[MXNET-594] Added Learning Rate Finder tutorial #11304
Conversation
|
@aaronmarkham would you provide some input on the writing? @astonzhang could you help review the code when you have time? |
|
@Ishitori @ThomasDelteil could you review when you get a chance, thanks! |
|
@indhub got any time to review? thanks! |
| learner: able to take single iteration with given learning rate and return loss | ||
| and save and load parameters of the network (Learner) | ||
| """ | ||
| self.learner = learner |
There was a problem hiding this comment.
Private fields better to start with underscore "_"
There was a problem hiding this comment.
Will leave for this tutorial since stylistic, but will do in future!
| smoothing: applied to running mean which is used for thresholding (float) | ||
| min_iter: minimum number of iterations before early stopping can occur (int) | ||
| """ | ||
| self.smoothing = smoothing |
| lr = lr_start | ||
| self.results = [] # List of (lr, loss) tuples | ||
| stopping_criteria = LRFinderStoppingCriteria(smoothing) | ||
| while True: |
There was a problem hiding this comment.
Try to rewrite to while not stopping_criteria(loss), as it looks cleaner
There was a problem hiding this comment.
Would need duplication of two lines of code, so prefer as is.
|
|
||
| def close(self): | ||
| # Close open iterator and associated workers | ||
| self.data_loader_iter.shutdown() |
There was a problem hiding this comment.
Is simple self.data_loader_iter.close() is not enough?
There was a problem hiding this comment.
After experimenting, determined that shutdown was best option for reliable closing.
| # So we don't need to be in `for batch in data_loader` scope | ||
| # and can call for next batch in `iteration` | ||
| self.data_loader_iter = iter(self.data_loader) | ||
| self.net.collect_params().initialize(mx.init.Xavier(), ctx=self.ctx) |
| if not self.learner.trainer._kv_initialized: | ||
| self.learner.trainer._init_kvstore() | ||
| # Store params and optimizer state for restore after lr_finder procedure | ||
| self.learner.net.save_params("lr_finder.params") |
There was a problem hiding this comment.
I find the code for saving and restoring parameters adding unnecessary complication. Given that the LR finding is a completely separate step before actual learning and its output plot must be manually analyzed, why not just create a completely separate network/trainer for LR Finder and once this process is over, create another network/trainer for confirming that correct LR has been selected.
There was a problem hiding this comment.
It's been suggested that this method can be used during training too, which would require save and load to get back to original state. Will add a comment to explain this. And also helps with reproducibility of results of learning rate finder (for different settings) since the same initialization values are used each time.
|
|
||
| Setting the learning rate for stochastic gradient descent (SGD) is crucially important when training neural network because it controls both the speed of convergence and the ultimate performance of the network. Set the learning too low and you could be twiddling your thumbs for quite some time as the parameters update very slowly. Set it too high and the updates will skip over optimal solutions, or worse the optimizer might not converge at all! | ||
|
|
||
| Leslie Smith from the U.S. Naval Research Laboratory presented a method for finding a good learning rate in a paper called ["Cyclical Learning Rates for Training Neural Networks"](https://arxiv.org/abs/1506.01186). We take a look at the central idea of the paper, cyclical learning rate schedules, in the tutorial found here, but in this tutorial we implement a 'Learning Rate Finder' in MXNet with the Gluon API that you can use while training your own networks. |
There was a problem hiding this comment.
"found here" - Did you mean to provide a link here?
There was a problem hiding this comment.
"but in this tutorial" - "but in this tutorial,"
There was a problem hiding this comment.
Good catch, unpublished tutorial so replaced with name of tutorial.
There was a problem hiding this comment.
