![]()


erdtree is a modern, cross-platform, multi-threaded, and general purpose filesystem and disk-usage utility that is aware of .gitignore and hidden file rules.
The following are some feature highlights:
- Reports disk usage using a variety of metrics: bytes (logical or physical), blocks (Unix-only), word-count, or line-count.
- Supports an
ls -l-like view with information about owners, group, file permission, etc. (Unix-only). - Respects hidden file and gitignore rules by default.
- Supports regular expressions and glob based searching by file-type.
- Comes with several layouts: a reverse tree output, a
tree-like output, or adu-like output. - Granular sorting capabilities.
- Supports icons.
- Colorized with
LS_COLORS.
You can think of erdtree as a little bit of du, tree, find, wc and ls.

- Usage
- Installation
- Documentation
- Comparisons against similar programs
- Rules for contributing
- Security policy
- Questions you might have
$ erd --help
erdtree (erd) is a cross-platform, multi-threaded, and general purpose filesystem and disk usage utility.
Usage: erd [OPTIONS] [DIR]
Arguments:
[DIR]
Directory to traverse; defaults to current working directory
Options:
-c, --config <CONFIG>
Use configuration of named table rather than the top-level table in .erdtree.toml
-C, --color <COLOR>
Mode of coloring output
[default: auto]
Possible values:
- none: Print plainly without ANSI escapes
- auto: Attempt to colorize output
- force: Turn on colorization always
-d, --disk-usage <DISK_USAGE>
Print physical or logical file size
[default: physical]
Possible values:
- logical:
How many bytes does a file contain
- physical:
How many actual bytes on disk, taking into account blocks, sparse files, and compression
- line:
How many total lines a file contains
- word:
How many total words a file contains
- block:
How many blocks are allocated to store the file
-f, --follow
Follow symlinks
-H, --human
Print disk usage in human-readable format
-i, --no-ignore
Do not respect .gitignore files
-I, --icons
Display file icons
-l, --long
Show extended metadata and attributes
--group
Show file's groups
--ino
Show each file's ino
--nlink
Show the total number of hardlinks to the underlying inode
--octal
Show permissions in numeric octal format instead of symbolic
--time <TIME>
Which kind of timestamp to use; modified by default
Possible values:
- create: Time created (alias: ctime)
- access: Time last accessed (alias: atime)
- mod: Time last modified (alias: mtime)
--time-format <TIME_FORMAT>
Which format to use for the timestamp; default by default
Possible values:
- iso:
Timestamp formatted following the iso8601, with slight differences and the time-zone omitted
- iso-strict:
Timestamp formatted following the exact iso8601 specifications
- short:
Timestamp only shows date without time in YYYY-MM-DD format
- default:
Timestamp is shown in DD MMM HH:MM format
-L, --level <NUM>
Maximum depth to display
-p, --pattern <PATTERN>
Regular expression (or glob if '--glob' or '--iglob' is used) used to match files
--glob
Enables glob based searching
--iglob
Enables case-insensitive glob based searching
-t, --file-type <FILE_TYPE>
Restrict regex or glob search to a particular file-type
Possible values:
- file: A regular file
- dir: A directory
- link: A symlink
-P, --prune
Remove empty directories from output
-s, --sort <SORT>
How to sort entries
[default: size]
Possible values:
- name: Sort entries by file name in lexicographical order
- rname: Sort entries by file name in reversed lexicographical order
- size: Sort entries by size smallest to largest, top to bottom
- rsize: Sort entries by size largest to smallest, bottom to top
- access: Sort entries by newer to older Accessing Date
- raccess: Sort entries by older to newer Accessing Date
- create: Sort entries by newer to older Creation Date
- rcreate: Sort entries by older to newer Creation Date
