[SPARK-24215][PySpark] Implement eager evaluation for DataFrame APIs in PySpark #21370
Conversation
|
Not sure who is the right reviewer, maybe @rdblue @gatorsmile ? |
|
Test build #90834 has finished for PR 21370 at commit
|
|
we will wait for the tests to be fixed first. @xuanyuanking could you update the PR description to clarify which screenshot is "before" which is "after"? |
 felixcheung
left a comment
felixcheung
left a comment
There was a problem hiding this comment.
this will need to escape the values to make sure it is legal html too right?
There was a problem hiding this comment.
why all these comment changes? could you revert them
There was a problem hiding this comment.
Sorry for this, I'll revert the IDE changes.
python/pyspark/sql/dataframe.py
Outdated
There was a problem hiding this comment.
let's add all these to documentation too
There was a problem hiding this comment.
Got it. Do it in next commit. Thanks for reminding.
There was a problem hiding this comment.
when the output is truncated, does jupyter handle that properly?
There was a problem hiding this comment.
or does that depend on the html output on L300?
There was a problem hiding this comment.
Yes, the truncated string will be showed in table row and controlled by spark.jupyter.default.truncate
|
retest this please |
docs/configuration.md
Outdated
docs/configuration.md
Outdated
Yes you're right, thanks for your guidance, the new patch consider the escape and add new UT. @felixcheung |
There was a problem hiding this comment.
We need this toString, because the appendRowString method including both column names and data in original logic, which call toString in data part.
https://github.com/apache/spark/pull/21370/files/f2bb8f334631734869ddf5d8ef1eca1fa29d334a#diff-7a46f10c3cedbf013cf255564d9483cdL312
There was a problem hiding this comment.
I know this is not your change, but the rows is already Seq[Seq[String]] and the row is Seq[String], so I think we can remove it.
There was a problem hiding this comment.
I see, the cell.toString has been called here. https://github.com/apache/spark/pull/21370/files/f2bb8f334631734869ddf5d8ef1eca1fa29d334a#diff-7a46f10c3cedbf013cf255564d9483cdR271
Got it, I'll fix this in next commit.
There was a problem hiding this comment.
the "\n" added in seperatedLine:https://github.com/apache/spark/pull/21370/files#diff-7a46f10c3cedbf013cf255564d9483cdR300
There was a problem hiding this comment.
Hmm, the header looks okay, but the data section will be a long line without \n? How about adding \n here and the data section, and just using "" for the seperatedLine?
There was a problem hiding this comment.
Ah, I understand your consideration. I'll add this in next commit.
There was a problem hiding this comment.
Thanks, done. feb5f4a.
docs/configuration.md
Outdated
There was a problem hiding this comment.
spark.jupyter.eagerEval.showRows or something?
There was a problem hiding this comment.
change to spark.jupyter.eagerEval.showRows,thanks
docs/configuration.md
Outdated
There was a problem hiding this comment.
spark.jupyter.eagerEval.truncate or something?
There was a problem hiding this comment.
Yep, change to spark.jupyter.eagerEval.truncate
python/pyspark/sql/dataframe.py
Outdated
There was a problem hiding this comment.
What will be shown if spark.jupyter.eagerEval.enabled is False? Fallback the original automatically?
There was a problem hiding this comment.
We need to return None if self._eager_eval is False.
There was a problem hiding this comment.
What will be shown if spark.jupyter.eagerEval.enabled is False? Fallback the original automatically?
Yes, it will fallback to call __repr__.
We need to return None if self._eager_eval is False.
Got it, more clear in code logic.
python/pyspark/sql/dataframe.py
Outdated
There was a problem hiding this comment.
My bad, sorry for this.
python/pyspark/sql/dataframe.py
Outdated
There was a problem hiding this comment.
I guess we shouldn't hold these three values but define as @property or refer each time in _repr_html_. Otherwise, we'll hit unexpected behavior, e.g.:
df = ...
spark.conf.set("spark.jupyter.eagerEval.enabled", True)
dfwon't show the html.
There was a problem hiding this comment.
Yep, I'll fix it in next commit.
docs/configuration.md
Outdated
There was a problem hiding this comment.
true is better since the default value is false.
|
Test build #90872 has finished for PR 21370 at commit
|
|
Test build #90871 has finished for PR 21370 at commit
|
|
So one thing we might want to take a look at is application/vnd.dataresource+json for tables in the notebooks (see https://github.com/nteract/improved-spark-viz ). |
docs/configuration.md
Outdated
docs/configuration.md
Outdated
There was a problem hiding this comment.
Is it usually we include a JIRA ticket in user document like this? I think we should just briefly describe this feature here.
There was a problem hiding this comment.
Yea, I felt the same thing too but there were the same few instances in this page.
docs/configuration.md
Outdated
There was a problem hiding this comment.
true is better since the default value is false.
There was a problem hiding this comment.
hmm, should we do this html thing in python side?
There was a problem hiding this comment.
We can do this in python side, I implement it in scala side mainly consider to reuse the code and logic of show(), maybe it's more natural in show df as html call showString.
There was a problem hiding this comment.
This should not be done in Dataset.scala.
There was a problem hiding this comment.
Can we create refactor showString to make it reusable for both show and repr_html?
There was a problem hiding this comment.
+1 for reusing relevant parts of show.
There was a problem hiding this comment.
Thanks for guidance, I will do this in next commit.
There was a problem hiding this comment.
@viirya @gatorsmile @rdblue Sorry for the late commit, the refactor do in 94f3414. I spend some time on testing and implementing the transformation of rows between python and scala.
|
Thanks all reviewer's comments, I address all comments in this commit. Please have a look. |
python/pyspark/sql/dataframe.py
Outdated
There was a problem hiding this comment.
Add a simple test for _repr_html too?
There was a problem hiding this comment.
No problem, I'll added in SQLTests in next commit.
There was a problem hiding this comment.
Thanks, done. feb5f4a.
docs/configuration.md
Outdated
There was a problem hiding this comment.
Should we add sql? E.g., spark.sql.jupyter.eagerEval.enabled? Because this is just for SQL Dataset. @HyukjinKwon @ueshin
There was a problem hiding this comment.
Got it, fix it in next commit.
There was a problem hiding this comment.
Is this Jupyter specific? Can we make it more general?
There was a problem hiding this comment.
btw the config flag isn't jupyter specific.
There was a problem hiding this comment.
Maybe rename to spark.sql.repl.eagerEval.enabled instead? It should also be documented that this is a hint. There's no guarantee that the repl you're using supports eager evaluation.
There was a problem hiding this comment.
Thanks, done. feb5f4a.
|
Test build #90896 has finished for PR 21370 at commit
|
python/pyspark/sql/dataframe.py
Outdated
There was a problem hiding this comment.
Add the function descriptions above this line,
There was a problem hiding this comment.
Thanks, done. feb5f4a.
|
Can we also do something a bit more generic that works for non-Jupyter notebooks as well? For example, in IPython or just plain Python REPL. This is in addition to the repl_html stuff which is really cool and useful. |
|
@rxin, |
There was a problem hiding this comment.
I'm sorry, but I don't think we need the middle \n, it's okay with only the last one.
"<tr><th>", "</th><th>", "</th></tr>\n"
There was a problem hiding this comment.
Got it, I'll change it.
There was a problem hiding this comment.
I change the format in python _repr_html_ in 94f3414.
|
Test build #91022 has finished for PR 21370 at commit
|
Can we accept
I test offline an it can work both python shell and Jupyter, if we agree this way, I'll add this support in next commit together will the refactor of showString in scala Dataset.
|
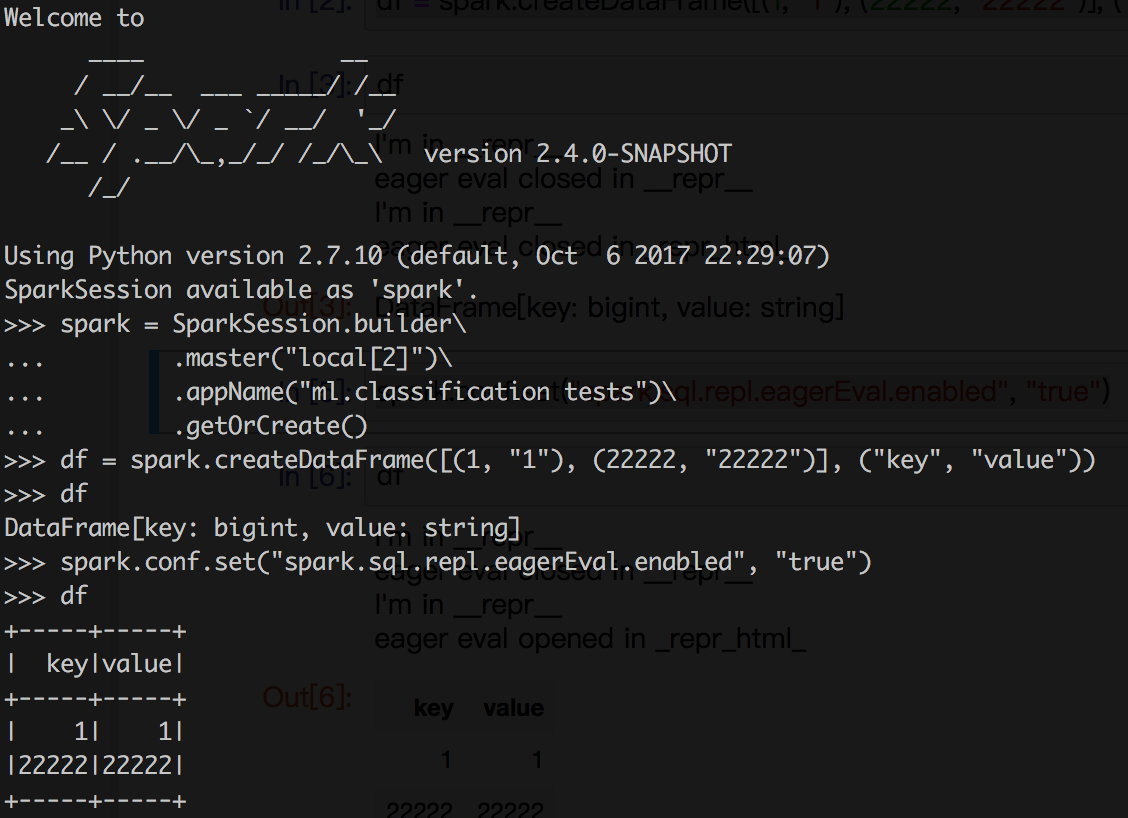
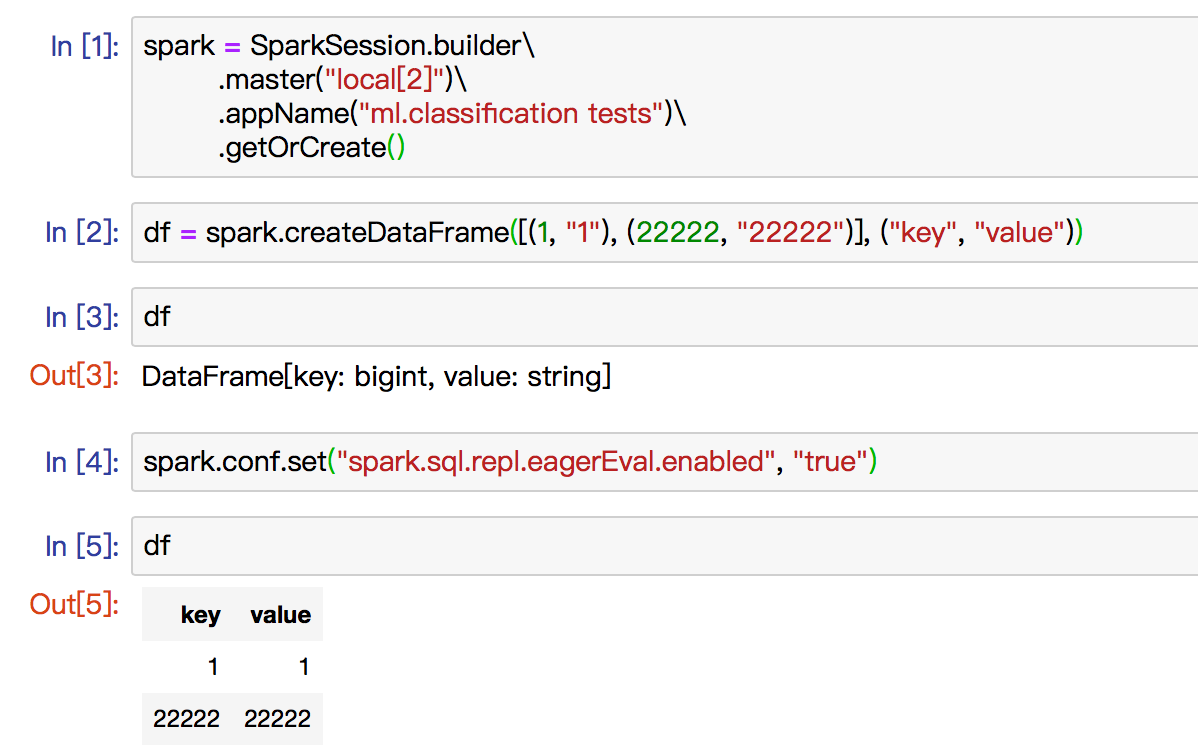
python/pyspark/sql/dataframe.py
Outdated
There was a problem hiding this comment.
