Flink CDC | OOM during initial snapshot #2504
Description
I am using flink CDC to stream CDC changes in an iceberg table. When I first run the flink job for a topic with all the data for a table, it gets out of heap memory as flink tries to load all the data during my 15mins checkpointing interval. Right now, the only solution I have is to pass -ytm 8192 -yjm 2048m -p 2 for a table with 10M rows and then reduce it after the flink has consumed all the data.
I am attaching a sample job DAG, for my prod job kafka topic has 2 partitions
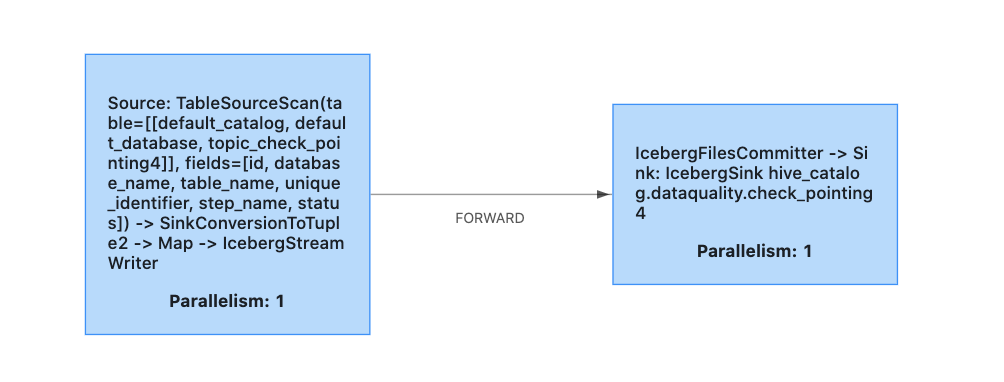
Shouldn't my iceberg sink have propagated the back-pressure up the source since it has not written that data yet and it will only do that after the checkpointing interval?
FlinkSink.forRowData(rowDataDataStream)
.table(icebergTable)
.tableSchema(FlinkSchemaUtil.toSchema(FlinkSchemaUtil.convert(icebergTable.schema())))
.tableLoader(tableLoader)
.equalityFieldColumns(tableConfig.getEqualityColumns())
.build();