Comma overload if add.
|
|
||
|  <!--notebook-skip-line--> | ||
|
|
||
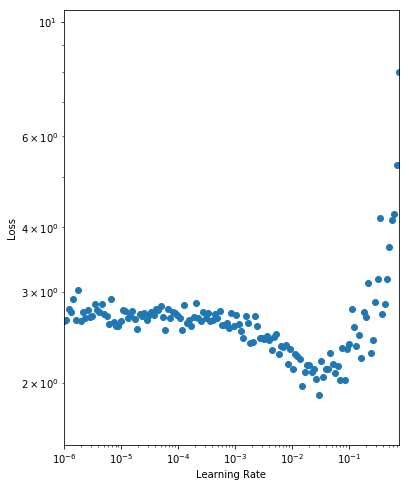
| As expected, for very small learning rates we don't see much change in the loss as the paramater updates are negligible. At a learning rate of 0.001 we start to see the loss fall. Setting the initial learning rate here is reasonable, but we still have the potential to learn faster. We observe a drop in the loss up until 0.1 where the loss appears to diverge. We want to set the initial learning rate as high as possible before the loss becomes unstable, so we choose a learning rate of 0.05. |
There was a problem hiding this comment.
"At a learning rate of 0.001" -> "At a learning rate of 0.001,"
| 2. start with a very small learning rate (e.g. 0.000001) and slowly increase it every iteration | ||
| 3. record the training loss and continue until we see the training loss diverge | ||
|
|
||
| We then analyse the results by plotting a graph of the learning rate against the training loss as seen below (taking note of the log scales). |
There was a problem hiding this comment.
It's the Queen's English Indu! 🇬🇧
|
|
||
| ## Epoch to Iteration | ||
|
|
||
| Usually our unit of work is an epoch (a full pass through the dataset) and the learning rate would typically be held constant throughout the epoch. With the Learning Rate Finder (and cyclical learning rate schedules) we are required to vary the learning rate every iteration. As such we structure our training code so that a single iteration can be run with a given learning rate. You can implement Learner as you wish. Just initialize the network, define the loss and trainer in `__init__` and keep your training logic for a single batch in `iteration`. |
|
|
||
| ## Implementation | ||
|
|
||
| With preparation complete, we're ready to write our Learning Rate Finder that wraps the `Learner` we defined above. We implement a `find` method for the procedure, and `plot` for the visualization. Starting with a very low learning rate as defined by `lr_start` we train one iteration at a time and keep multiplying the learning rate by `lr_multiplier`. We analyse the loss and continue until it diverges according to `LRFinderStoppingCriteria` (which is defined later on). You may also notice that we save the parameters and state of the optimizer before the process and restore afterwards. This is so the Learning Rate Finder process doesn't impact the state of the model, and can be used at any point during training. |
| if not self.learner.trainer._kv_initialized: | ||
| self.learner.trainer._init_kvstore() | ||
| # Store params and optimizer state for restore after lr_finder procedure | ||
| self.learner.net.save_params("lr_finder.params") |
There was a problem hiding this comment.
"save_params" is deprecated. Should we use save_parameters instead?
|
|
||
|
|
||
| ```python | ||
| learner.net.save_params("net.params") |
There was a problem hiding this comment.
save_params is deprecated. Should we use save_parameters instead?
| ```python | ||
| net = mx.gluon.model_zoo.vision.resnet18_v2(classes=10) | ||
| learner = Learner(net=net, data_loader=data_loader, ctx=ctx) | ||
| learner.net.load_params("net.params", ctx=ctx) |
There was a problem hiding this comment.
load_params is deprecated. Should we use load_parameters instead?
| ```python | ||
| net = mx.gluon.model_zoo.vision.resnet18_v2(classes=10) | ||
| learner = Learner(net=net, data_loader=data_loader, ctx=ctx) | ||
| learner.net.load_params("net.params", ctx=ctx) |
There was a problem hiding this comment.
load_params is deprecated. Should we use load_parameters instead?
| break | ||
| lr = lr * lr_multiplier | ||
| # Restore params (as finder changed them) | ||
| self.learner.net.load_params("lr_finder.params", ctx=self.learner.ctx) |
There was a problem hiding this comment.
load_params is deprecated. Should we use load_parameters instead?
|
@indhub reverting back to use |
|
|
||
| Setting the learning rate for stochastic gradient descent (SGD) is crucially important when training neural network because it controls both the speed of convergence and the ultimate performance of the network. Set the learning too low and you could be twiddling your thumbs for quite some time as the parameters update very slowly. Set it too high and the updates will skip over optimal solutions, or worse the optimizer might not converge at all! | ||
|
|
||
| Leslie Smith from the U.S. Naval Research Laboratory presented a method for finding a good learning rate in a paper called ["Cyclical Learning Rates for Training Neural Networks"](https://arxiv.org/abs/1506.01186). We take a look at the central idea of the paper, cyclical learning rate schedules, in the tutorial called 'Advanced Learning Rate Schedules', but in this tutorial we implement a 'Learning Rate Finder' in MXNet with the Gluon API that you can use while training your own networks. |
There was a problem hiding this comment.
Can you link to the tutorial mentioned? 'Advanced Learning Rate Schedules'
There was a problem hiding this comment.
I'd break the sentence up at ",but"
Flip it around for clarity....
(assuming there's some order? is there a preferred order?)
In the Advanced Learning Rate Schedules tutorial you learned about cyclical learning rate schedules which (do x and y). In this tutorial you will learn how to implement a "Learning Rate Finder" which (does z or x differently). You will use MXNet with the Gluon API to train your network.
There was a problem hiding this comment.
Added link and changed sentence.
|
|
||
| Given an initialized network, a defined loss and a training dataset we take the following steps: | ||
|
|
||
| 1. train one batch at a time (a.k.a. an iteration) |
There was a problem hiding this comment.
nit:
Train
Start
Record
|
|
||
|  <!--notebook-skip-line--> | ||
|
|
||
| As expected, for very small learning rates we don't see much change in the loss as the parameter updates are negligible. At a learning rate of 0.001, we start to see the loss fall. Setting the initial learning rate here is reasonable, but we still have the potential to learn faster. We observe a drop in the loss up until 0.1 where the loss appears to diverge. We want to set the initial learning rate as high as possible before the loss becomes unstable, so we choose a learning rate of 0.05. |
There was a problem hiding this comment.
Could you add event pointers on the chart for increased clarity.
--> at 0.001 loss falls
--> at 0.1 divergence (loss increases)
--> at 0.05 loss seems lowest (right?)
There was a problem hiding this comment.
Good suggestion, created annotated chart.
|
|
||
| ## Wrap Up | ||
|
|
||
| Give Learning Rate Finder a try on your current projects, and experiment with the different learning rate schedules found in this tutorial too. |
There was a problem hiding this comment.
I went back to look for the "different learning rate schedules" and they not explicitly defined. Or maybe I missed that point, but I wasn't really able to find it.
| class Learner(): | ||
| def __init__(self, net, data_loader, ctx): | ||
| """ | ||
| net: network (mx.gluon.Block) |
There was a problem hiding this comment.
please use standard pydoc format, see the Gluon code for examples
Could the loss be passed as an argument?
There was a problem hiding this comment.
Changed to use reStructuredText Docstring Format (PEP 287)
| # Update parameters | ||
| if take_step: self.trainer.step(data.shape[0]) | ||
| # Set and return loss. | ||
| # Although notice this is still an MXNet NDArray to avoid blocking |
There was a problem hiding this comment.
I think blocking would be good here since we are not trying to optimize performance and we shouldn't want to risk cuda malloc
There was a problem hiding this comment.
Was anticipating a comment, so made non blocking :)
Changed to be non-blocking.
| # Restore params (as finder changed them) | ||
| self.learner.net.load_params("lr_finder.params", ctx=self.learner.ctx) | ||
| self.learner.trainer.load_states("lr_finder.state") | ||
| self.plot() |
There was a problem hiding this comment.
can you return results here rather than calling plot? Users might not be a in a graphical environment
There was a problem hiding this comment.
