Distributed delayed jobs in nodejs. Resque is a background job system backed by Redis (version 2.6.0 and up required). It includes priority queues, plugins, locking, delayed jobs, and more! This project is a very opinionated but API-compatible with Resque and Sidekiq (caveats). We also implement some of the popular Resque plugins, including resque-scheduler and resque-retry
The full API documentation for this package is automatically generated from the main via typedoc branch and published to https://node-resque.actionherojs.com/

![]()
Resque is a queue based task processing system that can be thought of as a "Kanban" style factory. Workers in this factory can each only work one Job at a time. They pull Jobs from Queues and work them to completion (or failure). Each Job has two parts: instructions on how to complete the job (the perform function), and any inputs necessary to complete the Job.
In our factory example, Queues are analogous to conveyor belts. Jobs are placed on the belts (Queues) and are held in order waiting for a Worker to pick them up. There are three types of Queues: regular work Queues, Delayed Job Queues, and the Failed Job Queue. The Delayed Job Queues contains Job definitions that are intended to be worked at or in a specified time. The Failed Job Queue is where Workers place any Jobs that have failed during execution.
Our Workers are the heart of the factory. Each Worker is assigned one or more Queues to check for work. After taking a Job from a Queue the Worker attempts to complete the Job. If successful, they go back to check out more work from the Queues. However, if there is a failure, the Worker records the job and its inputs in the Failed Jobs Queue before going back for more work.
The Scheduler can be thought of as a specialized type of Worker. Unlike other Workers, the Scheduler does not execute any Jobs, instead it manages the Delayed Job Queue. As Job definitions are added to the Delayed Job Queue they must specify when they can become available for execution. The Scheduler constantly checks to see if any Delayed Jobs are ready to execute. When a Delayed Job becomes ready for execution the Scheduler places a new instance of that Job in its defined Queue.
You can read the API docs for Node Resque @ node-resque.actionherojs.com. These are generated automatically from the master branch via TypeDoc
- The version of redis required is >= 2.6.0 as we use lua scripting to create custom atomic operations
‼️ Version 6+ of Node Resque uses TypeScript. We will still include JavaScript transpiled code in NPM releases, but they will be generated from the TypeScript source. Functionality between node-resque v5 and v6 should be the same.‼️ Version 5+ of Node Resque uses async/await. There is no upgrade path from previous versions. Node v8.0.0+ is required.
I learn best by examples:
import { Worker, Plugins, Scheduler, Queue } from "node-resque";
async function boot() {
// ////////////////////////
// SET UP THE CONNECTION //
// ////////////////////////
const connectionDetails = {
pkg: "ioredis",
host: "127.0.0.1",
password: null,
port: 6379,
database: 0,
// namespace: 'resque',
// looping: true,
// options: {password: 'abc'},
};
// ///////////////////////////
// DEFINE YOUR WORKER TASKS //
// ///////////////////////////
let jobsToComplete = 0;
const jobs = {
add: {
plugins: [Plugins.JobLock],
pluginOptions: {
JobLock: { reEnqueue: true },
},
perform: async (a, b) => {
await new Promise((resolve) => {
setTimeout(resolve, 1000);
});
jobsToComplete--;
tryShutdown();
const answer = a + b;
return answer;
},
},
subtract: {
perform: (a, b) => {
jobsToComplete--;
tryShutdown();
const answer = a - b;
return answer;
},
},
};
// just a helper for this demo
async function tryShutdown() {
if (jobsToComplete === 0) {
await new Promise((resolve) => {
setTimeout(resolve, 500);
});
await scheduler.end();
await worker.end();
process.exit();
}
}
// /////////////////
// START A WORKER //
// /////////////////
const worker = new Worker(
{ connection: connectionDetails, queues: ["math", "otherQueue"] },
jobs,
);
await worker.connect();
worker.start();
// ////////////////////
// START A SCHEDULER //
// ////////////////////
const scheduler = new Scheduler({ connection: connectionDetails });
await scheduler.connect();
scheduler.start();
// //////////////////////
// REGISTER FOR EVENTS //
// //////////////////////
worker.on("start", () => {
console.log("worker started");
});
worker.on("end", () => {
console.log("worker ended");
});
worker.on("cleaning_worker", (worker, pid) => {
