- Acknowledgements
- Data Structures
- Dynamic Programming
- Greedy Algorithms
- Algorithms
- Bit Manipulation
- Runtime Analysis
- Definitions
- Number Theory
- Problems
- Shortest Path Algo
- Optimizations
Want to give a huge shoutout to Kevin Naughton Jr and Kumail Naqvi who were key figures in my design and notes for this repository
https://github.com/kdn251 https://github.com/kumailn
- To find implementations of numerous algorithms and data structures, I would suggest checking out the github page below which contains repositories for numerous different languages such as Python, Java, C++. C, Go, Javascript, and even more!
https://github.com/TheAlgorithms
- A Linked List is a linear collection of data elements, called nodes, each pointing to the next node by means of a pointer.
- Is a data structure consisting of a group of nodes which together represent a sequence.
- Singly-linked list: linked list in which each node points to the next node and the last node points to null
- Doubly-linked list: linked list in which each node has two pointers, p and n, such that p points to the previous node and n points to the next node; the last node's n pointer points to null
- Circular-linked list: linked list in which each node points to the next node and the last node points back to the first node
- Time Complexity:
- Access:
O(n) - Search:
O(n) - Insert:
O(1) - Remove:
O(1)
- Access:
- A Stack is a collection of elements, with two principle operations: push, which adds to the collection, and pop, which removes the most recently added element
- Last in, first out data structure (LIFO): the most recently added object is the first to be removed
- Time Complexity:
- Access:
O(n) - Search:
O(n) - Insert:
O(1) - Remove:
O(1)
- Access:

- A Queue is a collection of elements, supporting two principle operations: enqueue, which inserts an element into the queue, and dequeue, which removes an element from the queue
- First in, first out data structure (FIFO): the oldest added object is the first to be removed
- Time Complexity:
- Access:
O(n) - Search:
O(n) - Insert:
O(1) - Remove:
O(1)
- Access:
- A Tree is an undirected, connected, acyclic graph
- A tree with a designated root node where every node either points away from or towards the root node
- Each node has at most two children, which are referred to as the left child and right child
- Full Tree: a tree in which every node has either 0 or 2 children
- Complete Tree: a binary tree in which every level except possibly the last is full and all nodes in the last level are as far left as possible
- Perfect Binary Tree: a binary tree in which all interior nodes have two children and all leave have the same depth

- A type of binary tree which maintains the property that the value in each node must be greater than or equal to any value stored in the left sub-tree, and less than or equal to any value stored in the right sub-tree
- Time Complexity:
- Access:
O(log(n)) - Search:
O(log(n)) - Insert:
O(log(n)) - Remove:
O(log(n))
- Access:

- Resolves the issue of trees being unbalanced with huge difference in size of subtrees
- Height of a node - length of longest path from the node to a leaf
- Requires heights of left and right children of every node to differ by at most of 1
Insertions:
- Regular BST Insertions
- Fix AVL property
- A trie, sometimes called a radix or prefix tree, is a kind of search tree that is used to store a dynamic set or associative array where the keys are usually strings.
- No node in the tree stores the key associated with that node; instead, its position in the tree defines the key with which it is associated.
- All the descendants of a node have a common prefix of the string associated with that node, and the root is associated with the empty String.
class TrieNode {
HashMap<Character, TrieNode> children;
String/char content;
boolean isWord;
}

- A Fenwick tree, sometimes called a binary indexed tree, is a tree in concept, but in practice is implemented as an implicit data structure using an array. Given an index in the array representing a vertex, the index of a vertex's parent or child is calculated through bitwise operations on the binary representation of its index. Each element of the array contains the pre-calculated sum of a range of values, and by combining that sum with additional ranges encountered during an upward traversal to the root, the prefix sum is calculated
- Time Complexity:
- Range Sum:
O(log(n)) - Update:
O(log(n))
- Range Sum:

- A Segment tree, is a tree data structure for storing intervals, or segments. It allows querying which of the stored segments contain a given point
- Time Complexity:
- Range Query:
O(log(n)) - Update:
O(log(n))
- Range Query:

- A Heap is a specialized tree based structure data structure that satisfies the heap property: if A is a parent node of B, then the key (the value) of node A is ordered with respect to the key of node B with the same ordering applying across the entire heap. A heap can be classified further as either a "max heap" or a "min heap". In a max heap, the keys of parent nodes are always greater than or equal to those of the children and the highest key is in the root node. In a min heap, the keys of parent nodes are less than or equal to those of the children and the lowest key is in the root node
- Time Complexity:
- Access Max / Min:
O(1) - Insert:
O(log(n)) - Remove Max / Min:
O(log(n))
- Access Max / Min:

- Hashing is used to map data of an arbitrary size to data of a fixed size. The values returned by a hash function are called hash values, hash codes, or simply hashes. If two keys map to the same value, a collision occurs
- Hash Map: a hash map is a structure that can map keys to values. A hash map uses a hash function to compute an index into an array of buckets or slots, from which the desired value can be found.
-
Separate Chaining: in separate chaining, each bucket is independent, and contains a list of entries for each index. The time for hash map operations is the time to find the bucket (constant time), plus the time to iterate through the list
-
Open Addressing: in open addressing, when a new entry is inserted, the buckets are examined, starting with the hashed-to-slot and proceeding in some sequence, until an unoccupied slot is found. The name open addressing refers to he fact that the location of an item is not always determined by its hash value
-
Time Complexity:
- value lookup: O(1)
- insertion: O(1)
- deletion: O(1)

- A Graph is an ordered pair of G = (V, E) comprising a set V of vertices or nodes together with a set E of edges or arcs.
- The set E of edges are a 2-element subsets of V (i.e. an edge is associated with two vertices, and that association takes the form of the unordered pair comprising those two vertices)
- a graph in which the adjacency relation is symmetric. So if there exists an edge from node u to node v (u -> v), then it is also the case that there exists an edge from node v to node u (v -> u)
- A tree is an undirected graph with no cycles
- a graph in which the adjacency relation is not symmetric. So if there exists an edge from node u to node v (u -> v), this does not imply that there exists an edge from node v to node u (v -> u)
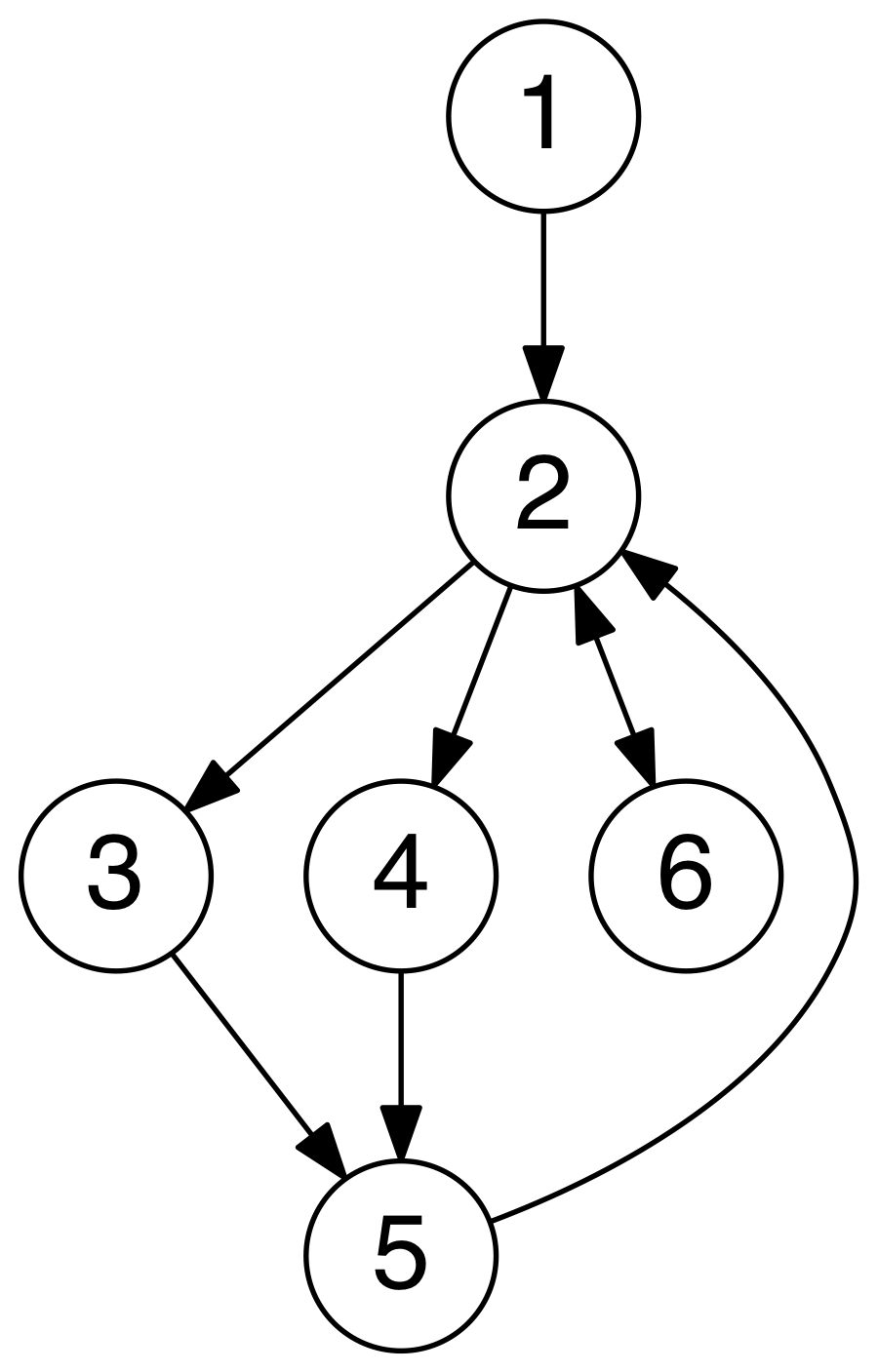
- A graph with edges that have weights to represent a value such as cost, distance, quantity, etc

- Directed graph with no cycles
- Used commonly in representing structures with dependencies such as scheduler, build system, course prerequisites, etc.
- One whose vertices can be split into two independent groups U, V such that every edge connects between U and V

- One where there is an edge between every pair of nodes
- It is denoted using Kn as shown by images below

Adjacency Matrix:
- A matrix of size n x n where n is the number of nodes in the graph
- For an adjacency matrix m, the cell m[i][j] represents the weight of going from node i to node j
| Pros | Cons |
|---|---|
| Space efficient for dense graphs (complete graphs) | Requires O(V2) space |
| Edge weight lookup is O(1) | Iterating over all the edges takes O(V2) time |
| Simplest graph representation |

Adjacency Lists :
- A way to represent a graph as a map from nodes to lists of edges.
- Each node has their own list that contains each edge and weight of the edge
| Pros | Cons |
|---|---|
| Space efficient for sparse graphs | Not very space efficient for dense graphs |
| Iterating over all the edges is efficient | Edge weight lookup is O(E) |
| Slightly more complex graph representation |

