[SPARK-20889][SparkR] Grouped documentation for AGGREGATE column methods #18025
Conversation
|
Per this suggestion, I'm creating more meaningful examples for the SQL functions. In this PR, I implemented grouped documentation for all aggregate functions for Column, except those that are also defined for other classes (
|
|
This is what the
|



|
Test build #77046 has finished for PR 18025 at commit
|
|
so I think better example is great and we might be too verbose with individual pages for each function so might be a good idea to consolidate them, but one question, does this affect discoverability? can function be found on http://spark.apache.org/docs/latest/api/R/index.html |
|
@felixcheung Thanks for your feedback.
Another important benefit is that we can get rid of most warnings on no examples since we now document all the tiny functions together. The new commit now removes all warnings! I feel this change is important and straightforward. However, this is a laborious effort and lots of review work for you guys. Would like to get your thoughts on how to pursue. Maybe I can finish all functions in the datetime group to show the full picture? Thanks. |


|
Test build #77084 has started for PR 18025 at commit |
R/pkg/R/generics.R
Outdated
There was a problem hiding this comment.
what's the reason for the noRd here? I think it's fairly standard to "document" generic - even though it's not useful most of the time
There was a problem hiding this comment.
@felixcheung I intentionally suppressed the documentation for generic functions. The main reason is the documentation of generics conflict with documenting groups of methods together. For example, if I document the avg method for the column class together with other column aggregate methods, here is a couple of scenarios that could happen to the generic avg method:
- Without
@noRd, roxygen will create aavgrd file to document theavggeneric method ONLY. Since in the generics definition, we don't have@titleor@description, the package won't compile. - Suppose we get rid of
@noRd, and document all generics functions under a newgenericsrd name. This will compile, but then we have conflicting definitions of the arguments. For example,...could mean different things in different generics. But this is a minor issue.
The current approach is to suppress the documentation of the generics, since we document each method of the generics. This does not lose any information IMO. The user can always use getGeneric("avg") to get the prototype for the generics. Would like to hear your thoughts.
There was a problem hiding this comment.
hmm, I think some of the problems are orthogonal - for example, to avoid a avg.rd file we could just change avg in generic.R to have @rdname column_aggregate_functions (which is where avg in function.R is changed to)?
I feel the standard is to have documentation on the generic (and have it on the same rd) like https://stat.ethz.ch/R-manual/R-devel/library/base/html/mean.html
R/pkg/R/generics.R
Outdated
There was a problem hiding this comment.
wait - having these here is intentional? if a function supports different type we don't want the documentation to go to DataFrame.R because then Column.R will look empty.
There was a problem hiding this comment.
see here https://github.com/apache/spark/pull/18025/files#diff-04c14efaae2b7b0f0a45038482f2590cR135
how do we decide this goes to Column.R and not DataFrame.R? It's very easy then later on someone else added more comment in DataFrame.R thinking there is no documentation and then later on the help content is duplicated
(this has happened a few times before)
There was a problem hiding this comment.
@felixcheung Thanks for pointing this out. In this case, it should be a Column not a SparkDataFrame or a Column. Indeed, this is a problem of documenting only the generics and inheriting the parameter doc from the generics in each method. Ideally, each specific method of a generic should have its own documentation, not the way we document the generics now. Suppose we have a new method alias for another class, the doc in the generics needs to be updated to include this new class. But it's not clear to the developer where to make the change. If we instead just document each method of the generics, it will be much clearer.
I will do a thorough cleanup of these issues after we decide on the big items.
There was a problem hiding this comment.
wait, I think some wires are crossed. let me clarify. let's take coalesce as an example.
there are 2 coalesce, one coalesce(df) like repartition, and one coalesce(df$foo) on a column like in SQL. so therefore, these are in fact 2 coalesce and x is either a SparkDataFrame or a Column.
and to elaborate, the history behind that approach we have today is because we use to have this
@param x a Column
...
function(x = "Column"...)
and at the same time, in a different .R file
@param x a SparkDataFrame
...
function(x = "SparkDataFrame"
they seem fine when we write the code and it seems logical/easy to maintain, but when the rd/doc page is generated it has
x a SparkDataFrame
x a Column
here x is explained twice. worse, the order is largely random (it's the alphabetic order of the .R file)
and it is going against the standard R pattern of one description line for each parameter with the choice of type separated by .. or.. like https://stat.ethz.ch/R-manual/R-devel/library/stats/html/lm.html, and not to mention CRAN check I think complain about parameter documented more than once.
so in short, having one @param x a SparkDataFrame or a Column is intentional. since this is describing 2 things, from discussions back then it feels more nature to put it some where independent - in fact like you are touching on, I'd argue it's better to look it up in generic.R rather than trying to figure out what other existing overload class that method already has. to be more concrete, like in this change I'd need to know to go to column.R for alias, but DataFrame.R for gapply, but alias is also in DataFrame.R.
|
thanks for looking into this and yes it will be useful to understand better before proceeding further. how does the |
|
@felixcheung Thanks for asking this. I should have been more clear.
In the It now allows the following shortcuts for help search, all of which direct to the same Rd object
Details of R documentation here: |
|
Test build #77105 has finished for PR 18025 at commit
|
|
thanks, I am somewhat familiar with all the tags. I see that you have I think we are trying to remove |
|
@felixcheung Suppose we have new classes and methods on If that's the case, then the idea of grouping different methods by class will not be useful. |
|
I guess this comes from not seeing a lot of S4 methods? In fact, a overwhelming percentage of all methods in packages are S3, and I think users are using to search with granted, I am aware some (many?) of these don't make sense (like coalesce(DF) and coalesce(col) have not much common) and that is a problem. would you propose they go to different page then? would that also solve https://issues.apache.org/jira/browse/SPARK-18825 ? |
|
@felixcheung I think we may want to distinguish a few cases:
Let me know if this makes sense. |
|
Thanks for summarizing. I think they make sense. To be clear though, we should also talk about:
|
|
Great point.
|
would this be too confusing though? particularly if we are moving to -method one per doc page |
|
@felixcheung I just made a new commit which I think has the cleanest solution so far. In this one, I implemented grouping for all aggregate functions for Column, except those that are also defined for other classes (
Of course, the scope of this PR is not to address removing the In this version, I also demonstrate how to handle the methods defined by multiple classes ( Also, to facilitate review, perhaps we can break the changes into several PRs, one for each of After making the change to the Column methods, I will work on the doc for SparkDataFrame and GroupedData. Please let me know your thoughts. |
|
Attaching a snapshot of part of the doc to show the idea.
|



|
Test build #77313 has finished for PR 18025 at commit
|
|
Test build #77318 has finished for PR 18025 at commit
|
|
I think we need to give it a title explicitly - see the header/first line of https://cloud.githubusercontent.com/assets/11082368/26429381/64dd117e-409b-11e7-9661-659b5fbe8206.png |
|
I guess we don't need link to stddev_samp since it's the same page |
|
also, since we have an Rd now what you think about collecting all the example into one - that should eliminate all the I think then also this will be a great opportunity to do more than simple also this #18025 (comment) I like this approach - these are my comments from your screen shot - I'll review more closely after more changes, thanks! |
|
|
re: title, would explicitly adding |
|


|
@felixcheung Your comments are all addressed now. Please let me know if there is anything else needed. |
|
Test build #78149 has finished for PR 18025 at commit
|
|
Test build #78152 has finished for PR 18025 at commit
|
|
Test build #78153 has finished for PR 18025 at commit
|
|
Test build #78190 has finished for PR 18025 at commit
|
|
@felixcheung Could you take another look and let me know if there is anything else needed? |
|
@actuaryzhang, Are |
|
@HyukjinKwon Thanks for catching this. They were incorrectly labeled as math functions instead of aggregate functions in SparkR. And that's why I did not change them. |
|
Test build #78215 has finished for PR 18025 at commit
|
|
Test build #78216 has finished for PR 18025 at commit
|
| #' @examples \dontrun{corr(df$c, df$d)} | ||
| #' @examples | ||
| #' \dontrun{ | ||
| #' df <- createDataFrame(cbind(model = rownames(mtcars), mtcars)) |
There was a problem hiding this comment.
do we need space/newline in front of this example like the other ones?
There was a problem hiding this comment.
this one does not need the extra newline since it's in its own Rd and there are no examples before it.
There was a problem hiding this comment.
great - I know we talk about it, but we might consider getting all examples on the Rd into one \dontrun block again. as of now it's very hard to review new PR without knowing whether a newline is needed or not...
There was a problem hiding this comment.
or maybe we should have a newline at the end of every @example block (when there are multiple examples on one Rd)? This way we don't have to know where goes first
| #' cov <- cov(df, "title", "gender") | ||
| #' } | ||
| #' | ||
| #' \dontrun{ |
There was a problem hiding this comment.
shouldn't the newline be after the dontrun?
There was a problem hiding this comment.
No. The newline should be between @example and \dontrun to separate multiple dontruns. See the screen shot above.
| collect(dataFrame(sct)) | ||
| }) | ||
|
|
||
| #' Calculate the sample covariance of two numerical columns of a SparkDataFrame. |
There was a problem hiding this comment.
hmm, this is one of the tricky ones where there is one page for DataFrame & Columns.
I think it's useful to touch of how this works with a SparkDataFrame and keep this line in some form?
There was a problem hiding this comment.
The method for SparkDataFrame is still there. I'm just removing redundant doc here.
See the screenshot here.


There was a problem hiding this comment.
I see. in that case can we add this in the @details for cov
I feel like this has bits of info that could be useful:
Calculate the sample covariance of two numerical columns of a SparkDataFrame - say, numerical columns of one SparkDataFrame, as supposed to cov(df, df$name, df2$bar)
| #' | ||
| #' @param colName1 the name of the first column | ||
| #' @param colName2 the name of the second column | ||
| #' @return The covariance of the two columns. |
There was a problem hiding this comment.
what would the @return line in the final doc?
There was a problem hiding this comment.
OK. I added this back. The doc should be very clear even without this return value. Indeed, most functions do not document return value in SparkR. See what it looks like in the image above.
There was a problem hiding this comment.
Possibly, but better clarity wouldn't hurt, right?
|
This is how the structure of the doc looks like (this is only snapshot for the main parts for illustration purpose):
|
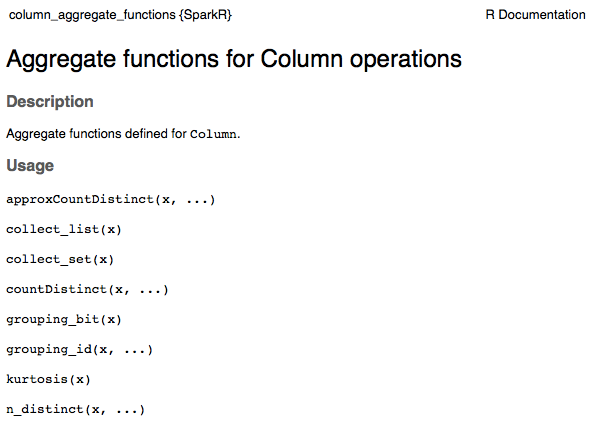


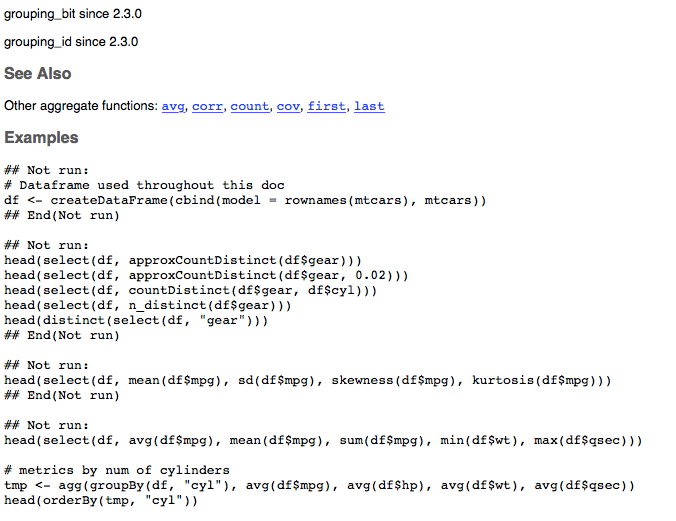
|
Test build #78244 has finished for PR 18025 at commit
|
|
very cool, thanks, I guess there's only this last comment #18025 (comment) |
|
OK. Updated the doc for the cov method for SparkDataFrame. |
|
Test build #78264 has finished for PR 18025 at commit
|
|
haha. I like the |
|
AppVeyor failure is unfortunate. but it passed before a doc only change. |
|
merged to master, thanks! |
## What changes were proposed in this pull request? Grouped documentation for the aggregate functions for Column. Author: actuaryzhang <actuaryzhang10@gmail.com> Closes apache#18025 from actuaryzhang/sparkRDoc4.
What changes were proposed in this pull request?
Grouped documentation for the aggregate functions for Column.