯定有原因,架构也就是构成。那么一个快递驿站肯定包括下面这三部分: | ||
|
|
||
| - 快递驿站APP--客户端(与用户交互的关键) | ||
| - 工作人员--存储引擎(我 MySQL 学的不好,我猜应该是与存储规则相关的) | ||
| - 快递货架--服务层(堆放数据,索引数据) | ||
|
|
||
| {{{{{{待画图!!!}}}}}} | ||
| MySQL 逻辑架构图主要分为三层:客户端、存储引擎、服务层 | ||
|
|
||
| 1. 客户端层:这是与 MySQL 服务器交互的接口,它提供了用户与服务器进行通信的手段。客户端层处理连接请求、处理查询请求、认证用户权限以及执行与服务器之间的通信。此外,这一层还负责处理与服务相关的各种任务,例如管理连接、处理错误、诊断和调试等。 | ||
| 2. Server 层:这一层是 MySQL 的核心,它包含了大多数 MySQL 的服务功能。这包括解析查询语句、分析查询计划、优化查询计划以及执行查询计划等。此外,Server 层还负责处理内置函数,如日期、时间、数学和加密函数等。对于跨存储引擎的功能,如存储过程、触发器和视图等,也都在这一层实现。这些功能对于整个数据库系统来说是至关重要的。 | ||
| 3. 存储引擎层:这一层负责数据的存储和提取。存储引擎负责与底层操作系统交互,管理数据的存储位置、文件格式和索引等。不同的存储引擎具有不同的特点和性能,可以根据应用的需求选择适合的存储引擎。MySQL 支持多种存储引擎,如 InnoDB、MyISAM、Memory 等。存储引擎通过 API 与 Server 层进行通信,这些接口屏蔽了不同存储引擎之间的差异,使得上层的应用程序可以透明地访问底层的数据存储方式。 | ||
|
|
||
| 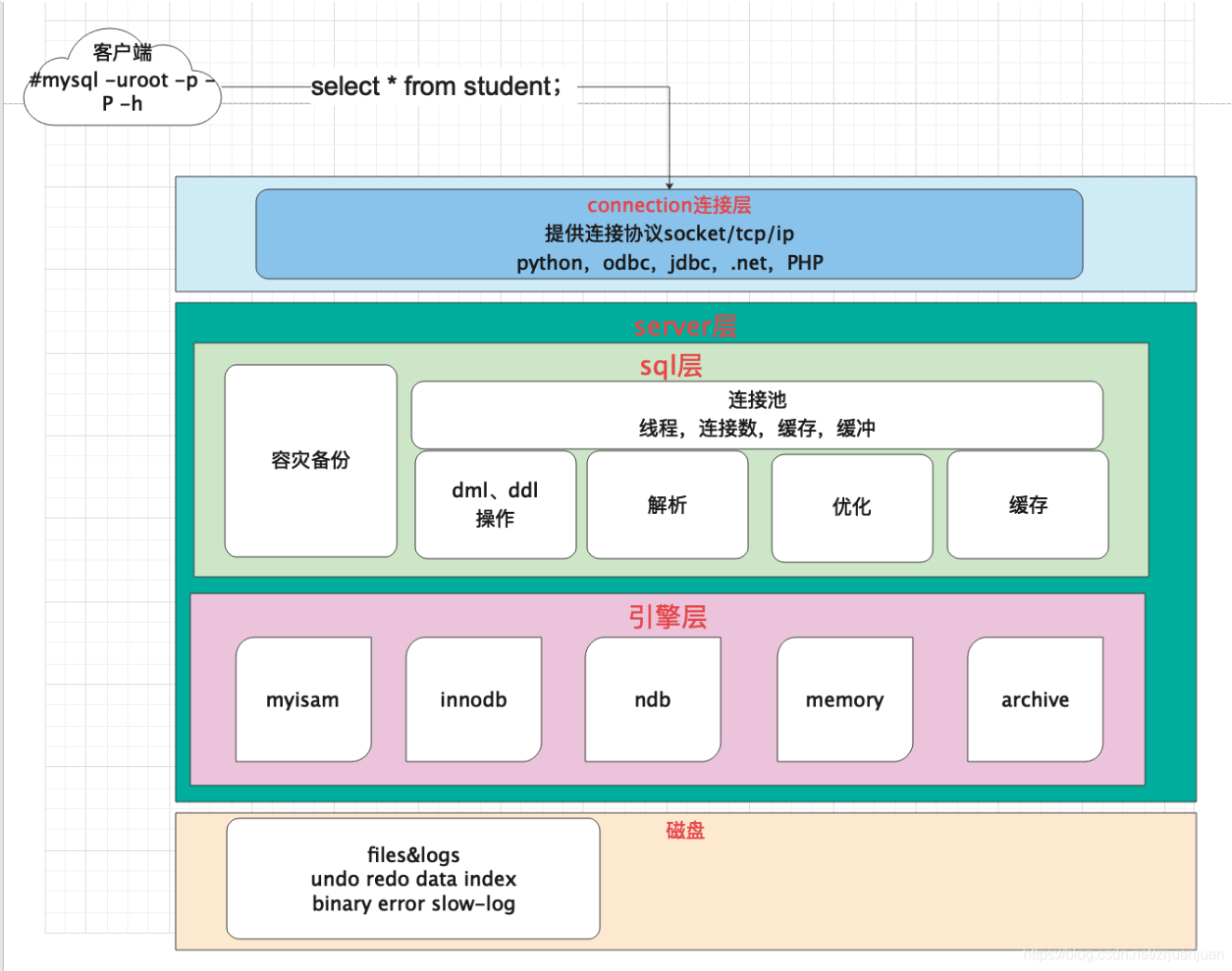 | ||
|
|
||
| > Q:数据库调优,你是怎么做的 | ||
| A:以下回答来自文心一言,待优化,回答要结合MySQL的**架构以及存储引擎**来说,以及自己的见解 | ||
| 数据库调优的方法有很多,以下是一些常见的调优方法: | ||
|
|
||
| 1. 定期优化重建数据库:定期对数据库进行优化和重建,可以消除数据库中的碎片和冗余数据,提高数据库的性能和稳定性。 | ||
| 2. 减少磁盘写入操作:通过使用缓存技术、优化数据插入和更新操作、避免频繁的磁盘操作等手段,可以减少磁盘的写入操作,提高数据库的性能。 | ||
| 3. 合理使用索引:索引是提高查询速度的重要手段,通过添加合适的索引可以加速查询操作。需要根据查询语句和表结构来确定需要添加的索引。 | ||
| 4. 优化SQL语句:通过优化SQL语句,可以减少数据库的负载和提高查询效率。例如,避免使用SELECT * 语句,只查询需要的数据字段;避免在查询中使用复杂的子查询和连接查询等。 | ||
| 5. 调整数据库参数:根据实际需求和性能测试结果,调整数据库的参数可以提高数据库的性能和响应速度。 | ||
| 6. 使用存储过程和触发器:存储过程和触发器可以减少数据库的负载和提高数据处理效率。通过将常用的数据处理逻辑封装到存储过程和触发器中,可以减少对数据库的频繁操作。 | ||
| 7. 数据库分区:对于大型数据库,可以采用分区技术将数据分散到不同的磁盘上,提高I/O处理能力和并发性能。 | ||
| 8. 使用RAID技术:RAID技术可以提供高性能、高可靠性和高容错的存储系统,通过将数据分散到多个磁盘上,可以提高I/O处理能力和数据安全性。 | ||
