This repository has been archived by the owner on Jan 14, 2019. It is now read-only.
Allure 1.5 development page
Данная страница предназначена исключительно для сохранения некоторых мыслей и планов про новую версию Аллюра. Мы считаем, что пора уже выпускать новую кленовую версию 2.0. Основные изменения/улучшения:
- Сосредоточиться на стабилизации модели. Продумать возможные использования. Модель должна лежать в отдельном репозитории, хорошо документированная. Какие планируются изменения модели:
- Избавиться от сущности
TestSuiteResult. Информация о тестах может находиться в двух типах файлов:.*-testcase.xmlи.*-testcase-group.xml - Добавить возможность сохранять в модели фазы
before,afteretc - Шаги - добавить аттрибут
threadId - Шаги - может стоит добавить параментры?
- Избавиться от сущности
- Миграции. Теперь каждое изменение модели, должно сопровождаться файлом миграции. Отчет всегда строится последней версии, предварительно применив миграции к файлам
- Написать миграции с 1.3
- Система нотификаций. Информация о прерванных тестах и прочее
Одной из больших проблем сейчас является генерация данных для отчета из xml. Проблемы:
- XSLT требует достаточно много памяти
- Сложно разобраться/модифицировать XSLT
- Плохая расширяемость

Минусы:
- В рамках данной архитектуры сложно реализовать замену имен аттачей (хочется заменить на
sha256чтобы убрать дубликаты) - Сбор всех данных о тестах в один файл - не лучшая идея
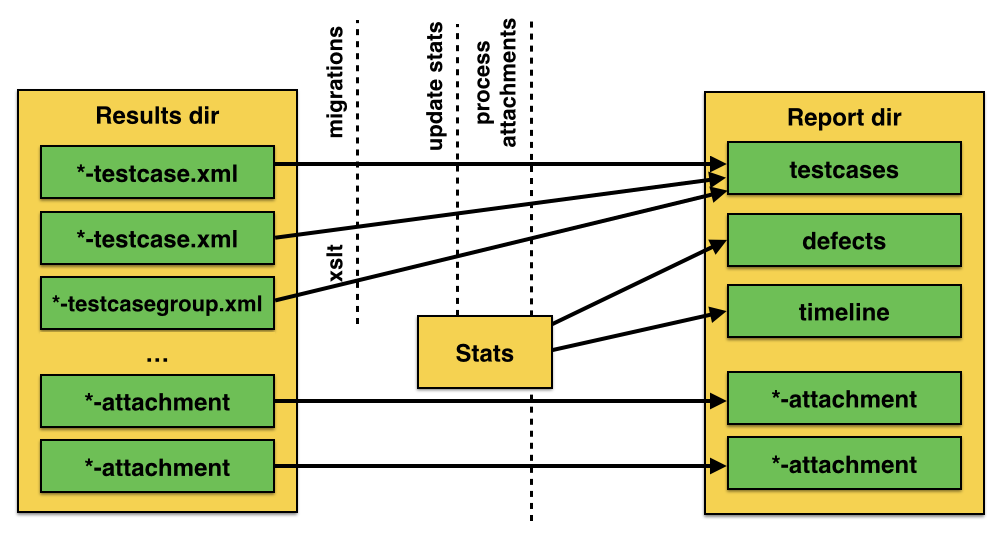
- Большую часть тест кейса (степы, аттачи etc) мы может сразу сохранить в
testcase.json - В объекте
Statsсчитается время начала рана, конца, длительность и статистика (количество упавших etc). - Также в
Statsхранится списокTestCaseInfo, который содержит тайтл кейса, статус и его лейблы.
Тут еще должны быть файлы {testSuiteName.xml}, пока не придумал что с ними делать
Хочется иметь некоторый список расширений, которые выглядят примерно следующим образом:
pubic class DescriptionConverter implements Converter<Description, Description> {
public Description convert(Description description) {
if (MARKDOWN.equals(description.getType())) {
description.setText(new Pegdown().process(description.getText()));
}
return description;
}
}Чтобы такие расширения подгружались автоматически и применялись при трансформации. Но, пока не знаю, как добавить возможность подмены стандартной логики.
- Before generation
- Prepare
- Process cases
- Execute providers
- After generation
- Find all test cases by pattern in result directories
- Create empty
TestRunInfoobject- Run start/stop/duration
- Tests statuses. Count of passed/failed etc
- List of
TestCaseInfo. Each element contains the following information- Name/title
- Start/stop/duration
- Status
- List of labels
- For each test case:
- Convert to new format [we can do it async]
- Add duration
- Move severity from labels
- NOTE: can load some data using plugins from external systems
- NOTE: attachments. We should be able to process attachments during this step. And example - rename each attachment using
sha256
- Update
TestRunInfo
- Convert to new format [we can do it async]
- Find all providers [plugins?]
- Execute providers [we can do it async]
- Create
AllureXUnitobject - Copy stats from
TestRunInfo - Group test cases by suite label
- For each group
- Create
AllureTestSuiteobject - Find suite data . By default by pattern in result directories. Can be overloaded/amended using plugins (an example using
@TestIdannotation from TMS) - Update
AllureTestSuite
- Create
- Serialize
AllureXUnitto report directory