- mod: Sort entries by newer to older Alteration Date
- rmod: Sort entries by older to newer Alteration Date
--dir-order <DIR_ORDER>
Sort directories before or after all other file types
[default: none]
Possible values:
- none: Directories are ordered as if they were regular nodes
- first: Sort directories above files
- last: Sort directories below files
-T, --threads <THREADS>
Number of threads to use
[default: 10]
-u, --unit <UNIT>
Report disk usage in binary or SI units
[default: bin]
Possible values:
- bin: Displays disk usage using binary prefixes
- si: Displays disk usage using SI prefixes
-x, --one-file-system
Prevent traversal into directories that are on different filesystems
-y, --layout <LAYOUT>
Which kind of layout to use when rendering the output
[default: regular]
Possible values:
- regular: Outputs the tree with the root node at the bottom of the output
- inverted: Outputs the tree with the root node at the top of the output
- flat: Outputs a flat layout using paths rather than an ASCII tree
- iflat: Outputs an inverted flat layout with the root at the top of the output
-., --hidden
Show hidden files
--no-git
Disable traversal of .git directory when traversing hidden files
--completions <COMPLETIONS>
Print completions for a given shell to stdout
[possible values: bash, elvish, fish, powershell, zsh]
--dirs-only
Only print directories
--no-config
Don't read configuration file
--no-progress
Hides the progress indicator
--suppress-size
Omit disk usage from output
--truncate
Truncate output to fit terminal emulator window
-h, --help
Print help (see a summary with '-h')
-V, --version
Print version
-l, --long and all of its arguments are currently not available on Windows, but support for a Windows variant is planned.
Make sure you have Rust and its toolchain installed.
$ cargo install erdtree
The Windows version relies on some experimental features in order to properly support hard-link detection. If you want to build from crates.io you'll first need to install the nightly toolchain before installing erdtree:
$ rustup toolchain install nightly-2023-06-11
Thereafter:
$ cargo +nightly-2023-03-05 install erdtree
$ brew install erdtree
$ scoop install erdtree
$ pkgin install erdtree
Binaries for common architectures can be downloaded from latest releases.
If you'd like the latest features that are on master but aren't yet included as part of a release:
$ cargo install --git https://github.com/solidiquis/erdtree --branch master
Other means of installation to come.
If erdtree's out-of-the-box defaults don't meet your specific requirements, you can set your own defaults using a configuration file.
The configuration file currently comes in two flavors: .erdtreerc (to be deprecated) and .erdtree.toml. If you have both,
.erdtreerc will take precedent and .erdtree.toml will be disregarded, but please note that .erdtreerc will be deprecated in the near future. There is
no reason to have both.
erdtree will look for .erdtree.toml in any of the following locations:
On Unix-systems:
$ERDTREE_TOML_PATH
$XDG_CONFIG_HOME/erdtree/.erdtree.toml
$XDG_CONFIG_HOME/.erdtree.toml
$HOME/.config/erdtree/.erdtree.toml
$HOME/.erdtree.toml
On Windows:
%APPDATA%\erdtree\.erdtree.toml
Here and below is an example of a valid .erdtree.toml:
icons = true
human = true
# Compute file sizes like `du`
# e.g. `erd --config du`
[du]
disk_usage = "block"
icons = true
layout = "flat"
no-ignore = true
no-git = true
hidden = true
level = 1
# Do as `ls -l`
# e.g. `erd --config ls`
[ls]
icons = true
human = true
level = 1
suppress-size = true
long = true
# How many lines of Rust are in this code base?
# e.g. `erd --config rs`
[rs]
disk-usage = "line"
level = 1
pattern = "\\.rs$".erdtree.toml supports multiple configurations. The top-level table is the main config that will be applied without additional arguments.