Edge List :
- Way to represent a graph simply as an unordered list of edges
- Assumes the notation for any triplet
-
Will always result in optimal solution, it would go through all possible solutions and return optimal solution
-
Can think of it sort of like "careful brute force"
-
Divides the problem into sub-problems similar to Divide and Conquer
- Difference is that there are overlapping/repeating subproblems (not the case in D&C)
-
Store solutions of sub-problems so in the future, you can just use the solution instead of having to calculate again
-
Very rare scenarios in which DP can be used for a solution
-
DP consists of recursion + memoization + guessing
- Key is that guessing means guessing/trying all ways
writes down "1+1+1+1+1+1+1+1 =" on a sheet of paper "What's that equal to?" counting "Eight!" writes down another "1+" on the left "What about that?" quickly "Nine!" "How'd you know it was nine so fast?" "You just added one more" "So you didn't need to recount because you remembered there were eight!
Dynamic Programming is just a fancy way to say 'remembering stuff to save time later'" By the way this remembering of values is called momoization, the hard part comes with knowing what to memoize and how to apply it
- 3 ways:
- Recursion
- Store (Memoize)
- Bottom-up
- Naive Recursive
- Memoization - can be done on any recursive algorithm
- Whenever we compute a fibonacci number, we compute it and store it in dictionary
- Before we compute a fibonacci number, we first check to see if it is in dictionary and if it is then, we return it
- Don't need to worry about recurrence and the running time can be broken down into O(n) = # of subproblems * (Time each subproblem takes) O(n) in Fibonacci case since there are n subproblems and each take constant or O(1) time
memo = {} // dictionary where stored values will be
fib(n):
if n in memo:
return memo[n]
if n <= 2:
f = 1
else:
f = fib(n-1)+fib(n-2)
memo[n]=f
return f
- Bottom-up
- Does exact same computation as memoized version
topological sort of the subproblem dependency DAG
memo = {} // dictionary where stored values will be
fib(n):
for k in range(1,n+1):
if k <= 2:
f = 1
else:
f = fib[n-1]+fib[n-2]
memo[k]=f
return memo[n]
Dynamic programming is helpful for solving optimization problems, so often, the best way to recognize a problem as solvable by dynamic programming is to recognize that a problem is an optimization problem.
Notice how many of the problems are optimization problems. With optimization problems, you see terms like shortest/longest, minimized/maximized, least/most, fewest/greatest, biggest/smallest, etc.
When you see these kind of terms, the problem may ask for a specific number (like "find the minimum number of edit operations") or it may ask for a result (like "find the longest common subsequence"). The latter type of problem is harder to recognize as a dynamic programming problem, so you have to pay attention to anything that sounds like optimization.
When you have an optimization problem, first identify what you're optimizing for. Once you realize what you're optimizing for, you have to decide how easy it is to perform that optimization. Sometimes, the greedy approach is sufficient for an optimal solution. If the problem seems pretty difficult and you would have trouble coming up with the answer on your own without a computer or calculus, then dynamic programming is probably a good candidate.
Dynamic programming simply takes the brute force approach, identifies repeated work, and eliminates the repetition. So before you even start to formulate the problem as a dynamic programming problem, think about what the brute force solution might look like. Could there possibly be repeated substeps in the brute force solution? If so, try to formulate your problem as a dynamic programming problem.
- Greedy Algorithms are algorithms that make locally optimal choices at each step in the hope of eventually reaching the globally optimal solution
- Divides the problem into sub-problems similar to Divide and Conquer
- Problems must exhibit two properties in order to implement a Greedy solution:
- Optimal Substructure
- An optimal solution to the problem contains optimal solutions to the given problem's subproblems
- The Greedy Property
- An optimal solution is reached by "greedily" choosing the locally optimal choice without ever reconsidering previous choices
- Example - Coin Change
- Given a target amount V cents and a list of denominations of n coins, i.e. we have coinValue[i] (in cents) for coin types i from [0...n - 1], what is the minimum number of coins that we must use to represent amount V? Assume that we have an unlimited supply of coins of any type
- Coins - Penny (1 cent), Nickel (5 cents), Dime (10 cents), Quarter (25 cents)
- Assume V = 41. We can use the Greedy algorithm of continuously selecting the largest coin denomination less than or equal to V, subtract that coin's value from V, and repeat.
- V = 41 | 0 coins used
- V = 16 | 1 coin used (41 - 25 = 16)
- V = 6 | 2 coins used (16 - 10 = 6)
- V = 1 | 3 coins used (6 - 5 = 1)
- V = 0 | 4 coins used (1 - 1 = 0)
- Using this algorithm, we arrive at a total of 4 coins which is optimal
- Stable:
No - Time Complexity:
- Best Case:
O(nlog(n)) - Worst Case:
O(n<sup>2</sup>) - Average Case:
O(nlog(n))
- Best Case:

- Mergesort is also a divide and conquer algorithm. It continuously divides an array into two halves, recurses on both the left subarray and right subarray and then merges the two sorted halves
- Stable:
Yes - Time Complexity:
- Best Case:
O(nlog(n)) - Worst Case:
O(nlog(n)) - Average Case:
O(nlog(n))
- Best Case:

- Bucket Sort is a sorting algorithm that works by distributing the elements of an array into a number of buckets. Each bucket is then sorted individually, either using a different sorting algorithm, or by recursively applying the bucket sorting algorithm
- Time Complexity:
- Best Case:
Ω(n + k) - Worst Case:
O(n<sup>2</sup>) - Average Case:
Θ(n + k)
- Best Case:

- Radix Sort is a sorting algorithm that like bucket sort, distributes elements of an array into a number of buckets. However, radix sort differs from bucket sort by 're-bucketing' the array after the initial pass as opposed to sorting each bucket and merging
- Time Complexity:
- Best Case:
Ω(nk) - Worst Case:
O(nk) - Average Case:
Θ(nk)
- Best Case:
- A graph traversal algorithm which explores as far as possible along each branch/path before backtracking
- Can be done using a stack and an array of visited nodes
- Choose an unvisited node from current node/location until that is not possible which is when algorithm has you backtrack (hence why we use a stack and not a queue)
- Can augment the algorithm to...
- Compute a graph's minimum spanning tree
- Detect and find cycles in a graph
- Check if a graph is bipartite
- Find strongly connected components
- Topologically sort the nodes of a graph
- Find bridges and articulation points
- Finding augmenting paths in a flow network
- Generate mazes
- Time Complexity:
O(V + E)
# Global or class scope variables
n = number of nodes in the graph
g = adjacency list representing graph
visited = [false, ..., false] # size n
function dfs(root):
if visited[root]: return
visited[root] = true
neighbours = graph[root]
for next in neighbours:
dfs(next)

- A graph traversal algorithm which explores the neighbor nodes first, before moving to the next level neighbors
- Can be done using a queue and an array of visited nodes
- Used for level order problems (ie. )
- Particularly useful for
- Finding the shortest path on unweighted graphs
- Time Complexity:
O(V + E)
Python using a list as a queue
Q = []
Q.append(root)
visited = [root]
while len(Q) > 0:
nodes = []
for i in range(len(Q)):
node = Q.pop(0)
visited.append(node)
if node.left != None: Q.append(node.left)
if node.right != None: Q.append(node.right)
// Do your calculation/task on each node
- Topological Sort is the linear ordering of a directed acyclic graph's nodes such that for every edge from node u to node v, u comes before v in the ordering
- Every tree has a toplogical ordering since they don't contain any cycles
- Many real world situations can be modelled as such where some step must happen prior to another step
- School class prerequisites
- Event scheduling
- Assembly Instructions
- Topological orders are not unique
- Can be a fancy way of saying that graph can be organized in a line such that all edges go from left to right
- Steps:
- Pick an unvisisted node
- Perform DFS, exploring only unvisited nodes
- On the recursive callback, add the current node to the end of the list of topological order
- Time Complexity:
O(V + E)
Pseudocode:
- Pick an unvisited node
- Begin with selected node, do a depth first search exploring only unvisited nodes
- On recursive callback of the DFS, add the current node to the topological ordering in reverse order.