console.log(`cleaning old worker ${worker}`);
});
worker.on("poll", (queue) => {
console.log(`worker polling ${queue}`);
});
worker.on("ping", (time) => {
console.log(`worker check in @ ${time}`);
});
worker.on("job", (queue, job) => {
console.log(`working job ${queue} ${JSON.stringify(job)}`);
});
worker.on("reEnqueue", (queue, job, plugin) => {
console.log(`reEnqueue job (${plugin}) ${queue} ${JSON.stringify(job)}`);
});
worker.on("success", (queue, job, result, duration) => {
console.log(
`job success ${queue} ${JSON.stringify(
job,
)} >> ${result} (${duration}ms)`,
);
});
worker.on("failure", (queue, job, failure, duration) => {
console.log(
`job failure ${queue} ${JSON.stringify(
job,
)} >> ${failure} (${duration}ms)`,
);
});
worker.on("error", (error, queue, job) => {
console.log(`error ${queue} ${JSON.stringify(job)} >> ${error}`);
});
worker.on("pause", () => {
console.log("worker paused");
});
scheduler.on("start", () => {
console.log("scheduler started");
});
scheduler.on("end", () => {
console.log("scheduler ended");
});
scheduler.on("poll", () => {
console.log("scheduler polling");
});
scheduler.on("leader", () => {
console.log("scheduler became leader");
});
scheduler.on("error", (error) => {
console.log(`scheduler error >> ${error}`);
});
scheduler.on("cleanStuckWorker", (workerName, errorPayload, delta) => {
console.log(
`failing ${workerName} (stuck for ${delta}s) and failing job ${errorPayload}`,
);
});
scheduler.on("workingTimestamp", (timestamp) => {
console.log(`scheduler working timestamp ${timestamp}`);
});
scheduler.on("transferredJob", (timestamp, job) => {
console.log(`scheduler enquing job ${timestamp} >> ${JSON.stringify(job)}`);
});
// //////////////////////
// CONNECT TO A QUEUE //
// //////////////////////
const queue = new Queue({ connection: connectionDetails }, jobs);
queue.on("error", function (error) {
console.log(error);
});
await queue.connect();
await queue.enqueue("math", "add", [1, 2]);
await queue.enqueue("math", "add", [1, 2]);
await queue.enqueue("math", "add", [2, 3]);
await queue.enqueueIn(3000, "math", "subtract", [2, 1]);
jobsToComplete = 4;
}
boot();
// and when you are done
// await queue.end()
// await scheduler.end()
// await worker.end()There are 3 main classes in node-resque: Queue, Worker, and Scheduler
- Queue: This is the interface your program uses to interact with resque's queues - to insert jobs, check on the performance of things, and generally administer your background jobs.
- Worker: This interface is how jobs get processed. Workers are started and then they check for jobs enqueued into various queues and complete them. If there's an error, they write to the
errorqueue.- There's a special class called
multiWorkerin Node Resque which will run many workers at once for you (see below).
- There's a special class called
- Scheduler: The scheduler can be thought of as the coordinator for Node Resque. It is primarily in charge of checking when jobs told to run later (with
queue.enqueueInorqueue.enqueueAt) should be processed, but it performs some other jobs like checking for 'stuck' workers and general cluster cleanup.- You can (and should) run many instances of the scheduler class at once, but only one will be elected to be the 'leader', and actually do work.
- The 'delay' defined on a scheduled job does not specify when the job should be run, but rather when the job should be enqueued. This means that
node-resquecan not guarantee when a job is going to be executed, only when it will become available for execution (added to a Queue).
new queuerequires only the "queue" variable to be set. If you intend to run plugins withbeforeEnqueueorafterEnqueuehooks, you should also pass thejobsobject to it.new workerhas some additional options:
options = {
looping: true,
timeout: 5000,
queues: "*",
name: os.hostname() + ":" + process.pid,
};Note that when using "*" queue:
- there's minor performance impact for checking the queues
- queues are processed in undefined order
The configuration hash passed to new NodeResque.Worker, new NodeResque.Scheduler or new NodeResque.Queue can also take a connection option.
const connectionDetails = {
pkg: "ioredis",
host: "127.0.0.1",
password: "",
port: 6379,
database: 0,
namespace: "resque", // Also allow array of strings
};
const worker = new NodeResque.Worker(
{ connection: connectionDetails, queues: "math" },
jobs,
);
worker.on("error", (error) => {
// handler errors
});
await worker.connect();
worker.start();
// and when you are done
// await worker.end()You can also pass redis client directly.