I think it works either way. REPL is better in my opinion because these settings should (ideally) apply when using any REPL.
There was a problem hiding this comment.
Thanks, change to REPL in 94f3414.
python/pyspark/sql/tests.py
Outdated
There was a problem hiding this comment.
We don't have to compile the pattern each time here since it's not going to be reused. You could just put this into re.sub I believe.
There was a problem hiding this comment.
Thanks! Fix it in 94f3414.
docs/configuration.md
Outdated
There was a problem hiding this comment.
I don't think it is obvious what "showRows" does. I would assume that it is a boolean, but it is a limit instead. What about calling this "limit" or "numRows"?
There was a problem hiding this comment.
Thanks, change it in 94f3414.
docs/configuration.md
Outdated
There was a problem hiding this comment.
What is the difference between this and showRows? Why are there two properties?
There was a problem hiding this comment.
maybe he wants to follow what dataframe.show does, which truncates num characters within a cell. That's useful for console output, but not so much for notebooks.
There was a problem hiding this comment.
Yep, I just want to keep the same behavior of dataframe.show.
That's useful for console output, but not so much for notebooks.
Notebooks aren't afraid for too many characters within a cell, so I just delete this?
python/pyspark/sql/dataframe.py
Outdated
There was a problem hiding this comment.
I agree that it would be better to respect spark.sql.repr.eagerEval.enabled here as well.
There was a problem hiding this comment.
Thanks for your reply, this implement in 94f3414.
python/pyspark/sql/dataframe.py
Outdated
There was a problem hiding this comment.
use named arguments for boolean flags
There was a problem hiding this comment.
Thanks, fix in 94f3414.
|
Test build #91449 has finished for PR 21370 at commit
|
|
Merged to master |
|
Thanks @HyukjinKwon and all reviewers. |
| <td>20</td> | ||
| <td> | ||
| Default number of rows in eager evaluation output HTML table generated by <code>_repr_html_</code> or plain text, | ||
| this only take effect when <code>spark.sql.repl.eagerEval.enabled</code> is set to true. |
| <td>20</td> | ||
| <td> | ||
| Default number of truncate in eager evaluation output HTML table generated by <code>_repr_html_</code> or | ||
| plain text, this only take effect when <code>spark.sql.repl.eagerEval.enabled</code> set to true. |
There was a problem hiding this comment.
Got it, thanks, address in next follow up PR.
|
@xuanyuanking @HyukjinKwon Sorry for the delay. Super busy in the week of Spark summit. Will carefully review this PR today or tomorrow. |
| finally: | ||
| shutil.rmtree(path) | ||
|
|
||
| def test_repr_html(self): |
There was a problem hiding this comment.
This function only covers the most basic positive case. We need also add more test cases. For example, the results when spark.sql.repl.eagerEval.enabled is set to false.
There was a problem hiding this comment.
Got it, the follow up pr will enhance this test.
| truncate: Int, | ||
| vertical: Boolean): Array[Any] = { | ||
| EvaluatePython.registerPicklers() | ||
| val numRows = _numRows.max(0).min(Int.MaxValue - 1) |
There was a problem hiding this comment.
This should be also part of the conf description.
There was a problem hiding this comment.
Got it, will be fixed in another pr.
| self._support_repr_html = True | ||
| if self._eager_eval: | ||
| max_num_rows = max(self._max_num_rows, 0) | ||
| vertical = False |
There was a problem hiding this comment.
Yes, the discussion before linked below:
#21370 (comment)
and
#21370 (comment)
We need a named arguments for boolean flags here, but here limited by the named arguments can't work during python call _jdf func, so we do the work around like this.
| from JVM to Python worker for every task. | ||
| </td> | ||
| </tr> | ||
| <tr> |
There was a problem hiding this comment.
All the SQL configurations should follow what we did in the section of Spark SQL https://spark.apache.org/docs/latest/configuration.html#spark-sql.
There was a problem hiding this comment.
These confs are not part of spark.sql("SET -v").show(numRows = 200, truncate = false).
There was a problem hiding this comment.
Got it, I'll add there configurations into SQLConf.scala in the follow up pr.
| """Returns true if the eager evaluation enabled. | ||
| """ | ||
| return self.sql_ctx.getConf( | ||
| "spark.sql.repl.eagerEval.enabled", "false").lower() == "true" |
There was a problem hiding this comment.
Is that possible we can avoid hard-coding these conf key values? cc @ueshin @HyukjinKwon
There was a problem hiding this comment.
Probably, we should access to SQLConf object. 1. Agree with not hardcoding it in general but 2. IMHO I want to avoid Py4J JVM accesses in the test because the test can likely be more flaky up to my knowledge, on the other hand (unlike Scala or Java side).
Maybe we should try to take a look about this hardcoding if we see more occurrences next time
There was a problem hiding this comment.
In the ongoing release, a nice-to-have refactoring is to move all the Core Confs into a single file just like what we did in Spark SQL Conf. Default values, boundary checking, types and descriptions. Thus, in PySpark, it would be better to do it starting from now.
| } | ||
| } | ||
|
|
||
| private[sql] def getRowsToPython( |
There was a problem hiding this comment.
In DataFrameSuite, we have multiple test cases for showString instead of getRows , which is introduced in this PR.
We also need the unit test cases for getRowsToPython.
There was a problem hiding this comment.
Got it, the follow up pr I'm working on will add more test for getRows and getRowsToPython.
|
@xuanyuanking Thanks for your contributions! Test coverage is the most critical when we refactor the existing code and add new features. Hopefully, when you submit new PRs in the future, could you also improve this part? |
| <td><code>spark.sql.repl.eagerEval.enabled</code></td> | ||
| <td>false</td> | ||
| <td> | ||
| Enable eager evaluation or not. If true and the REPL you are using supports eager evaluation, |
There was a problem hiding this comment.
Just a question. When the REPL does not support eager evaluation, could we do anything better instead of silently ignoring the user inputs?
There was a problem hiding this comment.
Maybe it's hard to have a better way because we can hardly perceive it in dataset while REPL does not support eager evaluation.
There was a problem hiding this comment.
I don't completely follow actually - what makes a "REPL does not support eager evaluation"?
in fact, this "eager evaluation" is just object rendering support build into REPL, notebook etc (like print), it's not really a design to be "eager evaluation"
There was a problem hiding this comment.
That is true. We are not adding the eager execution in the our Dataset/DataFrame. We just rely on the REPL to trigger it. We need an update on the parameter description to emphasize it.
| return int(self.sql_ctx.getConf( | ||
| "spark.sql.repl.eagerEval.truncate", "20")) | ||
|
|
||
| def __repr__(self): |
There was a problem hiding this comment.
This PR also changed __repr__. Thus, we need to update the PR title and description. A better PR title should be like Implement eager evaluation for DataFrame APIs in PySpark
There was a problem hiding this comment.
Done for this and also the PR description as your comment, sorry for this and I'll pay more attention to that next time when the implementation changes during PR review. Is there any way to change the committed git log? Sorry for this.
Of cause and sorry for the late reply, I'll do this in a follow up PR and answer all question from Xiao this night. Thanks for all your comments. |
|
@xuanyuanking Just for your reference, for this PR, the PR description can be improved to something like
|
| val toJava: (Any) => Any = EvaluatePython.toJava(_, ArrayType(ArrayType(StringType))) | ||
| val iter: Iterator[Array[Byte]] = new SerDeUtil.AutoBatchedPickler( | ||
| rows.iterator.map(toJava)) | ||
| PythonRDD.serveIterator(iter, "serve-GetRows") |
There was a problem hiding this comment.
PythonRDD.serveIterator(iter, "serve-GetRows") returns Int, but the return type of getRowsToPython is Array[Any]. How does it work? cc @xuanyuanking @HyukjinKwon
There was a problem hiding this comment.
I think we return Array[Any] for PythonRDD.serveIterator too.
Did I maybe miss something?
There was a problem hiding this comment.
Same answer with @HyukjinKwon about the return type, and actually the exact return type we need here is Array[Array[String]], this defined in toJava func.
There was a problem hiding this comment.
The changes of the return types were made in a commit [PYSPARK] Update py4j to version 0.10.7.... No PR was opened...
There was a problem hiding this comment.
re the py4j commit - there's a good reason for it @gatorsmile
not sure if the change to return type is required with the py4j change though
There was a problem hiding this comment.