- Dijkstra's Algorithm is an algorithm for finding the shortest path between nodes in a graph for graphs with non-negative edge weights.
- Time Complexity:
O(V<sup>2</sup>), if optimized can beO(E*log(V))
Pseudocode:
- Maintain a dist array where distance to every node is positive infinity. Distance for start node is set to 0
- Maintain a priority queue (PQ) of key-value pairs of (node index, distance) pairs which tell you which node to visit next based on sorted min value
- Insert (s,0) into the PQ and loop while PQ is not empty pulling out the next most promising pair
- Iterate over all outgoing edges from the current node and relax each edge appending to a new (node index, distance) key-value pair to the PQ for every relaxation.
The issue with the above is the fact that there will be duplicate keys in the PQ because it's more efficient to insert a new key-value pair in O(log(n)) than it is to update an existing key's value in O(n). The more efficient method would be to use an indexed priority queue which allows searching in constant time and updates in log time. It would ensure that there are no duplicate keys in the priority queue.

- Bellman-Ford Algorithm is an algorithm that computes the shortest paths from a single source node to all other nodes in a weighted graph
- Although it is slower than Dijkstra's, it is more versatile, as it is capable of handling graphs in which the edge weights are negative numbers
- Time Complexity:
- Best Case:
O(E) - Worst Case:
O(VE)
- Best Case:
Pseudocode: E - number of edges V - number of vertices S - id of the starting node D - array of size V that tracks the best distance from S to each node
- Set every entry in D to +∞
- Set D[S]=0
- Relax each edge V-1 times

The edges do not need to be chosen in any specific order

- Floyd-Warshall Algorithm is an algorithm for finding the shortest paths for all pairs in a weighted graph with positive or negative edge weights, but no negative cycles
- Can find the shortest path between all pairs of nodes
- A single execution of the algorithm will find the lengths (summed weights) of the shortest paths between all pairs of nodes
- Time Complexity:
- Best Case:
O(V<sup>3) - Worst Case:
O(V<sup>3) - Average Case:
O(V<sup>3)
- Best Case:
- Space Complexity:
- O(V2)
Optimal way to represent our graph is with a 2D adjacency matrix m where cell m[i][j] - edge weight from node i to node j
- Weight from a node to itself is set to 0
- If there is no edge between 2 nodes, set value to +∞
Goal is to eventually consider going throug hall possible intermediate nodes on paths of different lengths Use dynamic programming by storing results in a 3D matrix of size n x n x n in variable dp
dp[k][i][j] = shortest path from i to j routing through nodes {0,1,..,k-1,k}
Start with k=0, build up, this gradually builds our optimal solution. Our end goal is actually dp[n-1] 2D matrix
Space complexity can be improved by computing solution for k in-place saving us a dimension making space complexity go from O(V3) to O(V2). dp[i][j] = m[i][j] if k=0 otherwise dp[i][j] = min(dp[i][j], dp[i][k]+dp[k][j])
- Prim's Algorithm is a greedy algorithm that finds a minimum spanning tree for a weighted undirected graph. In other words, Prim's find a subset of edges that forms a tree that includes every node in the graph
- Time Complexity:
O(|V|<sup>2)

- Kruskal's Algorithm is also a greedy algorithm that finds a minimum spanning tree in a graph. However, in Kruskal's, the graph does not have to be connected
- Time Complexity:
O(|E|log|V|)