If you wish to use a separate configuration, create a named table like du above, set your arguments, and invoke it like so:
$ erd --config du
# equivalent to
$ erd --disk-usage block --icons --layout flat --no-ignore --no-git --hidden --level 1
As far as the arguments go there are only three rules you need to be aware of:
.erdtree.tomlonly accepts long-named arguments without the preceding "--".- Types are enforced, so numbers are expected to be numbers, booleans are expected to be booleans, strings are expected to be strings, and so on and so forth.
snake_caseandkebap-caseworks.
erdtree will look for a configuration file in any of the following locations:
On Linux/Mac/Unix-like:
$ERDTREE_CONFIG_PATH$XDG_CONFIG_HOME/erdtree/.erdtreerc$XDG_CONFIG_HOME/.erdtreerc$HOME/.config/erdtree/.erdtreerc$HOME/.erdtreerc
On Windows:
$ERDTREE_CONFIG_PATH%APPDATA%\erdtree\.erdtreerc
The format of a config file is as follows:
- Every line is an
erdtreeoption/argument. - Lines starting with
#are considered comments and are thus ignored.
Arguments passed to erdtree on the command-line will override those found in .erdtreerc.
Click here for an example .erdtreerc.
If you have a config that you would like to ignore without deleting you can use --no-config.
If multiple hardlinks that point to the same inode are in the same file-tree, all will be included in the output but only one is considered when computing overall disk usage.
-f, --follow
Follow symlinks
Symlinks when followed will have their targets (and descendants) counted towards total disk usage, otherwise the size of the symlink itself will be reported. If a symlink's target happens to be in the same file-tree as the symlink itself, the target and its descendants will not be double-counted towards the total disk-usage. When a symlink to a directory is followed all of the box-drawing characters of its descendants will be painted in a different color for better visual feedback:
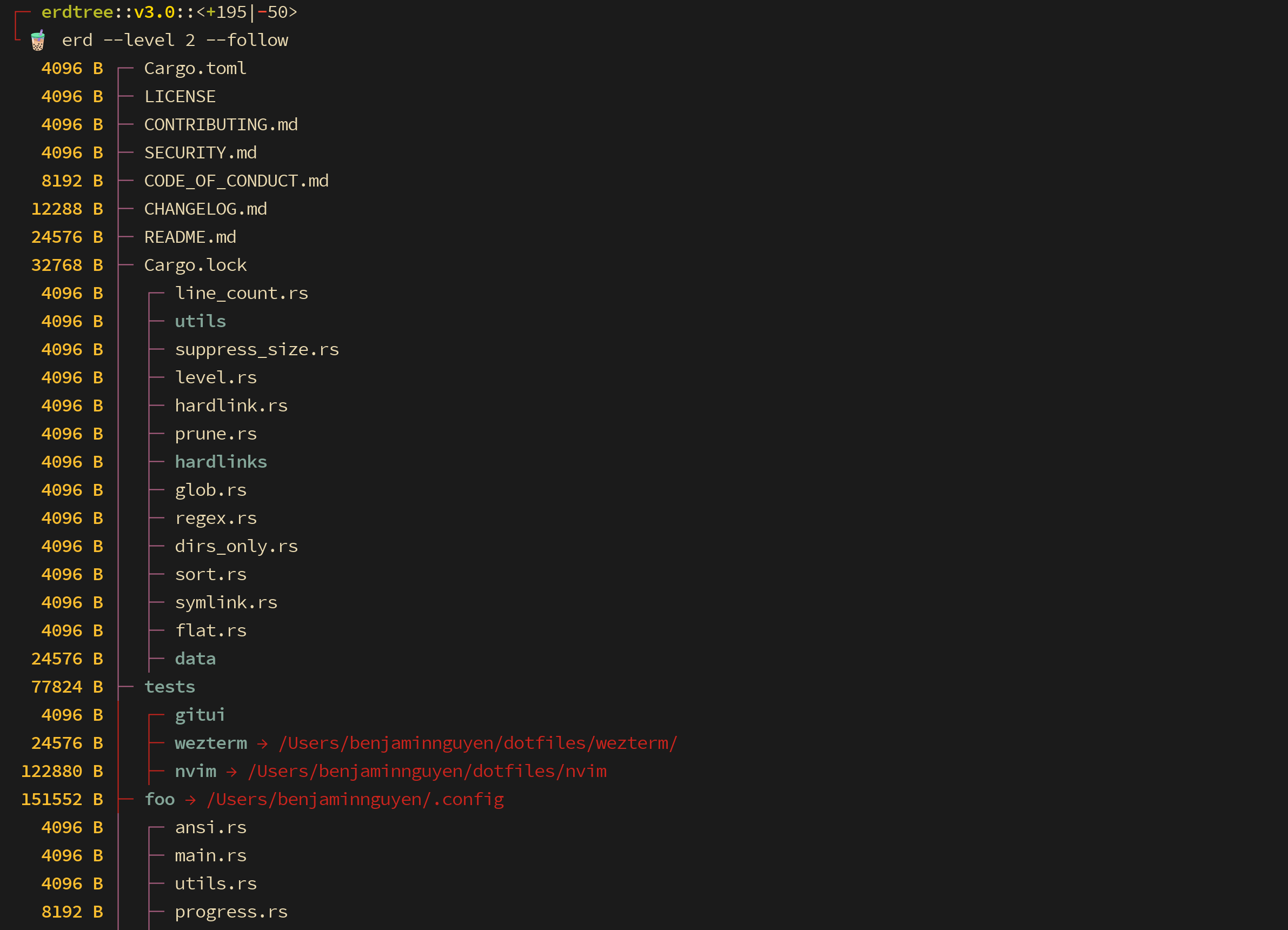
By default disk usage is reported as the total amount of physical bytes stored on the disk. To get the human-readable form:
-H, --human
Print disk usage in human-readable format
When using the human-readable form, binary units (e.g. 1 KiB = 1024 B) are reported by default. If you prefer SI units (1 KB = 1000 B) you can use the following:
-u, --unit <UNIT>
Report disk usage in binary or SI units
[default: bin]
Possible values:
- bin: Displays disk usage using binary prefixes