I think we better don't talk about this here though.
…Frame APIs in PySpark ## What changes were proposed in this pull request? Address comments in #21370 and add more test. ## How was this patch tested? Enhance test in pyspark/sql/test.py and DataFrameSuite Author: Yuanjian Li <xyliyuanjian@gmail.com> Closes #21553 from xuanyuanking/SPARK-24215-follow.
* [SPARK-24381][TESTING] Add unit tests for NOT IN subquery around null values
## What changes were proposed in this pull request?
This PR adds several unit tests along the `cols NOT IN (subquery)` pathway. There are a scattering of tests here and there which cover this codepath, but there doesn't seem to be a unified unit test of the correctness of null-aware anti joins anywhere. I have also added a brief explanation of how this expression behaves in SubquerySuite. Lastly, I made some clarifying changes in the NOT IN pathway in RewritePredicateSubquery.
## How was this patch tested?
Added unit tests! There should be no behavioral change in this PR.
Author: Miles Yucht <miles@databricks.com>
Closes #21425 from mgyucht/spark-24381.
* [SPARK-24334] Fix race condition in ArrowPythonRunner causes unclean shutdown of Arrow memory allocator
## What changes were proposed in this pull request?
There is a race condition of closing Arrow VectorSchemaRoot and Allocator in the writer thread of ArrowPythonRunner.
The race results in memory leak exception when closing the allocator. This patch removes the closing routine from the TaskCompletionListener and make the writer thread responsible for cleaning up the Arrow memory.
This issue be reproduced by this test:
```
def test_memory_leak(self):
from pyspark.sql.functions import pandas_udf, col, PandasUDFType, array, lit, explode
# Have all data in a single executor thread so it can trigger the race condition easier
with self.sql_conf({'spark.sql.shuffle.partitions': 1}):
df = self.spark.range(0, 1000)
df = df.withColumn('id', array([lit(i) for i in range(0, 300)])) \
.withColumn('id', explode(col('id'))) \
.withColumn('v', array([lit(i) for i in range(0, 1000)]))
pandas_udf(df.schema, PandasUDFType.GROUPED_MAP)
def foo(pdf):
xxx
return pdf
result = df.groupby('id').apply(foo)
with QuietTest(self.sc):
with self.assertRaises(py4j.protocol.Py4JJavaError) as context:
result.count()
self.assertTrue('Memory leaked' not in str(context.exception))
```
Note: Because of the race condition, the test case cannot reproduce the issue reliably so it's not added to test cases.
## How was this patch tested?
Because of the race condition, the bug cannot be unit test easily. So far it has only happens on large amount of data. This is currently tested manually.
Author: Li Jin <ice.xelloss@gmail.com>
Closes #21397 from icexelloss/SPARK-24334-arrow-memory-leak.
* [SPARK-24373][SQL] Add AnalysisBarrier to RelationalGroupedDataset's and KeyValueGroupedDataset's child
## What changes were proposed in this pull request?
When we create a `RelationalGroupedDataset` or a `KeyValueGroupedDataset` we set its child to the `logicalPlan` of the `DataFrame` we need to aggregate. Since the `logicalPlan` is already analyzed, we should not analyze it again. But this happens when the new plan of the aggregate is analyzed.
The current behavior in most of the cases is likely to produce no harm, but in other cases re-analyzing an analyzed plan can change it, since the analysis is not idempotent. This can cause issues like the one described in the JIRA (missing to find a cached plan).
The PR adds an `AnalysisBarrier` to the `logicalPlan` which is used as child of `RelationalGroupedDataset` or a `KeyValueGroupedDataset`.
## How was this patch tested?
added UT
Author: Marco Gaido <marcogaido91@gmail.com>
Closes #21432 from mgaido91/SPARK-24373.
* [SPARK-24392][PYTHON] Label pandas_udf as Experimental
## What changes were proposed in this pull request?
The pandas_udf functionality was introduced in 2.3.0, but is not completely stable and still evolving. This adds a label to indicate it is still an experimental API.
## How was this patch tested?
NA
Author: Bryan Cutler <cutlerb@gmail.com>
Closes #21435 from BryanCutler/arrow-pandas_udf-experimental-SPARK-24392.
* [SPARK-19613][SS][TEST] Random.nextString is not safe for directory namePrefix
## What changes were proposed in this pull request?
`Random.nextString` is good for generating random string data, but it's not proper for directory name prefix in `Utils.createDirectory(tempDir, Random.nextString(10))`. This PR uses more safe directory namePrefix.
```scala
scala> scala.util.Random.nextString(10)
res0: String = 馨쭔ᎰႻ穚䃈兩㻞藑並
```
```scala
StateStoreRDDSuite:
- versioning and immutability
- recovering from files
- usage with iterators - only gets and only puts
- preferred locations using StateStoreCoordinator *** FAILED ***
java.io.IOException: Failed to create a temp directory (under /.../spark/sql/core/target/tmp/StateStoreRDDSuite8712796397908632676) after 10 attempts!
at org.apache.spark.util.Utils$.createDirectory(Utils.scala:295)
at org.apache.spark.sql.execution.streaming.state.StateStoreRDDSuite$$anonfun$13$$anonfun$apply$6.apply(StateStoreRDDSuite.scala:152)
at org.apache.spark.sql.execution.streaming.state.StateStoreRDDSuite$$anonfun$13$$anonfun$apply$6.apply(StateStoreRDDSuite.scala:149)
at org.apache.spark.sql.catalyst.util.package$.quietly(package.scala:42)
at org.apache.spark.sql.execution.streaming.state.StateStoreRDDSuite$$anonfun$13.apply(StateStoreRDDSuite.scala:149)
at org.apache.spark.sql.execution.streaming.state.StateStoreRDDSuite$$anonfun$13.apply(StateStoreRDDSuite.scala:149)
...
- distributed test *** FAILED ***
java.io.IOException: Failed to create a temp directory (under /.../spark/sql/core/target/tmp/StateStoreRDDSuite8712796397908632676) after 10 attempts!
at org.apache.spark.util.Utils$.createDirectory(Utils.scala:295)
```
## How was this patch tested?
Pass the existing tests.StateStoreRDDSuite:
Author: Dongjoon Hyun <dongjoon@apache.org>
Closes #21446 from dongjoon-hyun/SPARK-19613.
* [SPARK-24377][SPARK SUBMIT] make --py-files work in non pyspark application
## What changes were proposed in this pull request?
For some Spark applications, though they're a java program, they require not only jar dependencies, but also python dependencies. One example is Livy remote SparkContext application, this application is actually an embedded REPL for Scala/Python/R, it will not only load in jar dependencies, but also python and R deps, so we should specify not only "--jars", but also "--py-files".
Currently for a Spark application, --py-files can only be worked for a pyspark application, so it will not be worked in the above case. So here propose to remove such restriction.
Also we tested that "spark.submit.pyFiles" only supports quite limited scenario (client mode with local deps), so here also expand the usage of "spark.submit.pyFiles" to be alternative of --py-files.
## How was this patch tested?
UT added.
Author: jerryshao <sshao@hortonworks.com>
Closes #21420 from jerryshao/SPARK-24377.
* [SPARK-24250][SQL][FOLLOW-UP] support accessing SQLConf inside tasks
## What changes were proposed in this pull request?
We should not stop users from calling `getActiveSession` and `getDefaultSession` in executors. To not break the existing behaviors, we should simply return None.
## How was this patch tested?
N/A
Author: Xiao Li <gatorsmile@gmail.com>
Closes #21436 from gatorsmile/followUpSPARK-24250.
* [SPARK-23991][DSTREAMS] Fix data loss when WAL write fails in allocateBlocksToBatch
When blocks tried to get allocated to a batch and WAL write fails then the blocks will be removed from the received block queue. This fact simply produces data loss because the next allocation will not find the mentioned blocks in the queue.
In this PR blocks will be removed from the received queue only if WAL write succeded.
Additional unit test.
Author: Gabor Somogyi <gabor.g.somogyi@gmail.com>
Closes #21430 from gaborgsomogyi/SPARK-23991.
Change-Id: I5ead84f0233f0c95e6d9f2854ac2ff6906f6b341
* [SPARK-24371][SQL] Added isInCollection in DataFrame API for Scala and Java.
## What changes were proposed in this pull request?
Implemented **`isInCollection `** in DataFrame API for both Scala and Java, so users can do
```scala
val profileDF = Seq(
Some(1), Some(2), Some(3), Some(4),
Some(5), Some(6), Some(7), None
).toDF("profileID")
val validUsers: Seq[Any] = Seq(6, 7.toShort, 8L, "3")
val result = profileDF.withColumn("isValid", $"profileID". isInCollection(validUsers))
result.show(10)
"""
+---------+-------+
|profileID|isValid|
+---------+-------+
| 1| false|
| 2| false|
| 3| true|
| 4| false|
| 5| false|
| 6| true|
| 7| true|
| null| null|
+---------+-------+
""".stripMargin
```
## How was this patch tested?
Several unit tests are added.
Author: DB Tsai <d_tsai@apple.com>
Closes #21416 from dbtsai/optimize-set.
* [SPARK-24365][SQL] Add Data Source write benchmark
## What changes were proposed in this pull request?
Add Data Source write benchmark. So that it would be easier to measure the writer performance.
Author: Gengliang Wang <gengliang.wang@databricks.com>
Closes #21409 from gengliangwang/parquetWriteBenchmark.
* [SPARK-24331][SPARKR][SQL] Adding arrays_overlap, array_repeat, map_entries to SparkR
## What changes were proposed in this pull request?
The PR adds functions `arrays_overlap`, `array_repeat`, `map_entries` to SparkR.
## How was this patch tested?
Tests added into R/pkg/tests/fulltests/test_sparkSQL.R
## Examples
### arrays_overlap
```
df <- createDataFrame(list(list(list(1L, 2L), list(3L, 1L)),
list(list(1L, 2L), list(3L, 4L)),
list(list(1L, NA), list(3L, 4L))))
collect(select(df, arrays_overlap(df[[1]], df[[2]])))
```
```
arrays_overlap(_1, _2)
1 TRUE
2 FALSE
3 NA
```
### array_repeat
```
df <- createDataFrame(list(list("a", 3L), list("b", 2L)))
collect(select(df, array_repeat(df[[1]], df[[2]])))
```
```
array_repeat(_1, _2)
1 a, a, a
2 b, b
```
```
collect(select(df, array_repeat(df[[1]], 2L)))
```
```
array_repeat(_1, 2)
1 a, a
2 b, b
```
### map_entries
```
df <- createDataFrame(list(list(map = as.environment(list(x = 1, y = 2)))))
collect(select(df, map_entries(df$map)))
```
```
map_entries(map)
1 x, 1, y, 2
```
Author: Marek Novotny <mn.mikke@gmail.com>
Closes #21434 from mn-mikke/SPARK-24331.