- Bitwise operations are faster and closer to the system and can often be used to optimize program hence why there techniques such as bitmasks explained below
- Operands are converted to a 32 bit integer
- Both operands are evaluated bit by bit
- Returns a number as a result of the evaluation
Bitwise operators:
- & is used to represent AND
- 1 if only both bits are 1
- | is used to represent OR
- 1 if either bits are 1
- is used to represent XOR
- 1 if the two bits are different
- ~ is used to represent NOT
- Inverts bit values meaning bit value will become 1 if it was 0 initially
- Bitmasking is a technique used to perform operations at the bit level. Leveraging bitmasks often leads to faster runtime complexity and helps limit memory usage
- Test kth bit:
s & (1 << k); - Set kth bit:
s |= (1 << k); - Turn off kth bit:
s &= ~(1 << k); - Toggle kth bit:
s <sup>= (1 << k); - Multiple by 2n:
s << n; - Divide by 2n:
s >> n; - Intersection:
s & t; - Union:
s | t; - Set Subtraction:
s & ~t; - Extract lowest set bit:
s & (-s); - Extract lowest unset bit:
~s & (s + 1); - Swap Values:
x <sup>= y; y <sup>= x; x <sup>= y;
- Big O Notation is used to describe the upper bound of a particular algorithm. Big O is used to describe worst case scenarios

- Little O Notation is also used to describe an upper bound of a particular algorithm; however, Little O provides a bound that is not asymptotically tight
- Big Omega Notation is used to provide an asymptotic lower bound on a particular algorithm

- Little Omega Notation is used to provide a lower bound on a particular algorithm that is not asymptotically tight
- Theta Notation is used to provide a bound on a particular algorithm such that it can be "sandwiched" between two constants (one for an upper limit and one for a lower limit) for sufficiently large values

- Describes function in terms of other function calls of the same function with smaller inputs
- Usually used in divide and conquer algorithms
- Similar to all other problems, you want to start by first simplifying the problem
- For tree problems that means to a scenario where there is only a root node and two child nodes
- Tree problems usually utilize recursion as you will want to loop until you get to leaf nodes
- Many problems in graph theory can be represented using a grid which are an implicit graph
- An example would be
- Solving a maze
- One advantage of using a grid is that transformations can usually be avoided
- Due to fact that positions in grid are referred to usually in an (x,y) pair so transformations for adjacent cells is very straight forward
- Can either store position on grid as an (x,y) pair or an easier/more efficient manner would be to make numerous queues for each dimension
- So for a 3 dimensional grid, create 3 queues for x, y and z dimension
- Given a weighted graph, find the shortest path of edges from node A to node B
- Algorithms: BFS (unweighted graph), Dijkstra's, Bellman-Ford, Floyd-Warshall, A*, and more
DAG:
- Single Source Shortest Path problem can be solved in O(V+E) time by ordering in topological manner
- Longest path can be done by multiplying all edge weights by -1 before using single source shortest path algorithm before multiplying all edges by -1 once again
- Does there exist a path between node A and node B
- Typical solution:
- Use union find or any search algorithm (ie DFS, BFS,etc)
- Does my digraph have any negative cycles
- Algorithms : Bellman ford and Floyd--Warshall
- A bridge/cut edge is any edge in a graph whose removal increases the number of connected components and can be thought of as a bottleneck/bridge between two sets of vertices
- An aritculation point / cut vertex is any node in a graph whose removal increases the number of connected components
- A MST is a subset of edges pf a connected edge-weighted graph that connects all the vertices together without any cycle and with the minimum possible total edge weight
- Algorithms: Kruskal's, Prim. Boruvka's
- Find maximum flow through a unique graph called a flow netowrk, network where edge weight represent capacity
- Assuming we have an infinite source, how much flow can be sent at once, there will be a bottleneck
- Algorithms: Ford-Fulkerson, Edmonds-Karp, Dinic Algorithms
| BFS | Dijkstra's | Bellman Ford | Floyd Warshall | |
|---|---|---|---|---|
| Complexity | O(V+E) | O((V+E)logV) | O(VE) | O(V3) |
| Recommended graph size | Large | Large/Medium | Medium/Small | Small |
| Good for APSP | Only works on unweighted graphs | Ok | Bad | Yes |
| Detects negative cycles | No | No | Yes | Yes |
| SP on graph with weighted edges | Incorrect answer | Best | Works | Bad in general |
| SP on graph with unweighted edges | Best | Ok | Bad | Bad in general |
APSP - All pair shortest path