[SPARK-19846][SQL] Add a flag to disable constraint propagation #17186
Conversation
|
This is a much simpler option: add a flag to disable constraint propagation, if we are ok for skipping optimizations relying on constraints ( |
|
Test build #74071 has finished for PR 17186 at commit
|
| object InferFiltersFromConstraints extends Rule[LogicalPlan] with PredicateHelper { | ||
| case class InferFiltersFromConstraints(conf: CatalystConf) | ||
| extends Rule[LogicalPlan] with PredicateHelper { | ||
| def apply(plan: LogicalPlan): LogicalPlan = plan transform { |
There was a problem hiding this comment.
Just check the flag before you start transforming the tree. That is a lot simpler & faster.
There was a problem hiding this comment.
+1; this rule is just a no-op if constraints aren't inferred.
| def apply(plan: LogicalPlan): LogicalPlan = plan transform { | ||
| case f @ Filter(condition, j @ Join(_, _, RightOuter | LeftOuter | FullOuter, _)) => | ||
| case f @ Filter(condition, j @ Join(_, _, RightOuter | LeftOuter | FullOuter, _)) | ||
| if conf.constraintPropagationEnabled => |
There was a problem hiding this comment.
This is far to restrictive. We can still eliminate outer joins without constraint propagation.
|
@viirya could you add a test? |
|
@hvanhovell It is late in local time, I addressed the comments first. I will add test tomorrow. |
|
Test build #74108 has finished for PR 17186 at commit
|
 sameeragarwal
left a comment
sameeragarwal
left a comment
There was a problem hiding this comment.
Instead of disabling every optimization, can we just not configure lazy val constraints: ExpressionSet = ExpressionSet(Set.empty) in QueryPlan to achieve the same goal?
|
@sameeragarwal To do that, we may need to change |
|
@sameeragarwal Btw, another point is, if we do that, we still need to transform the plan even the flag is disabled. |
|
@sameeragarwal Rethink about it, I think let |
|
@hvanhovell @sameeragarwal Following @sameeragarwal's comment, now instead of disabling every optimization, a new method Please take a look. Thanks. |
|
Btw, test cases are added. |
c863f67 to
3eda726
Compare
|
Test build #74171 has finished for PR 17186 at commit
|
|
Test build #74173 has finished for PR 17186 at commit
|
|
Test build #74174 has finished for PR 17186 at commit
|
…constraint-propagation
|
Test build #74248 has started for PR 17186 at commit |
|
retest this please. |
|
Test build #74253 has finished for PR 17186 at commit
|
|
@hvanhovell @sameeragarwal Please let me know if you have more thoughts on the new change. Thanks. |
|
Thanks @viirya, this approach makes sense to me. Can you please modify |
|
Here's another instantiation of the underlying bug: https://issues.apache.org/jira/browse/SPARK-19875 |
| .createWithDefault(false) | ||
|
|
||
| val CONSTRAINT_PROPAGATION_ENABLED = buildConf("spark.sql.constraintPropagation.enabled") | ||
| .internal() |
There was a problem hiding this comment.
This should not be an internal flag, right? cc @sameeragarwal @hvanhovell
There was a problem hiding this comment.
Not sure about it, because constraint propagation is internal details.
There was a problem hiding this comment.
To determine whether a flag is internal or not, we should consider the impact of external users. If users could easily hit this, we might need to expose it as an external flag and document it in the public document.
There was a problem hiding this comment.
Due to the fact there are few users reporting hitting this issue, we may need to expose it as an external flag. But looks like it is not very common issue, compared with other external flag.
However, I would think that a large portion of external users may not know constraint propagation. It might not be intuitive to link the problem they hit to constraint propagation and to find this config, even it is external.
There was a problem hiding this comment.
Constraint propagation is like predicate pushdown, which has already been used in external configurations. We can rename it to make external users easy to understand, e.g., constraints inferences.
|
Test build #74473 has finished for PR 17186 at commit
|
|
@sameeragarwal Thanks for the comment. I've updated |
…constraint-propagation
|
Test build #74581 has started for PR 17186 at commit |
…constraint-propagation
|
Test build #74588 has finished for PR 17186 at commit
|
| val optimized = OptimizeDisableConstraintPropagation.execute(queryWithUselessFilter.analyze) | ||
| // When constraint propagation is disabled, the useless filter won't be pruned. | ||
| // It gets pushed down. Because the rule `CombineFilters` runs only once, there are redundant | ||
| // and duplicate filters. |
There was a problem hiding this comment.
This behaviour does not make sense to me. If I write a query like
select * from (select * from t1 where t1.a1 > 1) tx where tx.a1 > 1
I expect that Spark evaluates the predicate only once. The wording of "constraint propagation" is misleading. In this example, there is no activity of propagation at all. Perhaps we want to distinguish the "constraints" between the ones written originally and the ones that are inferred from relationships with other predicates. When the "propagation" (or perhaps a more meaningful term "predicate inference") is set to OFF, we want to exclude those inferred predicates in the def constraints.
There was a problem hiding this comment.
What needs to clarify is, this behaviour is just limited to this test case. That is why I added the comment. In normal optimization, CombineFilters will run multiple times and the predicates will be combined.
There was a problem hiding this comment.
I am aware of it. My point is when users turn on this setting in hope of alleviating the long compilation time, they will get this "unintentional" side effect that could lengthen the execution time of evaluating the same predicate twice.
Overall, I agree with your approach but the point I raised could be a followup work.
There was a problem hiding this comment.
This is a workaround in short term. Actually I have proposed another approach to bring new data structure for constraint propagation in #16998. But it is more complex and may need more time to consider and review.
|
ping @sameeragarwal This is updated according to your previous comment. Can you help review this? Thanks. |
…constraint-propagation
|
ping @sameeragarwal Is it possible this goes in before code-freeze of 2.2? Please let me know that, thanks. |
|
Test build #75043 has finished for PR 17186 at commit
|
|
Sorry @viirya, I'll review this first thing tomorrow morning |
|
@sameeragarwal Thanks a lot. |
…constraint-propagation
sameeragarwal
left a comment
There was a problem hiding this comment.
This looks great overall, I just left a few minor comments. Thanks!
|
|
||
| private def inferFilters(plan: LogicalPlan): LogicalPlan = plan transform { | ||
| case filter @ Filter(condition, child) => | ||
| val constraintEnabled = conf.constraintPropagationEnabled |
|
|
||
| val CONSTRAINT_PROPAGATION_ENABLED = buildConf("spark.sql.constraintPropagation.enabled") | ||
| .internal() | ||
| .doc("When true, the query optimizer will use constraint propagation in query plans to " + |
There was a problem hiding this comment.
nit: 'get around the issue' might sound pretty vague to a non-expert user. How about something along these lines?
.doc("When true, the query optimizer will infer and propagate data constraints in the query " +
"plan to optimize them. Constraint propagation can sometimes be computationally expensive" +
"for certain kinds of query plans (such as those with a large number of predicates and " +
"aliases) which might negatively impact overall runtime.")| CombineFilters) :: Nil | ||
| } | ||
|
|
||
| object OptimizeDisableConstraintPropagation extends RuleExecutor[LogicalPlan] { |
There was a problem hiding this comment.
nit: perhaps OptimizeWithConstraintPropagationDisabled?
| PushPredicateThroughJoin) :: Nil | ||
| } | ||
|
|
||
| object OptimizeDisableConstraintPropagation extends RuleExecutor[LogicalPlan] { |
| EliminateSubqueryAliases) :: | ||
| Batch("Outer Join Elimination", Once, | ||
| EliminateOuterJoin, | ||
| EliminateOuterJoin(SimpleCatalystConf(caseSensitiveAnalysis = true)), |
There was a problem hiding this comment.