* [SPARK-23754][PYTHON] Re-raising StopIteration in client code
## What changes were proposed in this pull request?
Make sure that `StopIteration`s raised in users' code do not silently interrupt processing by spark, but are raised as exceptions to the users. The users' functions are wrapped in `safe_iter` (in `shuffle.py`), which re-raises `StopIteration`s as `RuntimeError`s
## How was this patch tested?
Unit tests, making sure that the exceptions are indeed raised. I am not sure how to check whether a `Py4JJavaError` contains my exception, so I simply looked for the exception message in the java exception's `toString`. Can you propose a better way?
## License
This is my original work, licensed in the same way as spark
Author: e-dorigatti <emilio.dorigatti@gmail.com>
Author: edorigatti <emilio.dorigatti@gmail.com>
Closes #21383 from e-dorigatti/fix_spark_23754.
* [SPARK-24419][BUILD] Upgrade SBT to 0.13.17 with Scala 2.10.7 for JDK9+
## What changes were proposed in this pull request?
Upgrade SBT to 0.13.17 with Scala 2.10.7 for JDK9+
## How was this patch tested?
Existing tests
Author: DB Tsai <d_tsai@apple.com>
Closes #21458 from dbtsai/sbt.
* [SPARK-24369][SQL] Correct handling for multiple distinct aggregations having the same argument set
## What changes were proposed in this pull request?
This pr fixed an issue when having multiple distinct aggregations having the same argument set, e.g.,
```
scala>: paste
val df = sql(
s"""SELECT corr(DISTINCT x, y), corr(DISTINCT y, x), count(*)
| FROM (VALUES (1, 1), (2, 2), (2, 2)) t(x, y)
""".stripMargin)
java.lang.RuntimeException
You hit a query analyzer bug. Please report your query to Spark user mailing list.
```
The root cause is that `RewriteDistinctAggregates` can't detect multiple distinct aggregations if they have the same argument set. This pr modified code so that `RewriteDistinctAggregates` could count the number of aggregate expressions with `isDistinct=true`.
## How was this patch tested?
Added tests in `DataFrameAggregateSuite`.
Author: Takeshi Yamamuro <yamamuro@apache.org>
Closes #21443 from maropu/SPARK-24369.
* [SPARK-24384][PYTHON][SPARK SUBMIT] Add .py files correctly into PythonRunner in submit with client mode in spark-submit
## What changes were proposed in this pull request?
In client side before context initialization specifically, .py file doesn't work in client side before context initialization when the application is a Python file. See below:
```
$ cat /home/spark/tmp.py
def testtest():
return 1
```
This works:
```
$ cat app.py
import pyspark
pyspark.sql.SparkSession.builder.getOrCreate()
import tmp
print("************************%s" % tmp.testtest())
$ ./bin/spark-submit --master yarn --deploy-mode client --py-files /home/spark/tmp.py app.py
...
************************1
```
but this doesn't:
```
$ cat app.py
import pyspark
import tmp
pyspark.sql.SparkSession.builder.getOrCreate()
print("************************%s" % tmp.testtest())
$ ./bin/spark-submit --master yarn --deploy-mode client --py-files /home/spark/tmp.py app.py
Traceback (most recent call last):
File "/home/spark/spark/app.py", line 2, in <module>
import tmp
ImportError: No module named tmp
```
### How did it happen?
In client mode specifically, the paths are being added into PythonRunner as are:
https://github.com/apache/spark/blob/628c7b517969c4a7ccb26ea67ab3dd61266073ca/core/src/main/scala/org/apache/spark/deploy/SparkSubmit.scala#L430
https://github.com/apache/spark/blob/628c7b517969c4a7ccb26ea67ab3dd61266073ca/core/src/main/scala/org/apache/spark/deploy/PythonRunner.scala#L49-L88
The problem here is, .py file shouldn't be added as are since `PYTHONPATH` expects a directory or an archive like zip or egg.
### How does this PR fix?
We shouldn't simply just add its parent directory because other files in the parent directory could also be added into the `PYTHONPATH` in client mode before context initialization.
Therefore, we copy .py files into a temp directory for .py files and add it to `PYTHONPATH`.
## How was this patch tested?
Unit tests are added and manually tested in both standalond and yarn client modes with submit.
Author: hyukjinkwon <gurwls223@apache.org>
Closes #21426 from HyukjinKwon/SPARK-24384.
* [SPARK-23161][PYSPARK][ML] Add missing APIs to Python GBTClassifier
## What changes were proposed in this pull request?
Add featureSubsetStrategy in GBTClassifier and GBTRegressor. Also make GBTClassificationModel inherit from JavaClassificationModel instead of prediction model so it will have numClasses.
## How was this patch tested?
Add tests in doctest
Author: Huaxin Gao <huaxing@us.ibm.com>
Closes #21413 from huaxingao/spark-23161.
* [SPARK-23901][SQL] Add masking functions
## What changes were proposed in this pull request?
The PR adds the masking function as they are described in Hive's documentation: https://cwiki.apache.org/confluence/display/Hive/LanguageManual+UDF#LanguageManualUDF-DataMaskingFunctions.
This means that only `string`s are accepted as parameter for the masking functions.
## How was this patch tested?
added UTs
Author: Marco Gaido <marcogaido91@gmail.com>
Closes #21246 from mgaido91/SPARK-23901.
* [SPARK-24276][SQL] Order of literals in IN should not affect semantic equality
## What changes were proposed in this pull request?
When two `In` operators are created with the same list of values, but different order, we are considering them as semantically different. This is wrong, since they have the same semantic meaning.
The PR adds a canonicalization rule which orders the literals in the `In` operator so the semantic equality works properly.
## How was this patch tested?
added UT
Author: Marco Gaido <marcogaido91@gmail.com>
Closes #21331 from mgaido91/SPARK-24276.
* [SPARK-24337][CORE] Improve error messages for Spark conf values
## What changes were proposed in this pull request?
Improve the exception messages when retrieving Spark conf values to include the key name when the value is invalid.
## How was this patch tested?
Unit tests for all get* operations in SparkConf that require a specific value format
Author: William Sheu <william.sheu@databricks.com>
Closes #21454 from PenguinToast/SPARK-24337-spark-config-errors.
* [SPARK-24146][PYSPARK][ML] spark.ml parity for sequential pattern mining - PrefixSpan: Python API
## What changes were proposed in this pull request?
spark.ml parity for sequential pattern mining - PrefixSpan: Python API
## How was this patch tested?
doctests
Author: WeichenXu <weichen.xu@databricks.com>
Closes #21265 from WeichenXu123/prefix_span_py.
* [WEBUI] Avoid possibility of script in query param keys
As discussed separately, this avoids the possibility of XSS on certain request param keys.
CC vanzin
Author: Sean Owen <srowen@gmail.com>
Closes #21464 from srowen/XSS2.
* [SPARK-24414][UI] Calculate the correct number of tasks for a stage.
This change takes into account all non-pending tasks when calculating
the number of tasks to be shown. This also means that when the stage
is pending, the task table (or, in fact, most of the data in the stage
page) will not be rendered.
I also fixed the label when the known number of tasks is larger than
the recorded number of tasks (it was inverted).
Author: Marcelo Vanzin <vanzin@cloudera.com>
Closes #21457 from vanzin/SPARK-24414.
* [SPARK-24397][PYSPARK] Added TaskContext.getLocalProperty(key) in Python
## What changes were proposed in this pull request?
This adds a new API `TaskContext.getLocalProperty(key)` to the Python TaskContext. It mirrors the Java TaskContext API of returning a string value if the key exists, or None if the key does not exist.
## How was this patch tested?
New test added.
Author: Tathagata Das <tathagata.das1565@gmail.com>
Closes #21437 from tdas/SPARK-24397.
* [SPARK-23900][SQL] format_number support user specifed format as argument
## What changes were proposed in this pull request?
`format_number` support user specifed format as argument. For example:
```sql
spark-sql> SELECT format_number(12332.123456, '##################.###');
12332.123
```
## How was this patch tested?
unit test
Author: Yuming Wang <yumwang@ebay.com>
Closes #21010 from wangyum/SPARK-23900.
* [SPARK-24232][K8S] Add support for secret env vars
## What changes were proposed in this pull request?
* Allows to refer a secret as an env var.
* Introduces new config properties in the form: spark.kubernetes{driver,executor}.secretKeyRef.ENV_NAME=name:key
ENV_NAME is case sensitive.
* Updates docs.
* Adds required unit tests.
## How was this patch tested?
Manually tested and confirmed that the secrets exist in driver's and executor's container env.
Also job finished successfully.
First created a secret with the following yaml:
```
apiVersion: v1
kind: Secret
metadata:
name: test-secret
data:
username: c3RhdnJvcwo=
password: Mzk1MjgkdmRnN0pi
-------
$ echo -n 'stavros' | base64
c3RhdnJvcw==
$ echo -n '39528$vdg7Jb' | base64
MWYyZDFlMmU2N2Rm
```
Run a job as follows:
```./bin/spark-submit \
--master k8s://http://localhost:9000 \
--deploy-mode cluster \
--name spark-pi \
--class org.apache.spark.examples.SparkPi \
--conf spark.executor.instances=1 \
--conf spark.kubernetes.container.image=skonto/spark:k8envs3 \
--conf spark.kubernetes.driver.secretKeyRef.MY_USERNAME=test-secret:username \
--conf spark.kubernetes.driver.secretKeyRef.My_password=test-secret:password \
--conf spark.kubernetes.executor.secretKeyRef.MY_USERNAME=test-secret:username \
--conf spark.kubernetes.executor.secretKeyRef.My_password=test-secret:password \
local:///opt/spark/examples/jars/spark-examples_2.11-2.4.0-SNAPSHOT.jar 10000
```
Secret loaded correctly at the driver container:

Also if I log into the exec container:
kubectl exec -it spark-pi-1526555613156-exec-1 bash
bash-4.4# env
> SPARK_EXECUTOR_MEMORY=1g
> SPARK_EXECUTOR_CORES=1
> LANG=C.UTF-8
> HOSTNAME=spark-pi-1526555613156-exec-1
> SPARK_APPLICATION_ID=spark-application-1526555618626
> **MY_USERNAME=stavros**
>
> JAVA_HOME=/usr/lib/jvm/java-1.8-openjdk
> KUBERNETES_PORT_443_TCP_PROTO=tcp
> KUBERNETES_PORT_443_TCP_ADDR=10.100.0.1
> JAVA_VERSION=8u151
> KUBERNETES_PORT=tcp://10.100.0.1:443
> PWD=/opt/spark/work-dir
> HOME=/root
> SPARK_LOCAL_DIRS=/var/data/spark-b569b0ae-b7ef-4f91-bcd5-0f55535d3564
> KUBERNETES_SERVICE_PORT_HTTPS=443
> KUBERNETES_PORT_443_TCP_PORT=443
> SPARK_HOME=/opt/spark
> SPARK_DRIVER_URL=spark://CoarseGrainedSchedulerspark-pi-1526555613156-driver-svc.default.svc:7078
> KUBERNETES_PORT_443_TCP=tcp://10.100.0.1:443
> SPARK_EXECUTOR_POD_IP=9.0.9.77
> TERM=xterm
> SPARK_EXECUTOR_ID=1
> SHLVL=1
> KUBERNETES_SERVICE_PORT=443
> SPARK_CONF_DIR=/opt/spark/conf
> PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/lib/jvm/java-1.8-openjdk/jre/bin:/usr/lib/jvm/java-1.8-openjdk/bin
> JAVA_ALPINE_VERSION=8.151.12-r0
> KUBERNETES_SERVICE_HOST=10.100.0.1
> **My_password=39528$vdg7Jb**
> _=/usr/bin/env
>
Author: Stavros Kontopoulos <stavros.kontopoulos@lightbend.com>
Closes #21317 from skonto/k8s-fix-env-secrets.