- si: Displays disk usage using SI prefixes
Additionally, various other disk usage metrics may be used instead of physical bytes. You have the following metrics available:
-d, --disk-usage <DISK_USAGE>
Print physical or logical file size
[default: physical]
Possible values:
- logical:
How many bytes does a file contain
- physical:
How many actual bytes on disk, taking into account blocks, sparse files, and compression
- line:
How many total lines a file contains
- word:
How many total words a file contains
- block:
How many blocks are allocated to store the file
Lastly, if you'd like to omit disk usage from the output:
--suppress-size
Omit disk usage from output
Physical size takes into account compression, sparse files, and actual blocks allocated to a particular file. Logical size just reports the total number of bytes in a file.
If you want the same exact disk usage reporting as du, you can do the following:
$ erd --layout flat --disk-usage block --no-ignore --hidden --level
or in short-hand
$ erd -y flat -d block -i -.

When opting to report disk usage in either word and line count, unlike wc, erdtree will make no attempt to count the amount of words or lines for files that cannot
be encoded as a UTF-8 string such as a JPEG file. For cases such as these the line or total word-count will just appear as empty.
Additionally, the word and line-count of directories are the summation of all of the line/word-counts of its descendents.
erdtree comes with four layouts:
-y, --layout <LAYOUT>
Which kind of layout to use when rendering the output
[default: regular]
Possible values:
- regular: Outputs the tree with the root node at the bottom of the output
- inverted: Outputs the tree with the root node at the top of the output
- flat: Outputs a flat layout using paths rather than an ASCII tree
- iflat: Outputs an inverted flat layout with the root at the top of the output
- The
invertedlayout a more traditionaltree-like layout where the root node is at the very top of the output. - The
regularlayout is a tree with the root node at the bottom of the output for quick information about total disk usage. - The
flatlayout is a tree-less output that more closely resemblesdu.
-i, --no-ignore
Do not respect .gitignore files
.gitignore is respected by default but can be disregarded with the above argument. .gitignore rules are also respected on a per directory basis, so
every directory that is encountered during traversal that has a .gitignore will also be considered.
