Remove input link in SfM, set input file cameraInit.sfm instead, result in less output images in PrepareDenseScene [question] #1167
Comments
|
It is not as easy as just adding a new input path to the sfm node. It requires some tinkering to get it to work with your own camera poses.
That is not what the documentation says. Carefully read the second part. |
|
Thank you @natowi, I did the camera poses conversion to Meshroom sfm format. What I did is first run the CameraInit node to get an initial sfm file, then add corresponding poses for each view ID. Following the Use known pose wiki, I disconnect the link from CameraInit to FeatureExtraction and set the input file of FeatureExtraction to my new generated camera sfm file. But a problem occurs in ImageMatching node. I think due to motion blur or some other issues, not all input images will be used, and the output of FeatureExtraction node doesn't have descriptors for all images in the cameraInit.sfm file. So ImageMatching will report an error about Can't find descriptor of view 353573065 in .... Is this expected when doing the reconstruction with known poses if some images are dropped? One thing I will test is to delete some views in the sfm file, so it only contains the images which are in the FeatureExtraction output. But the original CameraInit output file contains all the input images, and it will not crush the ImageMatching. So I am not sure if I am heading the right direction. As you mentioned there are some tinkering to get it to work, do you mean the tinkering mentioned in the wiki Using known camera positions, or there are some additional steps I need to go through? Thank you very much! Log in ImageMatching view 353573065 in generated cameras.sfm, and doesn't have descriptor in FeatureExtraction output. |
That is exactly what I mean. The first default test run in Meshroom is to make sure all images have enough features and matches to get reconstructed. All cameras should be reconstructed. The success for the known camera positions method described can vary, depending on your use case. There can be different issues depending on whether you use your own algorithm to calculate the positions, use known poses from a robot (accuracy problem) or use a fixed rig for which you calculated the camera positions in a first run and now use the known positions to speed up the process (that´s the most reliable/tested use case for now). There should be an option to handle unmatched images but I´d have to check what works. Best start your test with removing the blurred views. -- Can you share (public link or via private mailing list) your dataset with the new .SFM file so I can test it on my own computer? It is easier the guessing issues into the blue. |
|
I generated a new .sfm file by replacing poses in cameras.sfm in StructureFromMotion node built in the first Meshroom pipeline run with my own camera poses, so the dropped images will not have pose data. But the same problem still exists. I also notice that the output of FeatureExtraction changed quite a lot, as shown in the screenshots below. Originally, it will go through a much broader image range, output multiple .status files, and a lot more .desc descriptor files. However, when I disconnect the input link from CameraInit node, and set the input to my own generated sfm file, it seems it will only loop once the rangeSize which is 40, so only 40 descriptor files are generated by FeatureExtraction, but I have around 500 valid images in input. This will make the ImageMatching node stop continuing, and with the error Can't find descriptor of view xxx in .... Screenshots FeatureExtraction output with known poses generated sfm file I also sent supportive materials to the private mailing list. Thank you very much for helping! |


|
Thanks, I´ll take a look and report back. |
|
What camera did you use? |
|
Ok, I reduced the sfm file to 40 images to make it manageable. Without known poses, only 4/40 images were reconstructed with the default settings (using the sfm file without the poses, replacing the cameraInit). With the cameraInit+knownposes and default node settings, 13/40 images were reconstructed.
I did not figure out why there is the limit in the rangesize of 40 |

I use an iPad Pro 2nd Gen camera, I hold the iPad and walk around in the scene to record a video about the room. Then I extract frames from the video, which will result in blurry images, images were taken close together as you mentioned. The limitation of the rangesize of 40, could you offer me some comments or suggestions about the potential cause? So I know where to look for, I am just a beginner on Meshroom pipeline, and not familiar with the source code structure. It will also be great if you have time to help me with this rangesize problem. Thank you very much for your time and helping! |
|
@natowi, Hi thank you for answering my questions. I notice that #1240 posted that "_FeatureExtraction step generates 40 x .desc and 40 x .feat. Only 1 chunk is done." After these days of trying to reconstruct scenes with known camera poses, I found that the problem is in the class DynamicNodeSize. Log
In StructureFromMotion "Lock Scene previously reconstructed" and "Force Lock of all Intrinsic Camera Parameters" works fine, if I don't use "Match From Known Camera Poses" in node FeatureMatching. I am not sure how much it will influence the reconstruction quality if I still doesn't use known camera poses in FeatureMatching. |
|
This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions. |
|
This issue is closed due to inactivity. Feel free to re-open if new information is available. |
Describe the problem
I am working on reconstructing a scene with known camera poses, I followed the link Using known camera positions but it doesn't work for me.
I tested the pipeline, by running the entire default pipeline, which successfully goes through the entire pipeline and returned a mesh.
I then copied the input file path in the SfM node input attribute, removed the input link of Structure from Motion node, and paste back the input file path in the input attribute field, and run the SfM node again. The SfM node works fine, and then the next node PrepareDenseScene only goes from rangStart 0 with rangSize 40. And output only has 0.log, 0.statistics, 0.status and some images. Whereas, originally it will have 0.log, 0.statistics, 0.status, and 1.log, 1.statistics, 1.status.
Which makes the node DepthMap reports an error. Cannot find image file coresponding to the view ...
Screenshots
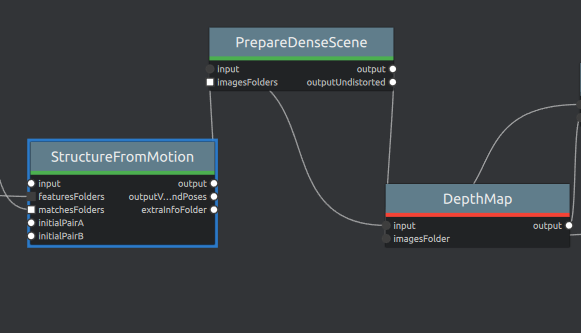
Log
Desktop:
This is very confusing to me, since I didn't change anything. I simply just remove an input link and set back the input file path. Which makes the pipeline fails. I would like to ask, is the input link have some additional functionalities except for setting the input file path?
Thank you!
The text was updated successfully, but these errors were encountered: