[SPARK-22760][CORE][YARN] When sc.stop() is called, set stopped is true before removing executors #19951
Conversation
|
Test build #84766 has finished for PR 19951 at commit
|
|
Test build #84814 has finished for PR 19951 at commit
|
|
@devaraj-kavali @vanzin ,using #19741, i still find the problem "Could not find CoarseGrainedScheduler", i change the code ,please review, thanks |
|
@yoonlee95 maybe @tgravescs does this make sense? |
|
Overall seems to make sense would like a few more details. there were changes to the dispatcher to try to ignore some of the these errors: these look like different messages then that one as it handled mostly rpcenvstopped. So when these errors come out the dispatcher is not stopped yet? |
|
This seems like a race during shutdown:
You could argue that what the RpcEnv is doing above is sort of fishy (delivering messages to the endpoint after it's already been unregistered), but this looks like an ok workaround. |
|
BTW, it might still be possible to hit that race even with the changes here. I'm not sure there's a way to completely get rid of it, though, so perhaps catching the exception and not logging it if things are stopping might be a more sure way to get rid of the logs. |
|
@tgravescs the job is end, then error log apper. i think this error log will cause illusions to believe the failure of the task. @vanzin Your analysis is right. And i think my code can get rid of this exception. Because when things are stopping, the sc.stopped is set true firstly. So driver endpoint does not need to send messages to itself. |
|
Yeah, but if an executor died right before the context was stopped, the "on disconnect" event might be in the queue when the stop call happens, and trigger the same code path that will throw the exception. |
|
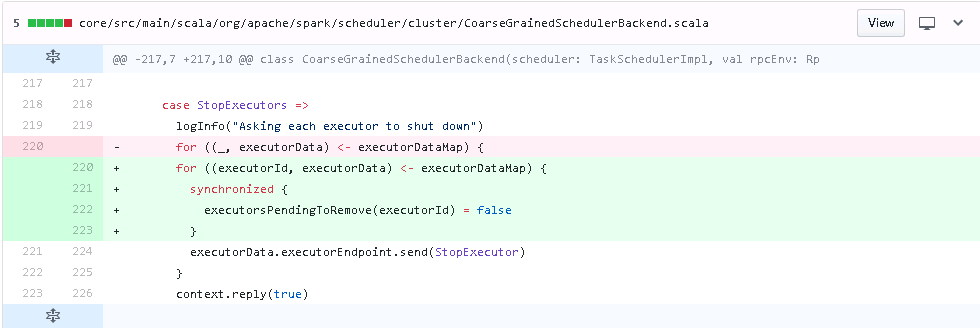
My mean is, |
|
I have another way to modify this problem: when |
|
I know what you're saying. I'm saying that you're not considering another race that also exists in this code. |
|
@vanzin yeah, it is difficult to consider all the race. So i continue to analyze the source code, and i think my another way to solve the problem better. |
|
This is interesting. Thanks for working on it. It seems to me that the race situation is benign here and removing all the race cases will cause some extra communications that may introduce extra over-head. |
|
Test build #88177 has finished for PR 19951 at commit
|
|
It's not possible to differentiate the two race conditions @vanzin described in this code path without adding extra communication loads, since this should be a minor issue and there is no simple fix for it, I'd suggest we close this PR for now and revisit when someone come off a better solution, WDYT @vanzin @tgravescs @rezasafi @srowen @KaiXinXiaoLei ? |
|
Since the target of the fix is silencing a misleading exception, handling that exception as I suggested before would be a feasible solution. But anything more complicated than that is overkill. |
Closes apache#20458 Closes apache#20530 Closes apache#20557 Closes apache#20966 Closes apache#20857 Closes apache#19694 Closes apache#18227 Closes apache#20683 Closes apache#20881 Closes apache#20347 Closes apache#20825 Closes apache#20078 Closes apache#21281 Closes apache#19951 Closes apache#20905 Closes apache#20635 Author: Sean Owen <srowen@gmail.com> Closes apache#21303 from srowen/ClosePRs.
What changes were proposed in this pull request?
When the number of executors is big, and
YarnSchedulerBackend.stop()is running,before
YarnSchedulerBackend.stopped=true, if some executor is stoped, thenYarnSchedulerBackend.onDisconnected()will be called. There is a problem as follows:17/12/12 15:34:45 INFO YarnClientSchedulerBackend: Asking each executor to shut down
17/12/12 15:34:45 INFO YarnClientSchedulerBackend: Disabling executor 63.
17/12/12 15:34:45 ERROR Inbox: Ignoring error
org.apache.spark.SparkException: Could not find CoarseGrainedScheduler or it has been stopped.
at org.apache.spark.rpc.netty.Dispatcher.postMessage(Dispatcher.scala:163)
at org.apache.spark.rpc.netty.Dispatcher.postOneWayMessage(Dispatcher.scala:133)
at org.apache.spark.rpc.netty.NettyRpcEnv.send(NettyRpcEnv.scala:192)
at org.apache.spark.rpc.netty.NettyRpcEndpointRef.send(NettyRpcEnv.scala:516)
at org.apache.spark.scheduler.cluster.CoarseGrainedSchedulerBackend.reviveOffers(CoarseGrainedSchedulerBackend.scala:356)
at org.apache.spark.scheduler.TaskSchedulerImpl.executorLost(TaskSchedulerImpl.scala:497)
at org.apache.spark.scheduler.cluster.CoarseGrainedSchedulerBackend$DriverEndpoint.disableExecutor(CoarseGrainedSchedulerBackend.scala:301)
at org.apache.spark.scheduler.cluster.YarnSchedulerBackend$YarnDriverEndpoint$$anonfun$onDisconnected$1.apply(YarnSchedulerBackend.scala:121)
at org.apache.spark.scheduler.cluster.YarnSchedulerBackend$YarnDriverEndpoint$$anonfun$onDisconnected$1.apply(YarnSchedulerBackend.scala:120)
at scala.Option.foreach(Option.scala:236)
at org.apache.spark.scheduler.cluster.YarnSchedulerBackend$YarnDriverEndpoint.onDisconnected(YarnSchedulerBackend.scala:120)
at org.apache.spark.rpc.netty.Inbox$$anonfun$process$1.apply$mcV$sp(Inbox.scala:142)
at org.apache.spark.rpc.netty.Inbox.safelyCall(Inbox.scala:204)
at org.apache.spark.rpc.netty.Inbox.process(Inbox.scala:100)
at org.apache.spark.rpc.netty.Dispatcher$MessageLoop.run(Dispatcher.scala:217)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)
. So i change the code, when removing executor, check
sc.isStoppedinYarnSchedulerBackend.onDisconnected(). if sc.isStopped=true, the message will not be sent.How was this patch tested?
Run "spark-sql --master yarn -f query.sql" many times, the problem will be exists.
(Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests)
(If this patch involves UI changes, please attach a screenshot; otherwise, remove this)
Please review http://spark.apache.org/contributing.html before opening a pull request.