* [MINOR][YARN] Add YARN-specific credential providers in debug logging message
This PR adds a debugging log for YARN-specific credential providers which is loaded by service loader mechanism.
It took me a while to debug if it's actually loaded or not. I had to explicitly set the deprecated configuration and check if that's actually being loaded.
The change scope is manually tested. Logs are like:
```
Using the following builtin delegation token providers: hadoopfs, hive, hbase.
Using the following YARN-specific credential providers: yarn-test.
```
Author: hyukjinkwon <gurwls223@apache.org>
Closes #21466 from HyukjinKwon/minor-log.
Change-Id: I18e2fb8eeb3289b148f24c47bb3130a560a881cf
* [SPARK-24330][SQL] Refactor ExecuteWriteTask and Use `while` in writing files
## What changes were proposed in this pull request?
1. Refactor ExecuteWriteTask in FileFormatWriter to reduce common logic and improve readability.
After the change, callers only need to call `commit()` or `abort` at the end of task.
Also there is less code in `SingleDirectoryWriteTask` and `DynamicPartitionWriteTask`.
Definitions of related classes are moved to a new file, and `ExecuteWriteTask` is renamed to `FileFormatDataWriter`.
2. As per code style guide: https://github.com/databricks/scala-style-guide#traversal-and-zipwithindex , we avoid using `for` for looping in [FileFormatWriter](https://github.com/apache/spark/pull/21381/files#diff-3b69eb0963b68c65cfe8075f8a42e850L536) , or `foreach` in [WriteToDataSourceV2Exec](https://github.com/apache/spark/pull/21381/files#diff-6fbe10db766049a395bae2e785e9d56eL119).
In such critical code path, using `while` is good for performance.
## How was this patch tested?
Existing unit test.
I tried the microbenchmark in https://github.com/apache/spark/pull/21409
| Workload | Before changes(Best/Avg Time(ms)) | After changes(Best/Avg Time(ms)) |
| --- | --- | -- |
|Output Single Int Column| 2018 / 2043 | 2096 / 2236 |
|Output Single Double Column| 1978 / 2043 | 2013 / 2018 |
|Output Int and String Column| 6332 / 6706 | 6162 / 6298 |
|Output Partitions| 4458 / 5094 | 3792 / 4008 |
|Output Buckets| 5695 / 6102 | 5120 / 5154 |
Also a microbenchmark on my laptop for general comparison among while/foreach/for :
```
class Writer {
var sum = 0L
def write(l: Long): Unit = sum += l
}
def testWhile(iterator: Iterator[Long]): Long = {
val w = new Writer
while (iterator.hasNext) {
w.write(iterator.next())
}
w.sum
}
def testForeach(iterator: Iterator[Long]): Long = {
val w = new Writer
iterator.foreach(w.write)
w.sum
}
def testFor(iterator: Iterator[Long]): Long = {
val w = new Writer
for (x <- iterator) {
w.write(x)
}
w.sum
}
val data = 0L to 100000000L
val start = System.nanoTime
(0 to 10).foreach(_ => testWhile(data.iterator))
println("benchmark while: " + (System.nanoTime - start)/1000000)
val start2 = System.nanoTime
(0 to 10).foreach(_ => testForeach(data.iterator))
println("benchmark foreach: " + (System.nanoTime - start2)/1000000)
val start3 = System.nanoTime
(0 to 10).foreach(_ => testForeach(data.iterator))
println("benchmark for: " + (System.nanoTime - start3)/1000000)
```
Benchmark result:
`while`: 15401 ms
`foreach`: 43034 ms
`for`: 41279 ms
Author: Gengliang Wang <gengliang.wang@databricks.com>
Closes #21381 from gengliangwang/refactorExecuteWriteTask.
* [SPARK-24444][DOCS][PYTHON] Improve Pandas UDF docs to explain column assignment
## What changes were proposed in this pull request?
Added sections to pandas_udf docs, in the grouped map section, to indicate columns are assigned by position.
## How was this patch tested?
NA
Author: Bryan Cutler <cutlerb@gmail.com>
Closes #21471 from BryanCutler/arrow-doc-pandas_udf-column_by_pos-SPARK-21427.
* [SPARK-24326][MESOS] add support for local:// scheme for the app jar
## What changes were proposed in this pull request?
* Adds support for local:// scheme like in k8s case for image based deployments where the jar is already in the image. Affects cluster mode and the mesos dispatcher. Covers also file:// scheme. Keeps the default case where jar resolution happens on the host.
## How was this patch tested?
Dispatcher image with the patch, use it to start DC/OS Spark service:
skonto/spark-local-disp:test
Test image with my application jar located at the root folder:
skonto/spark-local:test
Dockerfile for that image.
From mesosphere/spark:2.3.0-2.2.1-2-hadoop-2.6
COPY spark-examples_2.11-2.2.1.jar /
WORKDIR /opt/spark/dist
Tests:
The following work as expected:
* local normal example
```
dcos spark run --submit-args="--conf spark.mesos.appJar.local.resolution.mode=container --conf spark.executor.memory=1g --conf spark.mesos.executor.docker.image=skonto/spark-local:test
--conf spark.executor.cores=2 --conf spark.cores.max=8
--class org.apache.spark.examples.SparkPi local:///spark-examples_2.11-2.2.1.jar"
```
* make sure the flag does not affect other uris
```
dcos spark run --submit-args="--conf spark.mesos.appJar.local.resolution.mode=container --conf spark.executor.memory=1g --conf spark.executor.cores=2 --conf spark.cores.max=8
--class org.apache.spark.examples.SparkPi https://s3-eu-west-1.amazonaws.com/fdp-stavros-test/spark-examples_2.11-2.1.1.jar"
```
* normal example no local
```
dcos spark run --submit-args="--conf spark.executor.memory=1g --conf spark.executor.cores=2 --conf spark.cores.max=8
--class org.apache.spark.examples.SparkPi https://s3-eu-west-1.amazonaws.com/fdp-stavros-test/spark-examples_2.11-2.1.1.jar"
```
The following fails
* uses local with no setting, default is host.
```
dcos spark run --submit-args="--conf spark.executor.memory=1g --conf spark.mesos.executor.docker.image=skonto/spark-local:test
--conf spark.executor.cores=2 --conf spark.cores.max=8
--class org.apache.spark.examples.SparkPi local:///spark-examples_2.11-2.2.1.jar"
```

Author: Stavros Kontopoulos <stavros.kontopoulos@lightbend.com>
Closes #21378 from skonto/local-upstream.
* [SPARK-23920][SQL] add array_remove to remove all elements that equal element from array
## What changes were proposed in this pull request?
add array_remove to remove all elements that equal element from array
## How was this patch tested?
add unit tests
Author: Huaxin Gao <huaxing@us.ibm.com>
Closes #21069 from huaxingao/spark-23920.
* [SPARK-24351][SS] offsetLog/commitLog purge thresholdBatchId should be computed with current committed epoch but not currentBatchId in CP mode
## What changes were proposed in this pull request?
Compute the thresholdBatchId to purge metadata based on current committed epoch instead of currentBatchId in CP mode to avoid cleaning all the committed metadata in some case as described in the jira [SPARK-24351](https://issues.apache.org/jira/browse/SPARK-24351).
## How was this patch tested?
Add new unit test.
Author: Huang Tengfei <tengfei.h@gmail.com>
Closes #21400 from ivoson/branch-cp-meta.
* Revert "[SPARK-24369][SQL] Correct handling for multiple distinct aggregations having the same argument set"
This reverts commit 1e46f92f956a00d04d47340489b6125d44dbd47b.
* [INFRA] Close stale PRs.
Closes #21444
* [SPARK-24340][CORE] Clean up non-shuffle disk block manager files following executor exits on a Standalone cluster
## What changes were proposed in this pull request?
Currently we only clean up the local directories on application removed. However, when executors die and restart repeatedly, many temp files are left untouched in the local directories, which is undesired behavior and could cause disk space used up gradually.
We can detect executor death in the Worker, and clean up the non-shuffle files (files not ended with ".index" or ".data") in the local directories, we should not touch the shuffle files since they are expected to be used by the external shuffle service.
Scope of this PR is limited to only implement the cleanup logic on a Standalone cluster, we defer to experts familiar with other cluster managers(YARN/Mesos/K8s) to determine whether it's worth to add similar support.
## How was this patch tested?
Add new test suite to cover.
Author: Xingbo Jiang <xingbo.jiang@databricks.com>
Closes #21390 from jiangxb1987/cleanupNonshuffleFiles.
* [SPARK-23668][K8S] Added missing config property in running-on-kubernetes.md
## What changes were proposed in this pull request?
PR https://github.com/apache/spark/pull/20811 introduced a new Spark configuration property `spark.kubernetes.container.image.pullSecrets` for specifying image pull secrets. However, the documentation wasn't updated accordingly. This PR adds the property introduced into running-on-kubernetes.md.
## How was this patch tested?
N/A.
foxish mccheah please help merge this. Thanks!
Author: Yinan Li <ynli@google.com>
Closes #21480 from liyinan926/master.
* [SPARK-24356][CORE] Duplicate strings in File.path managed by FileSegmentManagedBuffer
This patch eliminates duplicate strings that come from the 'path' field of
java.io.File objects created by FileSegmentManagedBuffer. That is, we want
to avoid the situation when multiple File instances for the same pathname
"foo/bar" are created, each with a separate copy of the "foo/bar" String
instance. In some scenarios such duplicate strings may waste a lot of memory
(~ 10% of the heap). To avoid that, we intern the pathname with
String.intern(), and before that we make sure that it's in a normalized
form (contains no "//", "///" etc.) Otherwise, the code in java.io.File
would normalize it later, creating a new "foo/bar" String copy.
Unfortunately, the normalization code that java.io.File uses internally
is in the package-private class java.io.FileSystem, so we cannot call it
here directly.