Can we add a test for outer join elimination as well?
|
@sameeragarwal Thanks for review! I've addressed all the comments now. Please take a look if it is good for you. |
|
Test build #75139 has finished for PR 17186 at commit
|
|
LGTM, thanks! cc @hvanhovell |
|
Merging in master. |
Constraint propagation can be computation expensive and block the driver execution for long time. For example, the below benchmark needs 30mins. Compared with previous PRs apache#16998, apache#16785, this is a much simpler option: add a flag to disable constraint propagation. Run the following codes locally. import org.apache.spark.ml.{Pipeline, PipelineStage} import org.apache.spark.ml.feature.{OneHotEncoder, StringIndexer, VectorAssembler} import org.apache.spark.sql.internal.SQLConf spark.conf.set(SQLConf.CONSTRAINT_PROPAGATION_ENABLED.key, false) val df = (1 to 40).foldLeft(Seq((1, "foo"), (2, "bar"), (3, "baz")).toDF("id", "x0"))((df, i) => df.withColumn(s"x$i", $"x0")) val indexers = df.columns.tail.map(c => new StringIndexer() .setInputCol(c) .setOutputCol(s"${c}_indexed") .setHandleInvalid("skip")) val encoders = indexers.map(indexer => new OneHotEncoder() .setInputCol(indexer.getOutputCol) .setOutputCol(s"${indexer.getOutputCol}_encoded") .setDropLast(true)) val stages: Array[PipelineStage] = indexers ++ encoders val pipeline = new Pipeline().setStages(stages) val startTime = System.nanoTime pipeline.fit(df).transform(df).show val runningTime = System.nanoTime - startTime Before this patch: 1786001 ms ~= 30 mins After this patch: 26392 ms = less than half of a minute Related PRs: apache#16998, apache#16785. Jenkins tests. Please review http://spark.apache.org/contributing.html before opening a pull request. Author: Liang-Chi Hsieh <viirya@gmail.com> Closes apache#17186 from viirya/add-flag-disable-constraint-propagation.
|
May I ask how to solve this issue in spark2.3? |
|
@xyxiaoyou SQLConf.get ? |
|
|
Hi, @gatorsmile , when using 'create or replace view test_view as...', spark will first generate a 'select...'query job. This causes the create view to be particularly slow. Is there a switch control so that spark does not do queries or create faster when creating a view? |
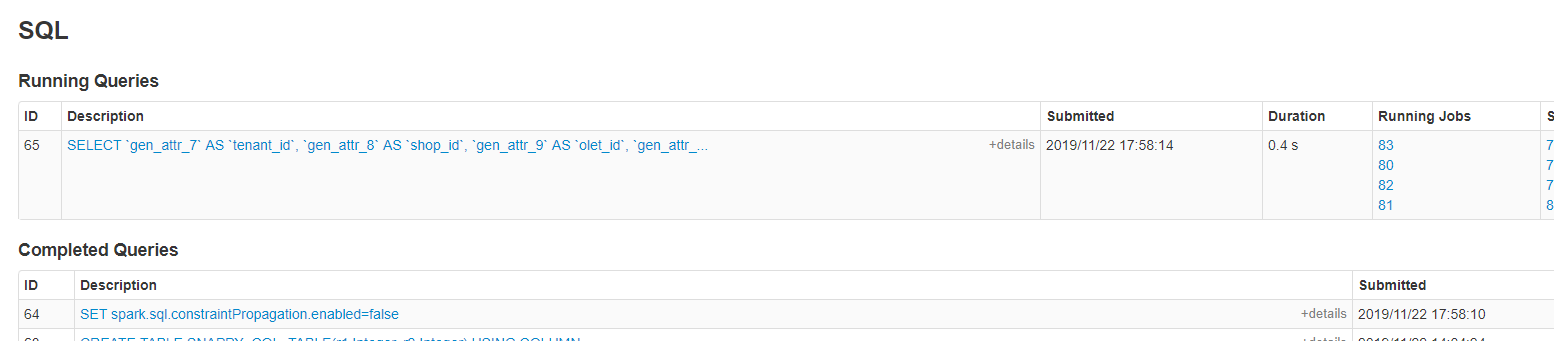
|
|
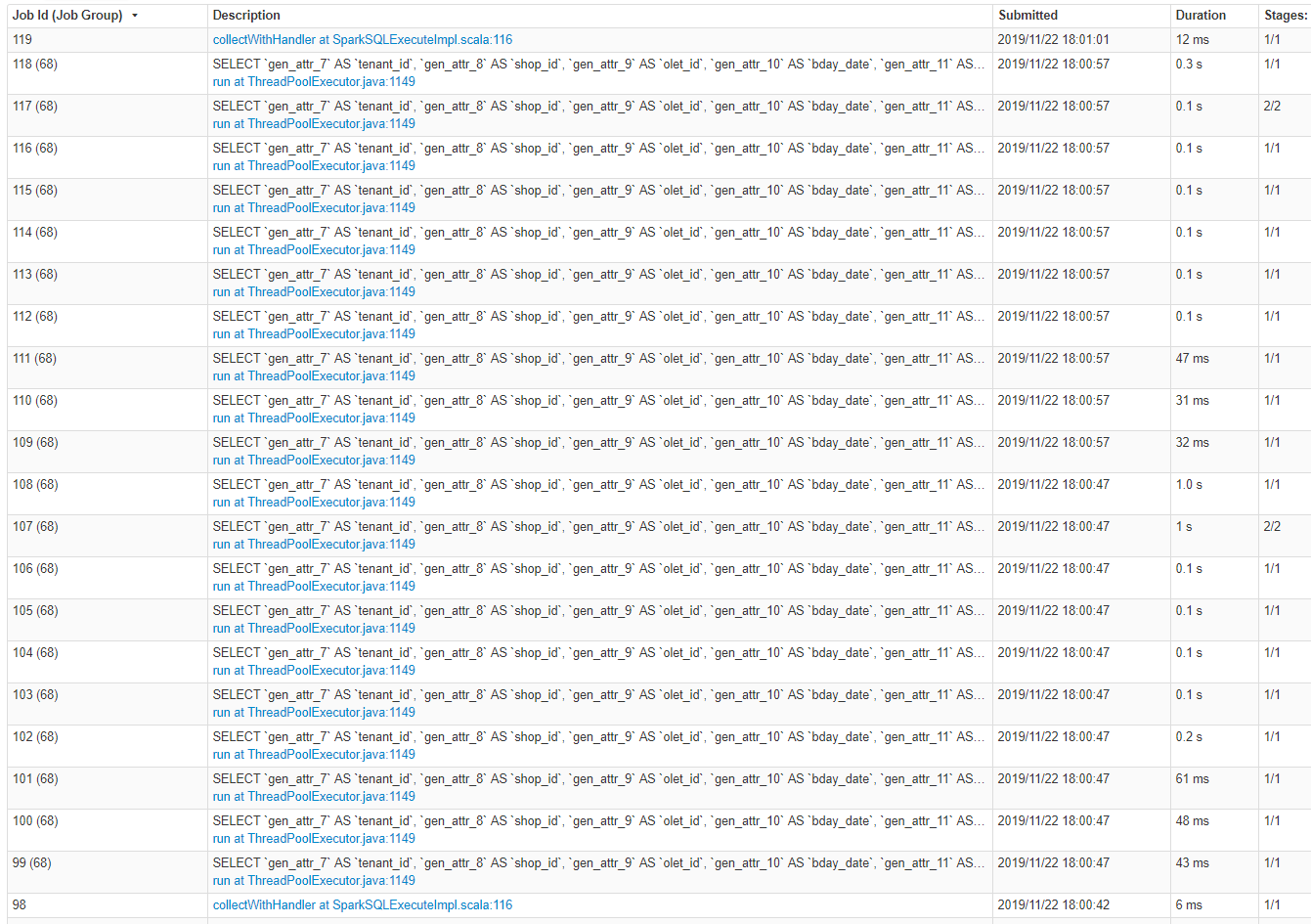
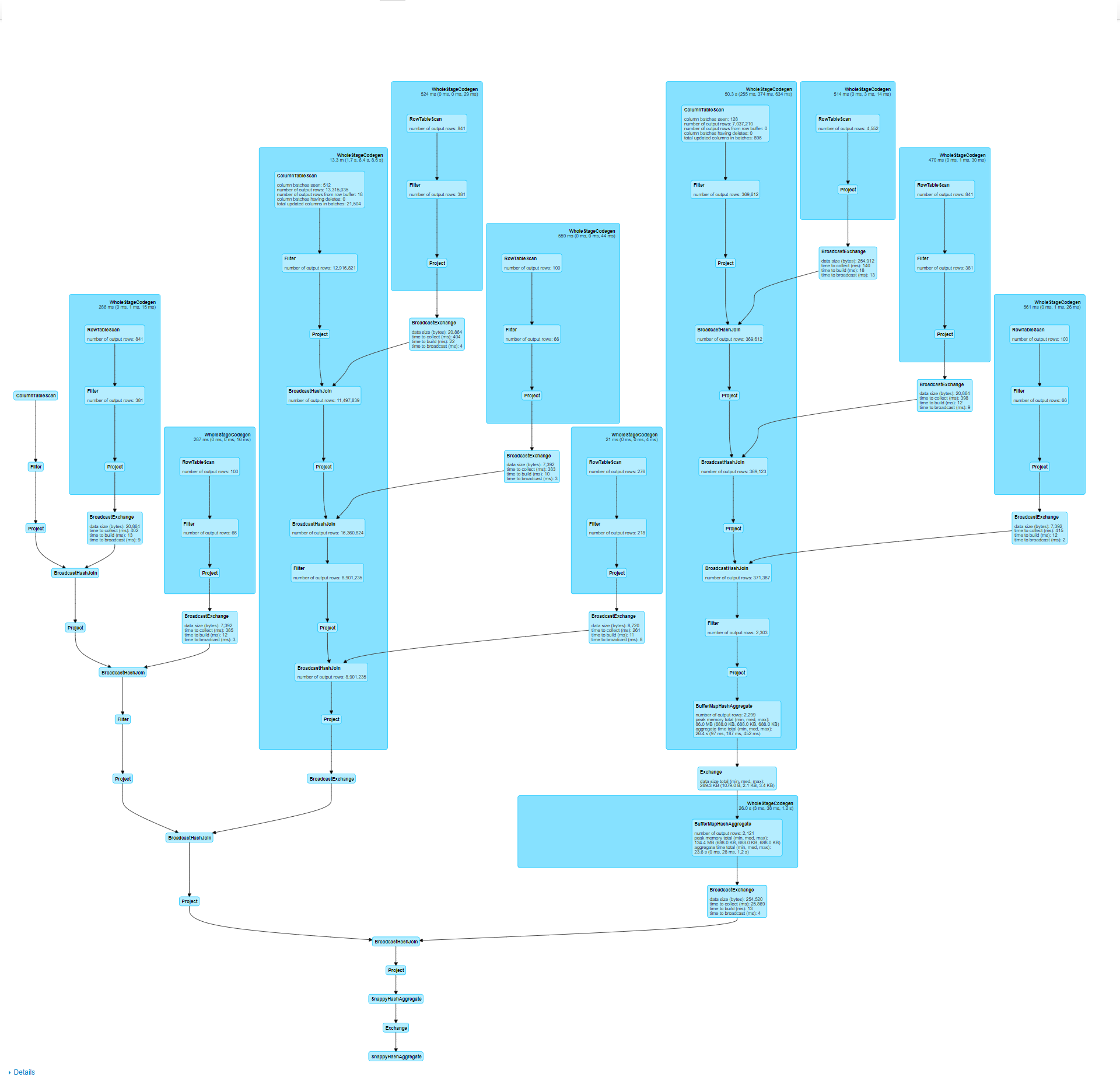
|
@gatorsmile This problem has been bothering our team for a long time, I hope you can give us some suggestions or help us solve it.Thanks a lot. |
|
@xyxiaoyou : for your reference: take a look at https://issues.apache.org/jira/browse/SPARK-33152 |
What changes were proposed in this pull request?
Constraint propagation can be computation expensive and block the driver execution for long time. For example, the below benchmark needs 30mins.
Compared with previous PRs #16998, #16785, this is a much simpler option: add a flag to disable constraint propagation.
Benchmark
Run the following codes locally.
Before this patch: 1786001 ms ~= 30 mins
After this patch: 26392 ms = less than half of a minute
Related PRs: #16998, #16785.
How was this patch tested?
Jenkins tests.
Please review http://spark.apache.org/contributing.html before opening a pull request.