LUCENE-10311: Different implementations of DocIdSetBuilder for points and terms #692
Conversation
| if (bitSet != null) { | ||
| bitSet.or(iter); | ||
| return; | ||
| } |
There was a problem hiding this comment.
I haven't change the implementation here but this looks buggy for me. If the bitSet is not null we don't update counter any more in this case?
|
I'm still a bit confused about why we need to It seems the only purpose of the Sorry if my comment isn't very helpful, but I want to really understand the problem and why we need to bring 64 bits into this, currently it is very confusing. Perhaps we should remove this It turns the problem around, into, how can we estimate the cost better. I don't think we should have to majorly reorganize the code just for this For example in the sparse/buffer case, wouldn't a much simpler estimation simply be the |
SparseFixedBitSet was truely used to gather docs in sparse case before LUCENE-6645. |
|
I open #698 where I proposed a different way to compute const that reflect that the internal counter of DocIdSetBuilder refers to documents instead of values. |
|
In my opinion the API as it is today isn't bad. The only thing we might want to change is to make Maybe it's a javadocs issue because
This doesn't have anything to do with the The point of
This is already the case today, see the FWIW we could change the estimation logic to perform a popCount over a subset of the
|
I've really tried, I think I have to just give up. Having a Please, please, please don't make this change to take a long.
Sure it does. I'm looking at the only code using the 64-bit value, and that's the |
Would it look better if we gave it a different name that doesn't suggest that it relates to the number of docs in the set, e.g.
I have a preference for making it a long but I'm ok with keeping it an integer. The downside is that it pushes the problem to callers, which need to make sure that they never add more than |
|
I've uploaded a screenshot here of how the only thing using 64-bits is this stupid |
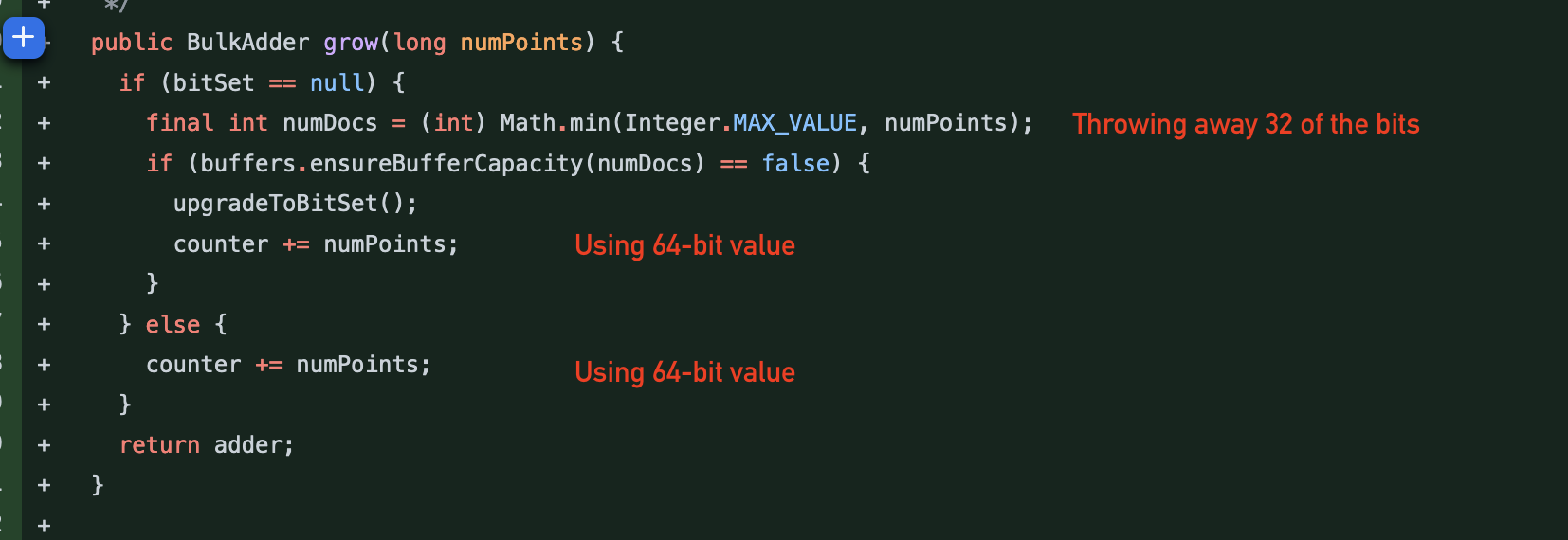
|
I don't understand all this discussion. Looking at the cost of a DocIdSetIterator: Why it is ok a long here? I think the dance we are doing on the BKD reader when wee are visiting more that Integer.MAX_VALUE |
|