## What changes were proposed in this pull request?
Added code to ExternalShuffleBlockResolver.getFile(), that normalizes and then interns the pathname string before passing it to the File() constructor.
## How was this patch tested?
Added unit test
Author: Misha Dmitriev <misha@cloudera.com>
Closes #21456 from countmdm/misha/spark-24356.
* [SPARK-24455][CORE] fix typo in TaskSchedulerImpl comment
change runTasks to submitTasks in the TaskSchedulerImpl.scala 's comment
Author: xueyu <xueyu@yidian-inc.com>
Author: Xue Yu <278006819@qq.com>
Closes #21485 from xueyumusic/fixtypo1.
* [SPARK-24369][SQL] Correct handling for multiple distinct aggregations having the same argument set
## What changes were proposed in this pull request?
bring back https://github.com/apache/spark/pull/21443
This is a different approach: just change the check to count distinct columns with `toSet`
## How was this patch tested?
a new test to verify the planner behavior.
Author: Wenchen Fan <wenchen@databricks.com>
Author: Takeshi Yamamuro <yamamuro@apache.org>
Closes #21487 from cloud-fan/back.
* [SPARK-23786][SQL] Checking column names of csv headers
## What changes were proposed in this pull request?
Currently column names of headers in CSV files are not checked against provided schema of CSV data. It could cause errors like showed in the [SPARK-23786](https://issues.apache.org/jira/browse/SPARK-23786) and https://github.com/apache/spark/pull/20894#issuecomment-375957777. I introduced new CSV option - `enforceSchema`. If it is enabled (by default `true`), Spark forcibly applies provided or inferred schema to CSV files. In that case, CSV headers are ignored and not checked against the schema. If `enforceSchema` is set to `false`, additional checks can be performed. For example, if column in CSV header and in the schema have different ordering, the following exception is thrown:
```
java.lang.IllegalArgumentException: CSV file header does not contain the expected fields
Header: depth, temperature
Schema: temperature, depth
CSV file: marina.csv
```
## How was this patch tested?
The changes were tested by existing tests of CSVSuite and by 2 new tests.
Author: Maxim Gekk <maxim.gekk@databricks.com>
Author: Maxim Gekk <max.gekk@gmail.com>
Closes #20894 from MaxGekk/check-column-names.
* [SPARK-23903][SQL] Add support for date extract
## What changes were proposed in this pull request?
Add support for date `extract` function:
```sql
spark-sql> SELECT EXTRACT(YEAR FROM TIMESTAMP '2000-12-16 12:21:13');
2000
```
Supported field same as [Hive](https://github.com/apache/hive/blob/rel/release-2.3.3/ql/src/java/org/apache/hadoop/hive/ql/parse/IdentifiersParser.g#L308-L316): `YEAR`, `QUARTER`, `MONTH`, `WEEK`, `DAY`, `DAYOFWEEK`, `HOUR`, `MINUTE`, `SECOND`.
## How was this patch tested?
unit tests
Author: Yuming Wang <yumwang@ebay.com>
Closes #21479 from wangyum/SPARK-23903.
* [SPARK-21896][SQL] Fix StackOverflow caused by window functions inside aggregate functions
## What changes were proposed in this pull request?
This PR explicitly prohibits window functions inside aggregates. Currently, this will cause StackOverflow during analysis. See PR #19193 for previous discussion.
## How was this patch tested?
This PR comes with a dedicated unit test.
Author: aokolnychyi <anton.okolnychyi@sap.com>
Closes #21473 from aokolnychyi/fix-stackoverflow-window-funcs.
* [SPARK-24290][ML] add support for Array input for instrumentation.logNamedValue
## What changes were proposed in this pull request?
Extend instrumentation.logNamedValue to support Array input
change the logging for "clusterSizes" to new method
## How was this patch tested?
N/A
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: Lu WANG <lu.wang@databricks.com>
Closes #21347 from ludatabricks/SPARK-24290.
* [SPARK-24300][ML] change the way to set seed in ml.cluster.LDASuite.generateLDAData
## What changes were proposed in this pull request?
Using different RNG in all different partitions.
## How was this patch tested?
manually
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: Lu WANG <lu.wang@databricks.com>
Closes #21492 from ludatabricks/SPARK-24300.
* [SPARK-24215][PYSPARK] Implement _repr_html_ for dataframes in PySpark
## What changes were proposed in this pull request?
Implement `_repr_html_` for PySpark while in notebook and add config named "spark.sql.repl.eagerEval.enabled" to control this.
The dev list thread for context: http://apache-spark-developers-list.1001551.n3.nabble.com/eager-execution-and-debuggability-td23928.html
## How was this patch tested?
New ut in DataFrameSuite and manual test in jupyter. Some screenshot below.
**After:**

**Before:**

Author: Yuanjian Li <xyliyuanjian@gmail.com>
Closes #21370 from xuanyuanking/SPARK-24215.
* [SPARK-16451][REPL] Fail shell if SparkSession fails to start.
Currently, in spark-shell, if the session fails to start, the
user sees a bunch of unrelated errors which are caused by code
in the shell initialization that references the "spark" variable,
which does not exist in that case. Things like:
```
<console>:14: error: not found: value spark
import spark.sql
```
The user is also left with a non-working shell (unless they want
to just write non-Spark Scala or Python code, that is).
This change fails the whole shell session at the point where the
failure occurs, so that the last error message is the one with
the actual information about the failure.
For the python error handling, I moved the session initialization code
to session.py, so that traceback.print_exc() only shows the last error.
Otherwise, the printed exception would contain all previous exceptions
with a message "During handling of the above exception, another
exception occurred", making the actual error kinda hard to parse.
Tested with spark-shell, pyspark (with 2.7 and 3.5), by forcing an
error during SparkContext initialization.
Author: Marcelo Vanzin <vanzin@cloudera.com>
Closes #21368 from vanzin/SPARK-16451.
* [SPARK-15784] Add Power Iteration Clustering to spark.ml
## What changes were proposed in this pull request?
According to the discussion on JIRA. I rewrite the Power Iteration Clustering API in `spark.ml`.
## How was this patch tested?
Unit test.
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: WeichenXu <weichen.xu@databricks.com>
Closes #21493 from WeichenXu123/pic_api.
* [SPARK-24453][SS] Fix error recovering from the failure in a no-data batch
## What changes were proposed in this pull request?
The error occurs when we are recovering from a failure in a no-data batch (say X) that has been planned (i.e. written to offset log) but not executed (i.e. not written to commit log). Upon recovery the following sequence of events happen.
1. `MicroBatchExecution.populateStartOffsets` sets `currentBatchId` to X. Since there was no data in the batch, the `availableOffsets` is same as `committedOffsets`, so `isNewDataAvailable` is `false`.
2. When `MicroBatchExecution.constructNextBatch` is called, ideally it should immediately return true because the next batch has already been constructed. However, the check of whether the batch has been constructed was `if (isNewDataAvailable) return true`. Since the planned batch is a no-data batch, it escaped this check and proceeded to plan the same batch X *once again*.
The solution is to have an explicit flag that signifies whether a batch has already been constructed or not. `populateStartOffsets` is going to set the flag appropriately.
## How was this patch tested?
new unit test
Author: Tathagata Das <tathagata.das1565@gmail.com>
Closes #21491 from tdas/SPARK-24453.
* [SPARK-22384][SQL] Refine partition pruning when attribute is wrapped in Cast
## What changes were proposed in this pull request?
Sql below will get all partitions from metastore, which put much burden on metastore;
```
CREATE TABLE `partition_test`(`col` int) PARTITIONED BY (`pt` byte)
SELECT * FROM partition_test WHERE CAST(pt AS INT)=1
```
The reason is that the the analyzed attribute `dt` is wrapped in `Cast` and `HiveShim` fails to generate a proper partition filter.
This pr proposes to take `Cast` into consideration when generate partition filter.
## How was this patch tested?
Test added.
This pr proposes to use analyzed expressions in `HiveClientSuite`
Author: jinxing <jinxing6042@126.com>
Closes #19602 from jinxing64/SPARK-22384.
* [SPARK-24187][R][SQL] Add array_join function to SparkR
## What changes were proposed in this pull request?
This PR adds array_join function to SparkR
## How was this patch tested?
Add unit test in test_sparkSQL.R
Author: Huaxin Gao <huaxing@us.ibm.com>
Closes #21313 from huaxingao/spark-24187.
* [SPARK-23803][SQL] Support bucket pruning
## What changes were proposed in this pull request?
support bucket pruning when filtering on a single bucketed column on the following predicates -
EqualTo, EqualNullSafe, In, And/Or predicates
## How was this patch tested?
refactored unit tests to test the above.
based on gatorsmile work in https://github.com/apache/spark/commit/e3c75c6398b1241500343ff237e9bcf78b5396f9
Author: Asher Saban <asaban@palantir.com>
Author: asaban <asaban@palantir.com>
Closes #20915 from sabanas/filter-prune-buckets.
* [SPARK-24119][SQL] Add interpreted execution to SortPrefix expression
## What changes were proposed in this pull request?
Implemented eval in SortPrefix expression.
## How was this patch tested?
- ran existing sbt SQL tests
- added unit test
- ran existing Python SQL tests
- manual tests: disabling codegen -- patching code to disable beyond what spark.sql.codegen.wholeStage=false can do -- and running sbt SQL tests
Author: Bruce Robbins <bersprockets@gmail.com>
Closes #21231 from bersprockets/sortprefixeval.
* [SPARK-24224][ML-EXAMPLES] Java example code for Power Iteration Clustering in spark.ml
## What changes were proposed in this pull request?
Java example code for Power Iteration Clustering in spark.ml
## How was this patch tested?
Locally tested
Author: Shahid <shahidki31@gmail.com>
Closes #21283 from shahidki31/JavaPicExample.
* [SPARK-24191][ML] Scala Example code for Power Iteration Clustering
## What changes were proposed in this pull request?
Added example code for Power Iteration Clustering in Spark ML examples
Author: Shahid <shahidki31@gmail.com>
Closes #21248 from shahidki31/sparkCommit.
* [SPARK-24477][SPARK-24454][ML][PYTHON] Imports submodule in ml/__init__.py and add ImageSchema into __all__
## What changes were proposed in this pull request?
This PR attaches submodules to ml's `__init__.py` module.
Also, adds `ImageSchema` into `image.py` explicitly.
## How was this patch tested?
Before:
```python
>>> from pyspark import ml
>>> ml.image
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'module' object has no attribute 'image'
>>> ml.image.ImageSchema
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'module' object has no attribute 'image'
```
```python
>>> "image" in globals()
False
>>> from pyspark.ml import *
>>> "image" in globals()
False
>>> image
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'image' is not defined
```
After:
```python
>>> from pyspark import ml
>>> ml.image
<module 'pyspark.ml.image' from '/.../spark/python/pyspark/ml/image.pyc'>
>>> ml.image.ImageSchema
<pyspark.ml.image._ImageSchema object at 0x10d973b10>
```
```python
>>> "image" in globals()
False
>>> from pyspark.ml import *
>>> "image" in globals()
True
>>> image
<module 'pyspark.ml.image' from #'/.../spark/python/pyspark/ml/image.pyc'>
```
Author: hyukjinkwon <gurwls223@apache.org>
Closes #21483 from HyukjinKwon/SPARK-24454.