| 9. 使用缓存技术:缓存技术可以减少磁盘访问次数和提高数据处理速度。例如,使用内存缓存来存储经常访问的数据,减少对磁盘的访问次数。 | ||
| 10. 定期备份数据:定期备份数据可以防止数据丢失和灾难性故障,同时也可以提高数据处理效率和安全性。 | ||
|
|
||
| 这些方法可以根据实际情况选择使用,但需要注意的是,数据库调优是一个复杂的过程,需要综合考虑系统硬件、应用程序和数据等方面的因素。因此,在进行数据库调优时,建议根据实际情况进行测试和评估,以确保达到最佳的效果。 | ||
|
|
||
| > Q:你知道三种存储引擎的区别吗? | ||
| A: | ||
|
|
||
| | 功能 | MlSAM | MEMORY | InnoDB | | ||
| | ------------ | ----- | ------ | ------ | | ||
| | 存储限制 | 256TB | RAM | 64TB | | ||
| | 支持事务 | No | No | Yes | | ||
| | 支持全文索引 | Yes | No | Yes | | ||
| | 支持树索引 | Yes | Yes | Yes | | ||
| | 支持哈希索引 | No | Yes | Yes | | ||
| | 支持数据缓存 | No | N/A | Yes | | ||
| | 支持外键 | No | No | Yes | | ||
|
|
||
| 怎么选择存储引擎的使用? | ||
|
|
||
| 1. 想用事务安全,并要求实现并发控制,用InnoDB | ||
| 2. 主要用来查询与插入记录,用MyISAM | ||
| 3. 临时存放数据,不考虑安全,用MEMORY | ||
|
|
||
| **tips:存储引擎是基于数据表**的,所以一个数据库的多个表**可以根据实际业务**,来**使用不同的存储引擎**,以此**提高**整个数据库的**性能**。 | ||
|
|
||
| | 区别 | MyISAM | InnoDB | | ||
| | ------------------ | ------------------------------------------------------------ | -------------------------------- | | ||
| | 存储结构 | 每个表存储成3个文件: | | | ||
| | 表定义文件(.frm) | | | | ||
| | 数据文件(.MYD) | | | | ||
| | 索引文件(.MYI) | 所有表存放于同一数据文件,也可能多个文件或者独立的表空间文件,表的大小一般为2G | | | ||
| | 事务 | 不支持 | 支持 | | ||
| | 最小锁粒度 | 表级锁,更新会锁表,导致其他查询与插入阻塞 | 行级锁 | | ||
| | 索引类型 | 非聚簇索引,B树 | 聚簇索引,B+树 | | ||
| | 主键 | 可无 | 如未设置,自动生成(用户不可见) | | ||
| | 外键 | 不支持 | 支持 | | ||
| | 表行数 | 存有缓存,直接取出 | 需要遍历整个表 | | ||
|
|
||
| _🆗架构篇就到这里,有没发现,似乎MySQL的基础架构也就这回事,也没啥难点。最后强调一点,当我们试图学会一门知识的时候,不要机械记忆,重要的是融会贯通(内心OS:啥子贯通?不就是理论翻译成人话吗?),找到适合自己记忆的方法。_ |
Oops, something went wrong.