If .gitignore is respected any file that is ignored will not be included in the total disk usage.
Hidden files
-., --hidden
Show hidden files
--no-git
Disable traversal of .git directory when traversing hidden files
Hidden files ignored by default but can be included with -., --hidden. If opting in to show hidden files .git is included; to exclude
it use --no-git.
If hidden files are ignored it will not be included in the total disk usage.
-I, --icons Display file icons
Icons are an opt-in feature because for icons to render properly it is required that the font you have hooked up to your terminal emulator contains the glyphs necessary to properly render icons.
If your icons look something like this:
![]()
this means that the font you are using doesn't include the relevant glyphs. To resolve this issue download a NerdFont and hook it up to your terminal emulator.
Directories are fully traversed by default. To limit the maximum depth:
-L, --level <NUM>
Maximum depth to display
Limiting the maximum depth to display will not affect the total disk usage report nor the file count report.
Sometimes empty directories may appear in the output. To remove them:
-P, --prune
Remove empty directories from output
Various sorting methods are provided:
-s, --sort <SORT>
How to sort entries
[default: size]
Possible values:
- name: Sort entries by file name in lexicographical order
- rname: Sort entries by file name in reversed lexicographical order
- size: Sort entries by size smallest to largest, top to bottom
- rsize: Sort entries by size largest to smallest, bottom to top
- access: Sort entries by newer to older Accessing Date
- raccess: Sort entries by older to newer Accessing Date
- create: Sort entries by newer to older Creation Date
- rcreate: Sort entries by older to newer Creation Date
- mod: Sort entries by newer to older Alteration Date
- rmod: Sort entries by older to newer Alteration Date
--dir-order <DIR_ORDER>
Sort directories before or after all other file types
[default: none]
Possible values:
- none: Directories are ordered as if they were regular nodes
- first: Sort directories above files
- last: Sort directories below files
--dir-order and --sort acan be used independently of each other.
You output only directories with:
--dirs-only
Only print directories
This will not affect total disk usage.
Currently only available on Unix-like platforms. Support for Windows is planned.
erdtree supports an ls -l like long-view:
-l, --long
Show extended metadata and attributes
--group
Show file's groups
--ino
Show each file's ino
--nlink
Show the total number of hardlinks to the underlying inode
--octal
Show permissions in numeric octal format instead of symbolic
--time <TIME>
Which kind of timestamp to use; modified by default
Possible values:
- create: Time created (alias: ctime)
- access: Time last accessed (alias: atime)
- mod: Time last modified (alias: mtime)
--time-format <TIME_FORMAT>
Which format to use for the timestamp; default by default
Possible values:
- iso:
Timestamp formatted following the iso8601, with slight differences and the time-zone omitted
- iso-strict:
Timestamp formatted following the exact iso8601 specifications
- short:
Timestamp only shows date without time in YYYY-MM-DD format
- default:
Timestamp is shown in DD MMM HH:MM format
By default the columns shown in the order of left to right are:
- permissions in symbolic notation
- The file owner
- The date the file was last modified (or created or last accessed)
Filtering for particular files using a regular expression or glob is supported using the following:
-p, --pattern <PATTERN>
Regular expression (or glob if '--glob' or '--iglob' is used) used to match files
--glob
Enables glob based searching
--iglob
Enables case-insensitive glob based searching
-t, --file-type <FILE_TYPE>
Restrict regex or glob search to a particular file-type
Possible values:
- file: A regular file
- dir: A directory
- link: A symlink
If --file-type is not provided when filtering, regular files (file) is the default.
Additionally, any file that is filtered out will be excluded from the total disk usage.
Lastly, when applying a regular expression or glob to directories, all of its descendents regardless of file-type will be included in the output.
If you wish to only show directories you may use --dirs-only.
References:
In instances where the output does not fit the terminal emulator's window, the output itself may be rendered incoherently:

In these situations the following may be used:
--truncate
Truncate output to fit terminal emulator window

By default colorization of the output is enabled if stdout is found to be a tty. If the output is not a tty such in the case of redirection to a file or piping to another command then colorization is disabled.
If, however, the default behavior doesn't suit your needs you have control over the modes of colorization:
-C, --color <COLOR>
Mode of coloring output
[default: auto]
Possible values:
- none: Print plainly without ANSI escapes
- auto: Attempt to colorize output
- force: Turn on colorization always
erdtree also supports NO_COLOR.
The amount of threads used by erdtree can be adjusted with the following:
-T, --threads <THREADS> Number of threads to use [default: 3]
A common question that gets asked is how parallelism benefits disk reads when filesystem I/O is processed serially.
While this is true, parallelism still results in improved throughput due to the fact that disks have a queue depth
that, when saturated, allows requests to be processed in aggregate keeping the disk busy as opposed to having it wait on erdtree to do CPU-bound processing
in between requests. Additionally these threads aren't just parallelizing disk reads, they're also parallelizing the processing of the retrieved data.
It should be noted however that performance, as a function of thread-count, is asymptotic in nature (see Amdahl's Law) so you'll quickly reach a point of dimishing returns after a certain thread-count threshold as you'd be paying the cost of managing a larger threadpool with no added benefit.
For empirical data on the subject checkout this article.
--completions is used to generate auto-completions for common shells so that the tab key can attempt to complete your command or give you hints; where you place the output highly depends on your shell as well as your setup. In my environment where I use zshell with oh-my-zsh, I would install completions like so:
$ et --completions zsh > ~/.oh-my-zsh/completions/_erd
$ source ~/.zshrc
If you are traversing a directory that contains mount points to other filesystems that you do not wish to traverse, use the following:
-x, --one-file-system
Prevent traversal into directories that are on different filesystems
For rules on how to contribute please refer to CONTRIBUTING.md.
For information regarding erdtree's security policy and how to report a security vulnerability please refer to SECURITY_POLICY.md
It goes without saying that the following programs are all amazing in their own right and were highly influential in erdtree's development. While each of the following are highly
specialized in acting as modern replacements for their Unix progenitors, erdtree aims to take bits and pieces of each that people use most frequently and assemble them into a unified highly practical tool.
No case will be made as to why erdtree should be preferred over X, Y, or Z, but because of some notable similarities with the following programs it is worth a brief
comparison.
exa and erdtree are similar in that they both have tree-views and show information about permissions, owners, groups, etc..
The disadvantage of exa, however, is that it does not provide information about the disk usages of directories, which
also makes sorting files by size a little dubious. The advantage exa has over erdtree, however, is in the fact that exa is much more comprehensive as an ls replacement.
Both tools are complimentary to one another and it is encouraged that you have both in your toolkit.
dua is a fantastic interactive disk usage tool that serves as a modern alternative to
ncdu. If you're in the mood for something interactive and solely focused on disk usage then dua might suit you more.
If you're interested in file permissions and doing quick static analysis of your disk usage without spinning up an entire interactive UI then perhaps consider erdtree.
dust is another fantastic tool that is closer in geneology to the traditional du command. If you're strictly looking for
a modern replacement to du then dust is a great choice.
fd is much more comprehensive as a general finder tool, offering itself as a modern replacement to find. If you're looking for more granularity in your ability to search beyond just globbing, regular
expressions, and the three basic file types (files, directories, and symlinks) then fd is the optimal choice.
Q: Why did you make this? It's totally unnecessary.
A: Ennui.
Q: Why is it called erdtree?
A: It's a reference to an object of worship in Elden Ring.
Q: Is it any good?
A: Yes.
Q: Why is there no mention of this project being blazingly fast or written in Rust? Is it slow or something?
A: Okay fine. erdtree is written in Rust and is blazingly fast.
