
PyTorch implementation of our paper "Occlusion-Aware Cost Constructor for Light Field Depth Estimation". [CVPR 2022]
- 2022-07-02: Correct a mistake in
train.py, i.e., dispGT should be fed to the network during training. - 2022-03-02: Our paper is accepted to CVPR 2022.
- 2022-02-28: Codes and models are uploaded.
- PyTorch 1.3.0, torchvision 0.4.1. The code is tested with python=3.7, cuda=9.0.
- A single GPU with cuda memory larger than 12 GB is required to reproduce the inference time reported in our paper.
- We used the HCI 4D LF benchmark for training and evaluation. Please refer to the benchmark website for details.
├──./datasets/
│ ├── training
│ │ ├── antinous
│ │ │ ├── gt_disp_lowres.pfm
│ │ │ ├── valid_mask.png
│ │ │ ├── input_Cam000.png
│ │ │ ├── input_Cam001.png
│ │ │ ├── ...
│ │ ├── boardgames
│ │ ├── ...
│ ├── validation
│ │ ├── backgammon
│ │ │ ├── gt_disp_lowres.pfm
│ │ │ ├── input_Cam000.png
│ │ │ ├── input_Cam001.png
│ │ │ ├── ...
│ │ ├── boxes
│ | ├── ...
│ ├── test
│ │ ├── bedroom
│ │ │ ├── input_Cam000.png
│ │ │ ├── input_Cam001.png
│ │ │ ├── ...
│ │ ├── bicycle
│ | ├── herbs
│ | ├── origami
- Set the hyper-parameters in
parse_args()if needed. We have provided our default settings in the realeased codes. - Run
train.pyto perform network training. - Checkpoint will be saved to
./log/.
- Place the input LFs into
./demo_input(see the attached examples). - Run
test.pyto perform inference on each test scene. - The result files (i.e.,
scene_name.pfm) will be saved to./Results/.
- Perform inference on each scene separately to generate
.pfmresult files. - Download groundtruth disparity images (i.e.,
gt_disp_lowres.pfm) and use the official evaluation toolkit to obtain quantitative results.
- Run
test_inference_time.pyto reproduce the inference time reported in our paper. Note that, the inference need to be performed on a GPU with a cuda memory larger than 12 GB.



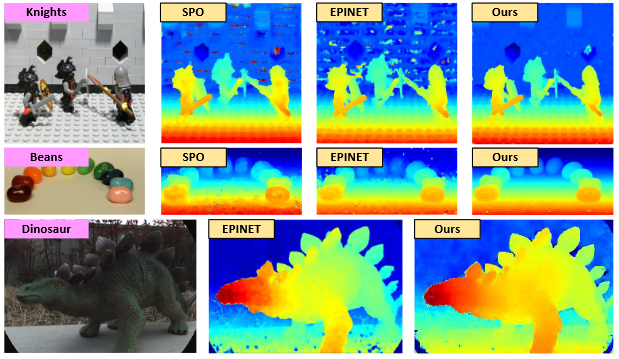
Please refer to our supplemental material for additional quantitative and visual comparisons.
If you find this work helpful, please consider citing:
@InProceedings{OACC-Net,
author = {Wang, Yingqian and Wang, Longguang and Liang, Zhengyu and Yang, Jungang and An, Wei and Guo, Yulan},
title = {Occlusion-Aware Cost Constructor for Light Field Depth Estimation},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {19809-19818}
}
Welcome to raise issues or email to wangyingqian16@nudt.edu.cn for any question regarding this work.