Yeah, there seems to be some disagreement about what the code is actually doing. Probably because it is too confusing. Recommend (as i did before) to temporarily remove |
|
If you go a bit higher top in that class:
We are throwing 32 bits there now? |
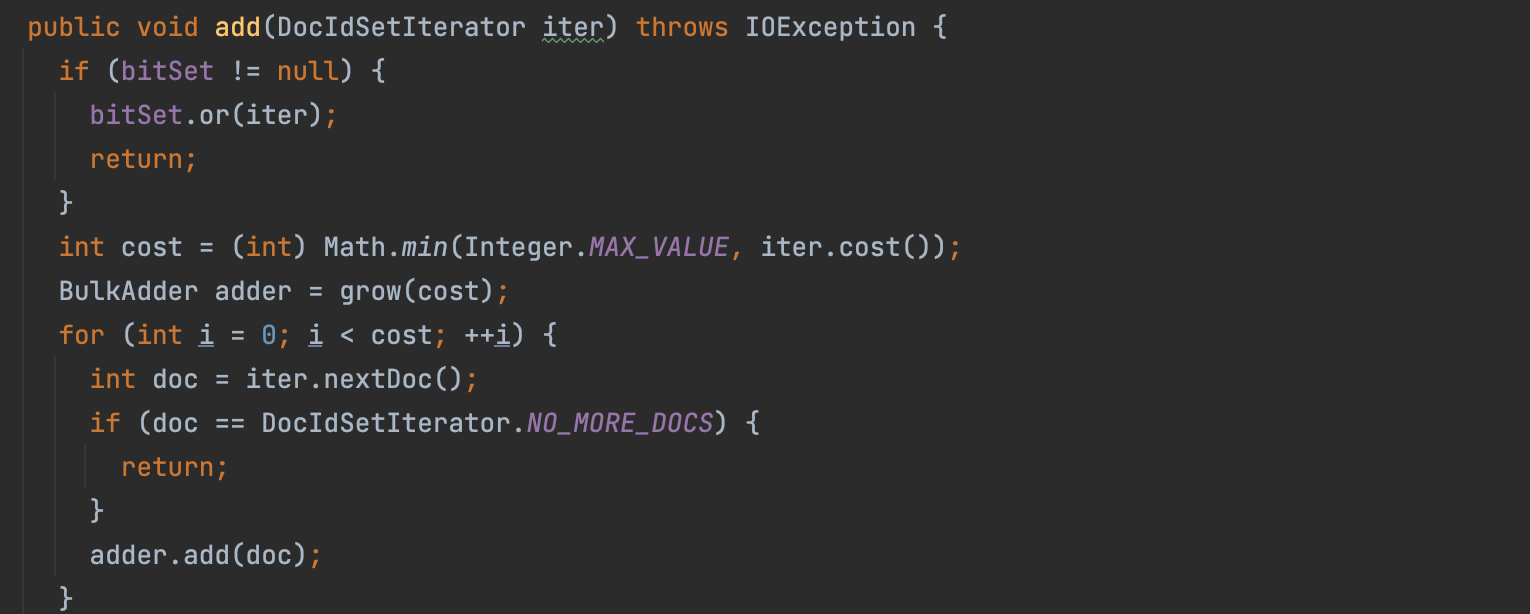
|
it's fine to do that since only 32 bits are needed. nothing uses 64-bits here, hence changing the api signature to a |
|
Seriously, let's remove this If we remove the silly |
|
@rmuir We can remove the cost estimation, but it will not address the problem. I'll try to explain the problem differently in case it helps. DocIdSetBuilder takes doc IDs in random order with potential duplicates and creates a DocIdSet that can iterate over doc IDs in order without any duplicates. If you index a multi-valued field with points, a very large segment that has 2^30 docs might have 2^32 points matching a range query, which translates into 2^29 documents matching the query. So The naming may be wrong here, as the |
I really think it will address the problem. I understand what is happening, but adding 32 more bits that merely get discarded also will not help anything. That's what is being discussed here. It really is all about cost estimation, as that is the ONLY thing in this PR actually using the 32 extra bits. That's why i propose to simply use a different cost estimation instead. The current cost estimation explodes the complexity of this class: that's why we are tracking:
There's no need (from allocation perspective, which is all we should be concerned about here) to know about any numbers bigger than |
|
32 bits will need to be discarded anyway, the issue is where. You either do it at the PointValues level by calling grow like: Or you discarded in the DocIdSetBuilder and allow grow to be called just like: |
|
If this is literally all about "style" issue then let's be open and honest about that. I am fine with: But I think it is wrong to have constructors taking And I definitely think having two separate classes just for the cost estimation is way too much. |
|
To try to be more helpful, here's what i'd propose. I can try to hack up a draft PR later if we want, if it is helpful. DocIdSetBuilder, remove complex cost estimation:
DocIdSetBuilder: add sugar FixedBitSet: implement |
|
prototype: #709 |
|
won't happen |
The idea in this PR is the following:
PointsDocIdSetBuilderwith the following API: