[SPARK-24870][SQL]Cache can't work normally if there are case letters in SQL #21823
Conversation
|
do you know why it's happening? It's super weird that |
|
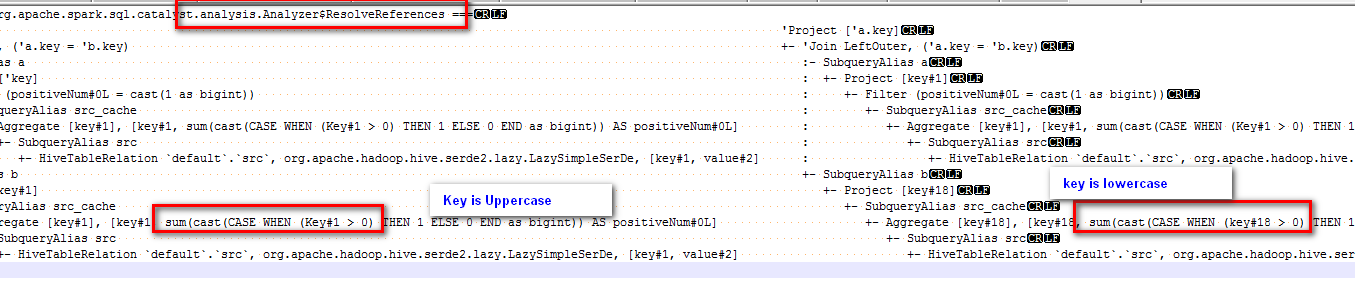
@cloud-fan Because the word 'Key' in the sql of cache "select key, sum(case when Key > 0 then 1 else 0 end) as positiveNum" is Uppercase, and the field positiveNum is used in sql 'select key from src_cache where positiveNum = 1 '; |
|
Test build #93312 has finished for PR 21823 at commit
|
shouldn't we always do it? |
|
@cloud-fan Cast 'Key' to lower case is done by rule of ResolveReferences: |
|
@cloud-fan |
|
can we fix this in |
|
@cloud-fan fix this in dedupRight is Ok, but maybe there are other operations like dedupRight to change the case of the word. |
|
@cloud-fan why not fix this in doCanonicalize? I think it is better to fix it in doCanonicalize, but I'm not very sure. |
| // normalize the epxrId too. | ||
| id += 1 | ||
| ar.withExprId(ExprId(id)).canonicalized | ||
| ar.withExprId(ExprId(id)).withName(ar.name.toLowerCase(Locale.ROOT)).canonicalized |
There was a problem hiding this comment.
shall we just erase the attribute name like alias?
There was a problem hiding this comment.
I think it is Ok, and it erase the attribute name in spark version 2.0.2
| val ordinal = input.indexOf(ar.exprId) | ||
| if (ordinal == -1) { | ||
| ar | ||
| ar.withName("") |
There was a problem hiding this comment.
let's leave it. We don't even normalize the exprId here.
| // normalize the epxrId too. | ||
| id += 1 | ||
| ar.withExprId(ExprId(id)).canonicalized | ||
| ar.withExprId(ExprId(id)).withName("").canonicalized |
There was a problem hiding this comment.
oh wait. I think we've already erased the name, in Expression#canonicalized
| ar.withName("") | ||
| } else { | ||
| ar.withExprId(ExprId(ordinal)) | ||
| ar.withExprId(ExprId(ordinal)).withName("") |
There was a problem hiding this comment.
I think we just need to add a .canonicalized at the end.
| assert(!range.where(arrays1).sameResult(range.where(arrays3))) | ||
| } | ||
|
|
||
| test("Canonicalized result is not case-insensitive") { |
There was a problem hiding this comment.
let's move it to SameResultSuite, also let's pick a simpler test, like using a Project with one columns instead of Aggregate.
There was a problem hiding this comment.
Ok,modified,thanks.
|
Test build #93337 has finished for PR 21823 at commit
|
| test("Canonicalized result is not case-insensitive") { | ||
| val a = AttributeReference("A", IntegerType)() | ||
| val b = AttributeReference("B", IntegerType)() | ||
| val planUppercase = Project(Seq(a, b), LocalRelation(a)) |
There was a problem hiding this comment.
we should create valid plans... Project(Seq(a), LocalRelation(a, b))
|
LGTM |
|
Test build #93333 has finished for PR 21823 at commit
|
|
Test build #93332 has finished for PR 21823 at commit
|
|
Test build #93338 has finished for PR 21823 at commit
|
|
Test build #93376 has finished for PR 21823 at commit
|
|
Can we merge it to master? @cloud-fan @gatorsmile |
| assert(df3.queryExecution.executedPlan.sameResult(df4.queryExecution.executedPlan)) | ||
| } | ||
|
|
||
| test("Canonicalized result is not case-insensitive") { |
There was a problem hiding this comment.
Canonicalized result is not case-insensitive -> Canonicalized result is case-insensitive
|
Test build #93467 has finished for PR 21823 at commit
|
|
Thanks! Merged to master. |
…s in SQL
Modified the canonicalized to not case-insensitive.
Before the PR, cache can't work normally if there are case letters in SQL,
for example:
sql("CREATE TABLE IF NOT EXISTS src (key INT, value STRING) USING hive")
sql("select key, sum(case when Key > 0 then 1 else 0 end) as positiveNum " +
"from src group by key").cache().createOrReplaceTempView("src_cache")
sql(
s"""select a.key
from
(select key from src_cache where positiveNum = 1)a
left join
(select key from src_cache )b
on a.key=b.key
""").explain
The physical plan of the sql is:

The subquery "select key from src_cache where positiveNum = 1" on the left of join can use the cache data, but the subquery "select key from src_cache" on the right of join cannot use the cache data.
new added test
Author: 10129659 <chen.yanshan@zte.com.cn>
Closes apache#21823 from eatoncys/canonicalized.
(cherry picked from commit 13a67b0)
RB=1413356
BUG=LIHADOOP-40154
G=superfriends-reviewers
R=fli,mshen,yezhou,edlu
A=edlu
{kind=link}
What changes were proposed in this pull request?
Modified the canonicalized to not case-insensitive.
Before the PR, cache can't work normally if there are case letters in SQL,
for example:
sql("CREATE TABLE IF NOT EXISTS src (key INT, value STRING) USING hive")
The physical plan of the sql is:

The subquery "select key from src_cache where positiveNum = 1" on the left of join can use the cache data, but the subquery "select key from src_cache" on the right of join cannot use the cache data.
How was this patch tested?
new added test