* [SPARK-23984][K8S] Initial Python Bindings for PySpark on K8s
## What changes were proposed in this pull request?
Introducing Python Bindings for PySpark.
- [x] Running PySpark Jobs
- [x] Increased Default Memory Overhead value
- [ ] Dependency Management for virtualenv/conda
## How was this patch tested?
This patch was tested with
- [x] Unit Tests
- [x] Integration tests with [this addition](https://github.com/apache-spark-on-k8s/spark-integration/pull/46)
```
KubernetesSuite:
- Run SparkPi with no resources
- Run SparkPi with a very long application name.
- Run SparkPi with a master URL without a scheme.
- Run SparkPi with an argument.
- Run SparkPi with custom labels, annotations, and environment variables.
- Run SparkPi with a test secret mounted into the driver and executor pods
- Run extraJVMOptions check on driver
- Run SparkRemoteFileTest using a remote data file
- Run PySpark on simple pi.py example
- Run PySpark with Python2 to test a pyfiles example
- Run PySpark with Python3 to test a pyfiles example
Run completed in 4 minutes, 28 seconds.
Total number of tests run: 11
Suites: completed 2, aborted 0
Tests: succeeded 11, failed 0, canceled 0, ignored 0, pending 0
All tests passed.
```
Author: Ilan Filonenko <if56@cornell.edu>
Author: Ilan Filonenko <ifilondz@gmail.com>
Closes #21092 from ifilonenko/master.
* [SPARK-17756][PYTHON][STREAMING] Workaround to avoid return type mismatch in PythonTransformFunction
## What changes were proposed in this pull request?
This PR proposes to wrap the transformed rdd within `TransformFunction`. `PythonTransformFunction` looks requiring to return `JavaRDD` in `_jrdd`.
https://github.com/apache/spark/blob/39e2bad6a866d27c3ca594d15e574a1da3ee84cc/python/pyspark/streaming/util.py#L67
https://github.com/apache/spark/blob/6ee28423ad1b2e6089b82af64a31d77d3552bb38/streaming/src/main/scala/org/apache/spark/streaming/api/python/PythonDStream.scala#L43
However, this could be `JavaPairRDD` by some APIs, for example, `zip` in PySpark's RDD API.
`_jrdd` could be checked as below:
```python
>>> rdd.zip(rdd)._jrdd.getClass().toString()
u'class org.apache.spark.api.java.JavaPairRDD'
```
So, here, I wrapped it with `map` so that it ensures returning `JavaRDD`.
```python
>>> rdd.zip(rdd).map(lambda x: x)._jrdd.getClass().toString()
u'class org.apache.spark.api.java.JavaRDD'
```
I tried to elaborate some failure cases as below:
```python
from pyspark.streaming import StreamingContext
ssc = StreamingContext(spark.sparkContext, 10)
ssc.queueStream([sc.range(10)]) \
.transform(lambda rdd: rdd.cartesian(rdd)) \
.pprint()
ssc.start()
```
```python
from pyspark.streaming import StreamingContext
ssc = StreamingContext(spark.sparkContext, 10)
ssc.queueStream([sc.range(10)]).foreachRDD(lambda rdd: rdd.cartesian(rdd))
ssc.start()
```
```python
from pyspark.streaming import StreamingContext
ssc = StreamingContext(spark.sparkContext, 10)
ssc.queueStream([sc.range(10)]).foreachRDD(lambda rdd: rdd.zip(rdd))
ssc.start()
```
```python
from pyspark.streaming import StreamingContext
ssc = StreamingContext(spark.sparkContext, 10)
ssc.queueStream([sc.range(10)]).foreachRDD(lambda rdd: rdd.zip(rdd).union(rdd.zip(rdd)))
ssc.start()
```
```python
from pyspark.streaming import StreamingContext
ssc = StreamingContext(spark.sparkContext, 10)
ssc.queueStream([sc.range(10)]).foreachRDD(lambda rdd: rdd.zip(rdd).coalesce(1))
ssc.start()
```
## How was this patch tested?
Unit tests were added in `python/pyspark/streaming/tests.py` and manually tested.
Author: hyukjinkwon <gurwls223@gmail.com>
Closes #19498 from HyukjinKwon/SPARK-17756.
* [SPARK-23010][K8S] Initial checkin of k8s integration tests.
These tests were developed in the https://github.com/apache-spark-on-k8s/spark-integration repo
by several contributors. This is a copy of the current state into the main apache spark repo.
The only changes from the current spark-integration repo state are:
* Move the files from the repo root into resource-managers/kubernetes/integration-tests
* Add a reference to these tests in the root README.md
* Fix a path reference in dev/dev-run-integration-tests.sh
* Add a TODO in include/util.sh
## What changes were proposed in this pull request?
Incorporation of Kubernetes integration tests.
## How was this patch tested?
This code has its own unit tests, but the main purpose is to provide the integration tests.
I tested this on my laptop by running dev/dev-run-integration-tests.sh --spark-tgz ~/spark-2.4.0-SNAPSHOT-bin--.tgz
The spark-integration tests have already been running for months in AMPLab, here is an example:
https://amplab.cs.berkeley.edu/jenkins/job/testing-k8s-scheduled-spark-integration-master/
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: Sean Suchter <sean-github@suchter.com>
Author: Sean Suchter <ssuchter@pepperdata.com>
Closes #20697 from ssuchter/ssuchter-k8s-integration-tests.
* [SPARK-24412][SQL] Adding docs about automagical type casting in `isin` and `isInCollection` APIs
## What changes were proposed in this pull request?
Update documentation for `isInCollection` API to clealy explain the "auto-casting" of elements if their types are different.
## How was this patch tested?
No-Op
Author: Thiruvasakan Paramasivan <thiru@apple.com>
Closes #21519 from trvskn/sql-doc-update.
* [SPARK-24468][SQL] Handle negative scale when adjusting precision for decimal operations
## What changes were proposed in this pull request?
In SPARK-22036 we introduced the possibility to allow precision loss in arithmetic operations (according to the SQL standard). The implementation was drawn from Hive's one, where Decimals with a negative scale are not allowed in the operations.
The PR handles the case when the scale is negative, removing the assertion that it is not.
## How was this patch tested?
added UTs
Author: Marco Gaido <marcogaido91@gmail.com>
Closes #21499 from mgaido91/SPARK-24468.
* [SPARK-23754][PYTHON][FOLLOWUP] Move UDF stop iteration wrapping from driver to executor
## What changes were proposed in this pull request?
SPARK-23754 was fixed in #21383 by changing the UDF code to wrap the user function, but this required a hack to save its argspec. This PR reverts this change and fixes the `StopIteration` bug in the worker
## How does this work?
The root of the problem is that when an user-supplied function raises a `StopIteration`, pyspark might stop processing data, if this function is used in a for-loop. The solution is to catch `StopIteration`s exceptions and re-raise them as `RuntimeError`s, so that the execution fails and the error is reported to the user. This is done using the `fail_on_stopiteration` wrapper, in different ways depending on where the function is used:
- In RDDs, the user function is wrapped in the driver, because this function is also called in the driver itself.
- In SQL UDFs, the function is wrapped in the worker, since all processing happens there. Moreover, the worker needs the signature of the user function, which is lost when wrapping it, but passing this signature to the worker requires a not so nice hack.
## How was this patch tested?
Same tests, plus tests for pandas UDFs
Author: edorigatti <emilio.dorigatti@gmail.com>
Closes #21467 from e-dorigatti/fix_udf_hack.
* [SPARK-19826][ML][PYTHON] add spark.ml Python API for PIC
## What changes were proposed in this pull request?
add spark.ml Python API for PIC
## How was this patch tested?
add doctest
Author: Huaxin Gao <huaxing@us.ibm.com>
Closes #21513 from huaxingao/spark--19826.
* [MINOR][CORE] Log committer class used by HadoopMapRedCommitProtocol
## What changes were proposed in this pull request?
When HadoopMapRedCommitProtocol is used (e.g., when using saveAsTextFile() or
saveAsHadoopFile() with RDDs), it's not easy to determine which output committer
class was used, so this PR simply logs the class that was used, similarly to what
is done in SQLHadoopMapReduceCommitProtocol.
## How was this patch tested?
Built Spark then manually inspected logging when calling saveAsTextFile():
```scala
scala> sc.setLogLevel("INFO")
scala> sc.textFile("README.md").saveAsTextFile("/tmp/out")
...
18/05/29 10:06:20 INFO HadoopMapRedCommitProtocol: Using output committer class org.apache.hadoop.mapred.FileOutputCommitter
```
Author: Jonathan Kelly <jonathak@amazon.com>
Closes #21452 from ejono/master.
* [SPARK-24520] Double braces in documentations
There are double braces in the markdown, which break the link.
## What changes were proposed in this pull request?
(Please fill in changes proposed in this fix)
## How was this patch tested?
(Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests)
(If this patch involves UI changes, please attach a screenshot; otherwise, remove this)
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: Fokko Driesprong <fokkodriesprong@godatadriven.com>
Closes #21528 from Fokko/patch-1.
* [SPARK-24134][DOCS] A missing full-stop in doc "Tuning Spark".
## What changes were proposed in this pull request?
In the document [Tuning Spark -> Determining Memory Consumption](https://spark.apache.org/docs/latest/tuning.html#determining-memory-consumption), a full stop was missing in the second paragraph.
It's `...use SizeEstimator’s estimate method This is useful for experimenting...`, while there is supposed to be a full stop before `This`.
Screenshot showing before change is attached below.
<img width="1033" alt="screen shot 2018-05-01 at 5 22 32 pm" src="https://user-images.githubusercontent.com/11539188/39468206-778e3d8a-4d64-11e8-8a92-38464952b54b.png">
## How was this patch tested?
This is a simple change in doc. Only one full stop was added in plain text.
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: Xiaodong <11539188+XD-DENG@users.noreply.github.com>
Closes #21205 from XD-DENG/patch-1.
* [SPARK-22144][SQL] ExchangeCoordinator combine the partitions of an 0 sized pre-shuffle to 0
## What changes were proposed in this pull request?
when the length of pre-shuffle's partitions is 0, the length of post-shuffle's partitions should be 0 instead of spark.sql.shuffle.partitions.
## How was this patch tested?
ExchangeCoordinator converted a pre-shuffle that partitions is 0 to a post-shuffle that partitions is 0 instead of one that partitions is spark.sql.shuffle.partitions.
Author: liutang123 <liutang123@yeah.net>
Closes #19364 from liutang123/SPARK-22144.