Removed plot, returned results. Called plot separately.
| # Set seed for reproducibility | ||
| mx.random.seed(42) | ||
|
|
||
| class Learner(): |
There was a problem hiding this comment.
I am not sure about this naming but at the same time can't really find a better one. IterationRunner? I don't know
There was a problem hiding this comment.
Me neither, but going to leave to avoid confusion with the videos that have been recorded.
There was a problem hiding this comment.
thanks for the reviews @aaronmarkham and @ThomasDelteil! made necessary changes.
|
|
||
| Setting the learning rate for stochastic gradient descent (SGD) is crucially important when training neural network because it controls both the speed of convergence and the ultimate performance of the network. Set the learning too low and you could be twiddling your thumbs for quite some time as the parameters update very slowly. Set it too high and the updates will skip over optimal solutions, or worse the optimizer might not converge at all! | ||
|
|
||
| Leslie Smith from the U.S. Naval Research Laboratory presented a method for finding a good learning rate in a paper called ["Cyclical Learning Rates for Training Neural Networks"](https://arxiv.org/abs/1506.01186). We take a look at the central idea of the paper, cyclical learning rate schedules, in the tutorial called 'Advanced Learning Rate Schedules', but in this tutorial we implement a 'Learning Rate Finder' in MXNet with the Gluon API that you can use while training your own networks. |
There was a problem hiding this comment.
Added link and changed sentence.
|
|
||
| Given an initialized network, a defined loss and a training dataset we take the following steps: | ||
|
|
||
| 1. train one batch at a time (a.k.a. an iteration) |
|
|
||
|  <!--notebook-skip-line--> | ||
|
|
||
| As expected, for very small learning rates we don't see much change in the loss as the parameter updates are negligible. At a learning rate of 0.001, we start to see the loss fall. Setting the initial learning rate here is reasonable, but we still have the potential to learn faster. We observe a drop in the loss up until 0.1 where the loss appears to diverge. We want to set the initial learning rate as high as possible before the loss becomes unstable, so we choose a learning rate of 0.05. |
There was a problem hiding this comment.
Good suggestion, created annotated chart.
| # Set seed for reproducibility | ||
| mx.random.seed(42) | ||
|
|
||
| class Learner(): |
There was a problem hiding this comment.
Me neither, but going to leave to avoid confusion with the videos that have been recorded.
| class Learner(): | ||
| def __init__(self, net, data_loader, ctx): | ||
| """ | ||
| net: network (mx.gluon.Block) |
There was a problem hiding this comment.
Changed to use reStructuredText Docstring Format (PEP 287)
| # Update parameters | ||
| if take_step: self.trainer.step(data.shape[0]) | ||
| # Set and return loss. | ||
| # Although notice this is still an MXNet NDArray to avoid blocking |
There was a problem hiding this comment.
Was anticipating a comment, so made non blocking :)
Changed to be non-blocking.
| # Restore params (as finder changed them) | ||
| self.learner.net.load_params("lr_finder.params", ctx=self.learner.ctx) | ||
| self.learner.trainer.load_states("lr_finder.state") | ||
| self.plot() |
There was a problem hiding this comment.
Removed plot, returned results. Called plot separately.
|
@indhub made changes as per the feedback, so if all looks good would you be able to merge? |
* Added Learning Rate Finder tutorial. * Updated based on feedback. * Reverting save_parameters changes. * Adjusted based on feedback. * Corrected outdated code comment.
Description
Added tutorial that demonstrates a method of finding a good initial starting learning rate.
Method from "Cyclical Learning Rates for Training Neural Networks" by Leslie N. Smith (2015). And seen in many blog posts (e.g. https://towardsdatascience.com/estimating-optimal-learning-rate-for-a-deep-neural-network-ce32f2556ce0).
Checklist
Essentials
Please feel free to remove inapplicable items for your PR.
Changes
Comments