// assume you already initialized redis client before
// the "redis" key can be IORedis.Redis or IORedis.Cluster instance
const redisClient = new Redis();
const connectionDetails = { redis: redisClient };
// or
const redisCluster = new Cluster();
const connectionDetails = { redis: redisCluster };
const worker = new NodeResque.Worker(
{ connection: connectionDetails, queues: "math" },
jobs,
);
worker.on("error", (error) => {
// handler errors
});
await worker.connect();
worker.start();
// and when you are done
await worker.end();- Be sure to call
await worker.end(),await queue.end()andawait scheduler.end()before shutting down your application if you want to properly clear your worker status from resque. - When ending your application, be sure to allow your workers time to finish what they are working on
- This project implements the "scheduler" part of rescue-scheduler (the daemon which can promote enqueued delayed jobs into the work queues when it is time), but not the CRON scheduler proxy. To learn more about how to use a CRON-like scheduler, read the Job Schedules section of this document.
- "Namespace" is a string which is appended to the front of your keys in redis. Normally, it is "resque". This is helpful if you want to store multiple work queues in one redis database. Do not use
keyPrefixif you are using theioredis(default) redis driver in this project (see #245 for more information.) - If you are using any plugins which effect
beforeEnqueueorafterEnqueue, be sure to pass thejobsargument to thenew NodeResque.Queue()constructor - If a job fails, it will be added to a special
failedqueue. You can then inspect these jobs, write a plugin to manage them, move them back to the normal queues, etc. Failure behavior by default is just to enter thefailedqueue, but there are many options. Check out these examples from the ruby ecosystem for inspiration: - If you plan to run more than one worker per nodejs process, be sure to name them something distinct. Names must follow the pattern
hostname:pid+unique_id. For example: - For the Retry plugin, a success message will be emitted from the worker on each attempt (even if the job fails) except the final retry. The final retry will emit a failure message instead.
If you want to learn more about running Node-Resque with docker, please view the examples here: https://github.com/actionhero/node-resque/tree/master/examples/docker
const name = os.hostname() + ":" + process.pid + "+" + counter;
const worker = new NodeResque.Worker(
{ connection: connectionDetails, queues: "math", name: name },
jobs,
);DO NOT USE THIS IN PRODUCTION. In tests or special cases, you may want to process/work a job in-line. To do so, you can use worker.performInline(jobName, arguments, callback). If you are planning on running a job via #performInline, this worker should also not be started, nor should be using event emitters to monitor this worker. This method will also not write to redis at all, including logging errors, modify resque's stats, etc.
const queue = new NodeResque.Queue({ connection: connectionDetails, jobs });
await queue.connect();API documentation for the main methods you will be using to enqueue jobs to be worked can be found @ node-resque.actionherojs.com.
From time to time, your jobs/workers may fail. Resque workers will move failed jobs to a special failed queue which will store the original arguments of your job, the failing stack trace, and additional metadata.
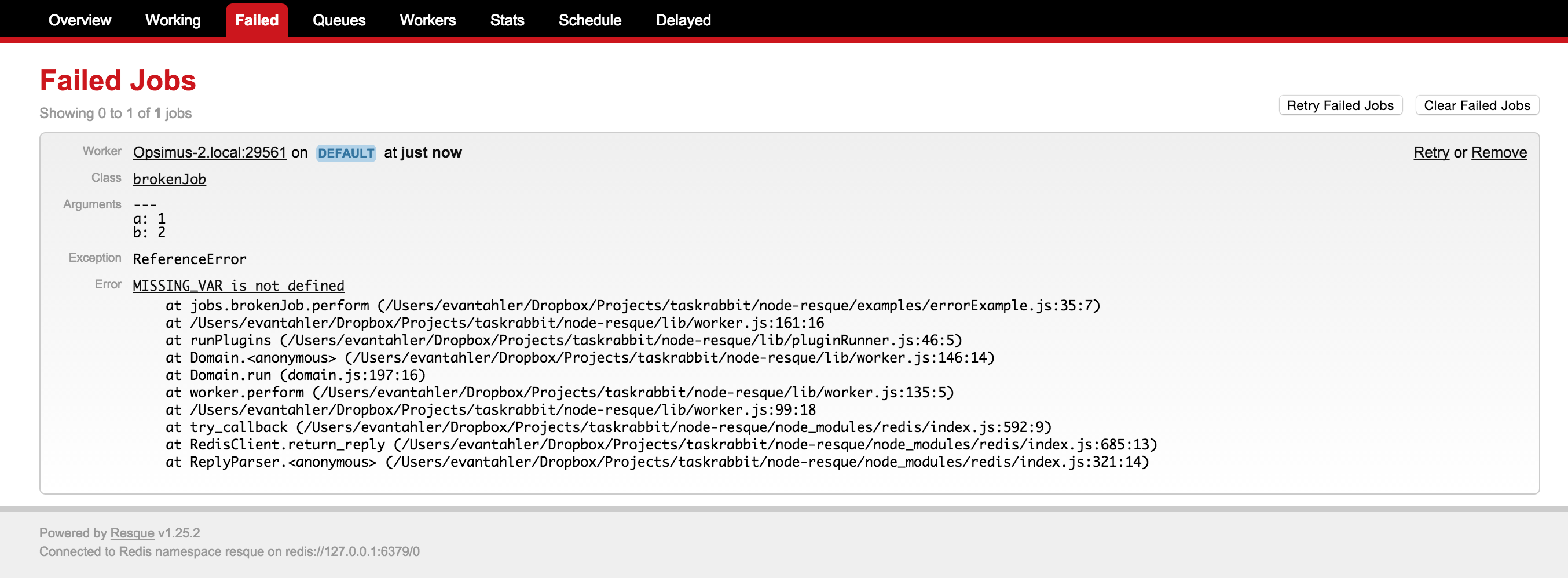
You can work with these failed jobs with the following methods:
let failedCount = await queue.failedCount()
failedCountis the number of jobs in the failed queue
let failedJobs = await queue.failed(start, stop)
failedJobsis an array listing the data of the failed jobs. Each element looks like:{"worker": "host:pid", "queue": "test_queue", "payload": {"class":"slowJob", "queue":"test_queue", "args":[null]}, "exception": "TypeError", "error": "MyImport is not a function", "backtrace": [' at Worker.perform (/path/to/worker:111:24)', ' at <anonymous>'], "failed_at": "Fri Dec 12 2014 14:01:16 GMT-0800 (PST)"}- To retrieve all failed jobs, use arguments:
await queue.failed(0, -1)
We use a try/catch pattern to catch errors in your jobs. If any job throws an uncaught exception, it will be caught, and the job's payload moved to the error queue for inspection. Do not use domain, process.on("exit"), or any other method of "catching" a process crash.
The error payload looks like:
{ worker: 'busted-worker-3',
queue: 'busted-queue',
payload: { class: 'busted_job', queue: 'busted-queue', args: [ 1, 2, 3 ] },
exception: 'ERROR_NAME',
error: 'I broke',
failed_at: 'Sun Apr 26 2015 14:00:44 GMT+0100 (BST)' }await queue.removeFailed(failedJob)
- the input
failedJobis an expanded node object representing the failed job, retrieved viaqueue.failed
await queue.retryAndRemoveFailed(failedJob)
- the input
failedJobis an expanded node object representing the failed job, retrieved viaqueue.failed - this method will instantly re-enqueue a failed job back to its original queue, and delete the failed entry for that job
By default, the scheduler will check for workers which haven't pinged redis in 60 minutes. If this happens, we will assume the process crashed, and remove it from redis. If this worker was working on a job, we will place it in the failed queue for later inspection. Every worker has a timer running in which it then updates a key in redis every timeout (default: 5 seconds). If your job is slow, but async, there should be no problem. However, if your job consumes 100% of the CPU of the process, this timer might not fire.
To modify the 60 minute check, change stuckWorkerTimeout when configuring your scheduler, ie:
const scheduler = new NodeResque.Scheduler({
stuckWorkerTimeout: (1000 * 60 * 60) // 1 hour, in ms
connection: connectionDetails
})Set your scheduler's stuckWorkerTimeout = false to disable this behavior.
const scheduler = new NodeResque.Scheduler({
stuckWorkerTimeout: false // will not fail jobs which haven't pinged redis
connection: connectionDetails
})Sometimes a worker crashes is a severe way, and it doesn't get the time/chance to notify redis that it is leaving the pool (this happens all the time on PAAS providers like Heroku). When this happens, you will not only need to extract the job from the now-zombie worker's "working on" status, but also remove the stuck worker. To aid you in these edge cases, await queue.cleanOldWorkers(age) is available.
Because there are no 'heartbeats' in resque, it is impossible for the application to know if a worker has been working on a long job or it is dead. You are required to provide an "age" for how long a worker has been "working", and all those older than that age will be removed, and the job they are working on moved to the error queue (where you can then use queue.retryAndRemoveFailed) to re-enqueue the job.
If you know the name of a worker that should be removed, you can also call await queue.forceCleanWorker(workerName) directly, and that will also remove the worker and move any job it was working on into the error queue. This method will still proceed for workers which are only partially in redis, indicting a previous connection failure. In this case, the job which the worker was working on is irrecoverably lost.
You may want to use node-resque to schedule jobs every minute/hour/day, like a distributed CRON system. There are a number of excellent node packages to help you with this, like node-schedule and node-cron. Node-resque makes it possible for you to use the package of your choice to schedule jobs with.
Assuming you are running node-resque across multiple machines, you will need to ensure that only one of your processes is actually scheduling the jobs. To help you with this, you can inspect which of the scheduler processes is currently acting as leader, and flag only the master scheduler process to run the schedule. A full example can be found at /examples/scheduledJobs.ts, but the relevant section is:
const NodeResque = require("node-resque");
const schedule = require("node-schedule");
const queue = new NodeResque.Queue({ connection: connectionDetails }, jobs);
const scheduler = new NodeResque.Scheduler({ connection: connectionDetails });
await scheduler.connect();
scheduler.start();
schedule.scheduleJob("10,20,30,40,50 * * * * *", async () => {
// do this job every 10 seconds, CRON style
// we want to ensure that only one instance of this job is scheduled in our environment at once,
// no matter how many schedulers we have running
if (scheduler.leader) {
console.log(">>> enqueuing a job");
await queue.enqueue("time", "ticktock", new Date().toString());
}
});Just like ruby's resque, you can write worker plugins. They look like this. The 4 hooks you have are beforeEnqueue, afterEnqueue, beforePerform, and afterPerform. Plugins are classes which extend NodeResque.Plugin
const { Plugin } = require("node-resque");
class MyPlugin extends Plugin {
constructor(...args) {
// @ts-ignore
super(...args);
this.name = "MyPlugin";
}
beforeEnqueue() {
// console.log("** beforeEnqueue")
return true; // should the job be enqueued?
}
afterEnqueue() {
// console.log("** afterEnqueue")
}
beforePerform() {
// console.log("** beforePerform")
return true; // should the job be run?
}
afterPerform() {
// console.log("** afterPerform")
}
}And then your plugin can be invoked within a job like this:
const jobs = {
add: {
plugins: [MyPlugin],
pluginOptions: {
MyPlugin: { thing: "stuff" },
},
perform: (a, b) => {
let answer = a + b;
return answer;
},
},
};notes
- You need to return
trueorfalseon the before hooks.trueindicates that the action should continue, andfalseprevents it. This is calledtoRun. - If you are writing a plugin to deal with errors which may occur during your resque job, you can inspect and modify
this.worker.errorin your plugin. Ifthis.worker.erroris null, no error will be logged in the resque error queue. - There are a few included plugins, all in the
src/plugins/*directory. You can write your own and include it like this:
const jobs = {
add: {
plugins: [require("Myplugin").Myplugin],
pluginOptions: {
MyPlugin: { thing: "stuff" },
},
perform: (a, b) => {
let answer = a + b;
return answer;
},
},
};The plugins which are included with this package are:
DelayQueueLock- If a job with the same name, queue, and args is already in the delayed queue(s), do not enqueue it again
JobLock- If a job with the same name, queue, and args is already running, put this job back in the queue and try later
QueueLock- If a job with the same name, queue, and args is already in the queue, do not enqueue it again
Retry- If a job fails, retry it N times before finally placing it into the failed queue
node-resque provides a wrapper around the Worker class which will auto-scale the number of resque workers. This will process more than one job at a time as long as there is idle CPU within the event loop. For example, if you have a slow job that sends email via SMTP (with low overhead), we can process many jobs at a time, but if you have a math-heavy operation, we'll stick to 1. The MultiWorker handles this by spawning more and more node-resque workers and managing the pool.
const NodeResque = require("node-resque");
const connectionDetails = {
pkg: "ioredis",
host: "127.0.0.1",
password: "",
};
const multiWorker = new NodeResque.MultiWorker(
{
connection: connectionDetails,
queues: ["slowQueue"],
minTaskProcessors: 1,
maxTaskProcessors: 100,
checkTimeout: 1000,
maxEventLoopDelay: 10,
},
jobs,
);
// normal worker emitters
multiWorker.on("start", (workerId) => {
console.log("worker[" + workerId + "] started");
});
multiWorker.on("end", (workerId) => {
console.log("worker[" + workerId + "] ended");
});
multiWorker.on("cleaning_worker", (workerId, worker, pid) => {
console.log("cleaning old worker " + worker);
});
multiWorker.on("poll", (workerId, queue) => {
console.log("worker[" + workerId + "] polling " + queue);
});
multiWorker.on("ping", (workerId, time) => {
console.log("worker[" + workerId + "] check in @ " + time);
});
multiWorker.on("job", (workerId, queue, job) => {
console.log(
"worker[" + workerId + "] working job " + queue + " " + JSON.stringify(job),
);
});
multiWorker.on("reEnqueue", (workerId, queue, job, plugin) => {
console.log(
"worker[" +
workerId +
"] reEnqueue job (" +
plugin +
") " +
queue +
" " +
JSON.stringify(job),
);
});
multiWorker.on("success", (workerId, queue, job, result) => {
console.log(
"worker[" +
workerId +
"] job success " +
queue +
" " +
JSON.stringify(job) +
" >> " +
result,
);
});
multiWorker.on("failure", (workerId, queue, job, failure) => {
console.log(
"worker[" +
workerId +
"] job failure " +
queue +
" " +
JSON.stringify(job) +
" >> " +
failure,
);
});
multiWorker.on("error", (workerId, queue, job, error) => {
console.log(
"worker[" +
workerId +
"] error " +
queue +
" " +
JSON.stringify(job) +
" >> " +
error,
);
});
multiWorker.on("pause", (workerId) => {
console.log("worker[" + workerId + "] paused");
});
multiWorker.on("multiWorkerAction", (verb, delay) => {
console.log(
"*** checked for worker status: " +
verb +
" (event loop delay: " +
delay +
"ms)",
);
});
multiWorker.start();The Options available for the multiWorker are:
connection: The redis configuration options (same as worker)queues: Array of ordered queue names (or*) (same as worker)minTaskProcessors: The minimum number of workers to spawn under this multiWorker, even if there is no work to do. You need at least one, or no work will ever be processed or checkedmaxTaskProcessors: The maximum number of workers to spawn under this multiWorker, even if the queues are long and there is available CPU (the event loop isn't entirely blocked) to this node process.checkTimeout: How often to check if the event loop is blocked (in ms) (for adding or removing multiWorker children),maxEventLoopDelay: How long the event loop has to be delayed before considering it blocked (in ms),
This package was featured heavily in this presentation I gave about background jobs + node.js. It contains more examples!
- Most of this code was inspired by / stolen from coffee-resque and coffee-resque-scheduler. Thanks!
- This Resque package aims to be fully compatible with Ruby's Resque and implementations of Resque Scheduler. Other packages from other languages may conflict.
- If you are looking for a UI to manage your Resque instances in nodejs, check out ActionHero's Resque UI