* [SPARK-23732][DOCS] Fix source links in generated scaladoc.
Apply the suggestion on the bug to fix source links. Tested with
the 2.3.1 release docs.
Author: Marcelo Vanzin <vanzin@cloudera.com>
Closes #21521 from vanzin/SPARK-23732.
* [SPARK-24502][SQL] flaky test: UnsafeRowSerializerSuite
## What changes were proposed in this pull request?
`UnsafeRowSerializerSuite` calls `UnsafeProjection.create` which accesses `SQLConf.get`, while the current active SparkSession may already be stopped, and we may hit exception like this
```
sbt.ForkMain$ForkError: java.lang.IllegalStateException: LiveListenerBus is stopped.
at org.apache.spark.scheduler.LiveListenerBus.addToQueue(LiveListenerBus.scala:97)
at org.apache.spark.scheduler.LiveListenerBus.addToStatusQueue(LiveListenerBus.scala:80)
at org.apache.spark.sql.internal.SharedState.<init>(SharedState.scala:93)
at org.apache.spark.sql.SparkSession$$anonfun$sharedState$1.apply(SparkSession.scala:120)
at org.apache.spark.sql.SparkSession$$anonfun$sharedState$1.apply(SparkSession.scala:120)
at scala.Option.getOrElse(Option.scala:121)
at org.apache.spark.sql.SparkSession.sharedState$lzycompute(SparkSession.scala:120)
at org.apache.spark.sql.SparkSession.sharedState(SparkSession.scala:119)
at org.apache.spark.sql.internal.BaseSessionStateBuilder.build(BaseSessionStateBuilder.scala:286)
at org.apache.spark.sql.test.TestSparkSession.sessionState$lzycompute(TestSQLContext.scala:42)
at org.apache.spark.sql.test.TestSparkSession.sessionState(TestSQLContext.scala:41)
at org.apache.spark.sql.SparkSession$$anonfun$1$$anonfun$apply$1.apply(SparkSession.scala:95)
at org.apache.spark.sql.SparkSession$$anonfun$1$$anonfun$apply$1.apply(SparkSession.scala:95)
at scala.Option.map(Option.scala:146)
at org.apache.spark.sql.SparkSession$$anonfun$1.apply(SparkSession.scala:95)
at org.apache.spark.sql.SparkSession$$anonfun$1.apply(SparkSession.scala:94)
at org.apache.spark.sql.internal.SQLConf$.get(SQLConf.scala:126)
at org.apache.spark.sql.catalyst.expressions.CodeGeneratorWithInterpretedFallback.createObject(CodeGeneratorWithInterpretedFallback.scala:54)
at org.apache.spark.sql.catalyst.expressions.UnsafeProjection$.create(Projection.scala:157)
at org.apache.spark.sql.catalyst.expressions.UnsafeProjection$.create(Projection.scala:150)
at org.apache.spark.sql.execution.UnsafeRowSerializerSuite.org$apache$spark$sql$execution$UnsafeRowSerializerSuite$$unsafeRowConverter(UnsafeRowSerializerSuite.scala:54)
at org.apache.spark.sql.execution.UnsafeRowSerializerSuite.org$apache$spark$sql$execution$UnsafeRowSerializerSuite$$toUnsafeRow(UnsafeRowSerializerSuite.scala:49)
at org.apache.spark.sql.execution.UnsafeRowSerializerSuite$$anonfun$2.apply(UnsafeRowSerializerSuite.scala:63)
at org.apache.spark.sql.execution.UnsafeRowSerializerSuite$$anonfun$2.apply(UnsafeRowSerializerSuite.scala:60)
...
```
## How was this patch tested?
N/A
Author: Wenchen Fan <wenchen@databricks.com>
Closes #21518 from cloud-fan/test.
* docs: fix typo
no => no[t]
## What changes were proposed in this pull request?
Fixing a typo.
## How was this patch tested?
Visual check of the docs.
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: Tom Saleeba <tom.saleeba@gmail.com>
Closes #21496 from tomsaleeba/patch-1.
* [SPARK-15064][ML] Locale support in StopWordsRemover
## What changes were proposed in this pull request?
Add locale support for `StopWordsRemover`.
## How was this patch tested?
[Scala|Python] unit tests.
Author: Lee Dongjin <dongjin@apache.org>
Closes #21501 from dongjinleekr/feature/SPARK-15064.
* [SPARK-24531][TESTS] Remove version 2.2.0 from testing versions in HiveExternalCatalogVersionsSuite
## What changes were proposed in this pull request?
Removing version 2.2.0 from testing versions in HiveExternalCatalogVersionsSuite as it is not present anymore in the mirrors and this is blocking all the open PRs.
## How was this patch tested?
running UTs
Author: Marco Gaido <marcogaido91@gmail.com>
Closes #21540 from mgaido91/SPARK-24531.
* [SPARK-24416] Fix configuration specification for killBlacklisted executors
## What changes were proposed in this pull request?
spark.blacklist.killBlacklistedExecutors is defined as
(Experimental) If set to "true", allow Spark to automatically kill, and attempt to re-create, executors when they are blacklisted. Note that, when an entire node is added to the blacklist, all of the executors on that node will be killed.
I presume the killing of blacklisted executors only happens after the stage completes successfully and all tasks have completed or on fetch failures (updateBlacklistForFetchFailure/updateBlacklistForSuccessfulTaskSet). It is confusing because the definition states that the executor will be attempted to be recreated as soon as it is blacklisted. This is not true while the stage is in progress and an executor is blacklisted, it will not attempt to cleanup until the stage finishes.
Author: Sanket Chintapalli <schintap@yahoo-inc.com>
Closes #21475 from redsanket/SPARK-24416.
* [SPARK-23931][SQL] Adds arrays_zip function to sparksql
Signed-off-by: DylanGuedes <djmgguedesgmail.com>
## What changes were proposed in this pull request?
Addition of arrays_zip function to spark sql functions.
## How was this patch tested?
(Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests)
Unit tests that checks if the results are correct.
Author: DylanGuedes <djmgguedes@gmail.com>
Closes #21045 from DylanGuedes/SPARK-23931.
* [SPARK-24216][SQL] Spark TypedAggregateExpression uses getSimpleName that is not safe in scala
## What changes were proposed in this pull request?
When user create a aggregator object in scala and pass the aggregator to Spark Dataset's agg() method, Spark's will initialize TypedAggregateExpression with the nodeName field as aggregator.getClass.getSimpleName. However, getSimpleName is not safe in scala environment, depending on how user creates the aggregator object. For example, if the aggregator class full qualified name is "com.my.company.MyUtils$myAgg$2$", the getSimpleName will throw java.lang.InternalError "Malformed class name". This has been reported in scalatest https://github.com/scalatest/scalatest/pull/1044 and discussed in many scala upstream jiras such as SI-8110, SI-5425.
To fix this issue, we follow the solution in https://github.com/scalatest/scalatest/pull/1044 to add safer version of getSimpleName as a util method, and TypedAggregateExpression will invoke this util method rather than getClass.getSimpleName.
## How was this patch tested?
added unit test
Author: Fangshi Li <fli@linkedin.com>
Closes #21276 from fangshil/SPARK-24216.
* [SPARK-23933][SQL] Add map_from_arrays function
## What changes were proposed in this pull request?
The PR adds the SQL function `map_from_arrays`. The behavior of the function is based on Presto's `map`. Since SparkSQL already had a `map` function, we prepared the different name for this behavior.
This function returns returns a map from a pair of arrays for keys and values.
## How was this patch tested?
Added UTs
Author: Kazuaki Ishizaki <ishizaki@jp.ibm.com>
Closes #21258 from kiszk/SPARK-23933.
* [SPARK-23010][BUILD][FOLLOWUP] Fix java checkstyle failure of kubernetes-integration-tests
## What changes were proposed in this pull request?
Fix java checkstyle failure of kubernetes-integration-tests
## How was this patch tested?
Checked manually on my local environment.
Author: Xingbo Jiang <xingbo.jiang@databricks.com>
Closes #21545 from jiangxb1987/k8s-checkstyle.
* [SPARK-24506][UI] Add UI filters to tabs added after binding
## What changes were proposed in this pull request?
Currently, `spark.ui.filters` are not applied to the handlers added after binding the server. This means that every page which is added after starting the UI will not have the filters configured on it. This can allow unauthorized access to the pages.
The PR adds the filters also to the handlers added after the UI starts.
## How was this patch tested?
manual tests (without the patch, starting the thriftserver with `--conf spark.ui.filters=org.apache.hadoop.security.authentication.server.AuthenticationFilter --conf spark.org.apache.hadoop.security.authentication.server.AuthenticationFilter.params="type=simple"` you can access `http://localhost:4040/sqlserver`; with the patch, 401 is the response as for the other pages).
Author: Marco Gaido <marcogaido91@gmail.com>
Closes #21523 from mgaido91/SPARK-24506.
* [SPARK-22239][SQL][PYTHON] Enable grouped aggregate pandas UDFs as window functions with unbounded window frames
## What changes were proposed in this pull request?
This PR enables using a grouped aggregate pandas UDFs as window functions. The semantics is the same as using SQL aggregation function as window functions.
```
>>> from pyspark.sql.functions import pandas_udf, PandasUDFType
>>> from pyspark.sql import Window
>>> df = spark.createDataFrame(
... [(1, 1.0), (1, 2.0), (2, 3.0), (2, 5.0), (2, 10.0)],
... ("id", "v"))
>>> pandas_udf("double", PandasUDFType.GROUPED_AGG)
... def mean_udf(v):
... return v.mean()
>>> w = Window.partitionBy('id')
>>> df.withColumn('mean_v', mean_udf(…
What changes were proposed in this pull request?
This PR is to add eager execution into the
__repr__and_repr_html_of the DataFrame APIs in PySpark. When eager evaluation is enabled,_repr_html_returns a rich HTML version of the top-K rows of the DataFrame output. If_repr_html_is not called by REPL,_repr_will return the plain text of the top-K rows.This PR adds three new external SQL confs for controlling the behavior of eager evaluation:
spark.sql.repl.eagerEval.enabled: Enables eager evaluation or not. When true, the top K rows of Dataset will be displayed if and only if the REPL supports the eager evaluation. Currently, the eager evaluation is only supported in PySpark. For the notebooks like Jupyter, the HTML table (generated by_repr_html_) will be returned. For plain Python REPL, the returned outputs are formatted like dataframe.show().spark.sql.repl.eagerEval.maxNumRows: The max number of rows that are returned by eager evaluation. This only takes effect whenspark.sql.repl.eagerEval.enabledis set to true.spark.sql.repl.eagerEval.truncate: The max number of characters for each cell that is returned by eager evaluation. This only takes effect whenspark.sql.repl.eagerEval.enabledis set to true.How was this patch tested?
New ut in DataFrameSuite and manual test in jupyter. Some screenshot below.
After:

Before:
