[SPARK-25521][SQL]Job id showing null in the logs when insert into command Job is finished. #22572
Conversation
|
cc @cloud-fan @srowen |
|
Is the value logged here always null? |
even initially i thought the same, not sure whether mapreduce.job.id makes sense here, but i think we shall not display null . Deleting the log will be the easiest option but just curious to know why the author is trying to log a map reduce job id . |
|
cc @gatorsmile |
There was a problem hiding this comment.
we should log something here, but mapreduce.job.id is not useful, how about description.uuid?
There was a problem hiding this comment.
SparkHadoopWriter needs a similar change, then, BTW
There was a problem hiding this comment.
Thanks for the suggestions!! I will update this PR.
@cloud-fan Yes, i think displaying description.uuid makes more sense as the user can get to know about their particular write job status.
I will also update the message with Write Job instead of Job, Hope thats fine.
|
@srowen @cloud-fan val hconf=spark.sparkContext.hadoopConfiguration hconf.set("mapreduce.output.fileoutputformat.outputdir","D:/data/test") scala> rdd.saveAsNewAPIHadoopDataset(hconf)
|

|
When i digged the code i could see in SparkHadoopWriter, while creating job context itself job id is been intialized. Let me know for any suggestions.
|
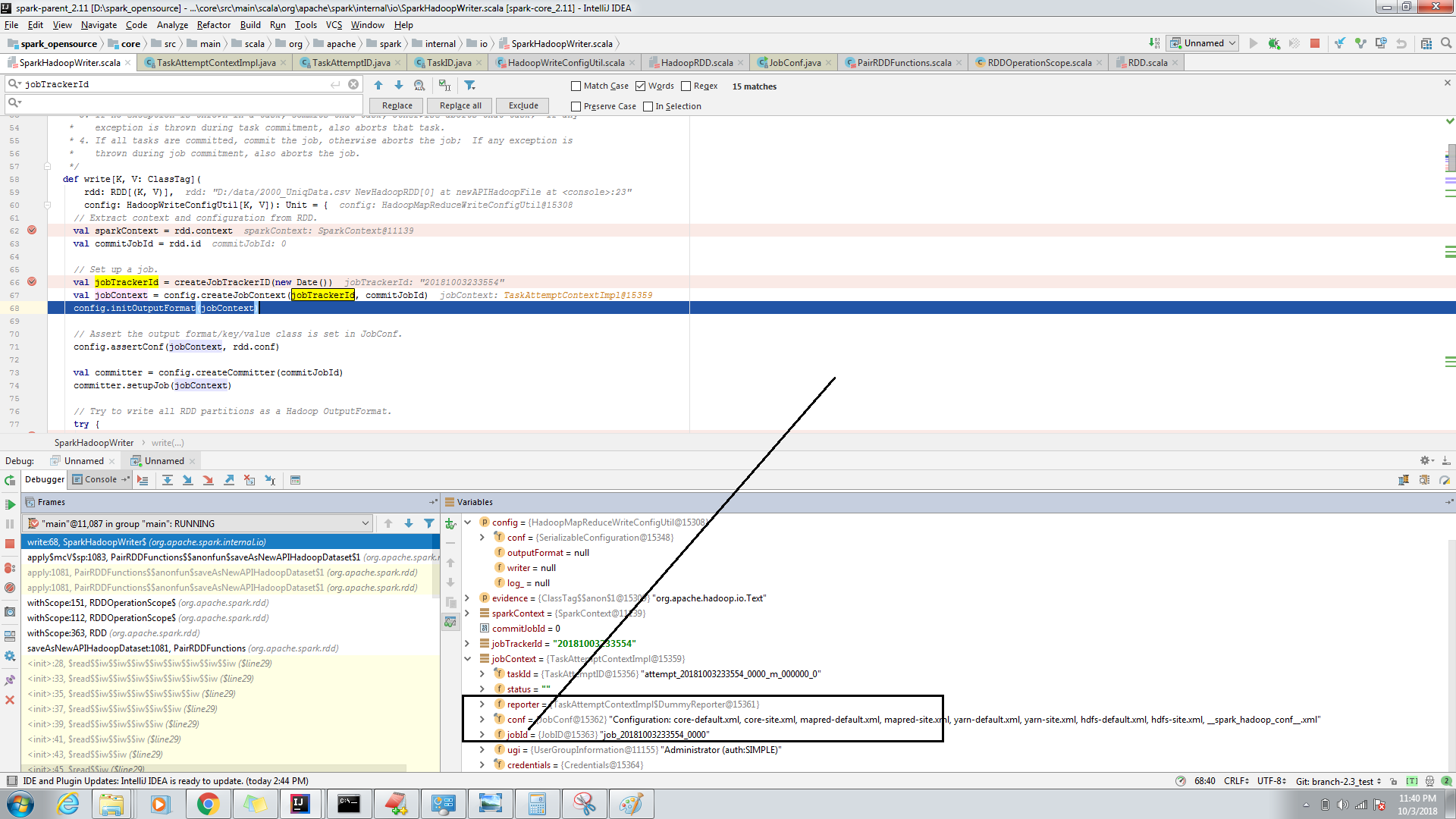
|
Can we update the PR to use |
23a1b06 to
56c5ff5
Compare
…mmand Job is finished. ## What changes were proposed in this pull request? As part of insert command in FileFormatWriter, a job context is created for handling the write operation , While initializing the job context setupJob() API in HadoopMapReduceCommitProtocol sets the jobid in the Jobcontext configuration, Since we are directly getting the jobId from the map reduce JobContext the job id will come as null in the logs. As a solution we shall get the jobID from the configuration of the map reduce Jobcontext ## How was this patch tested? Manually, verified the logs after the changes.
Updated FileFormatWriter with description.uuid, attaching the verification snapshot . |
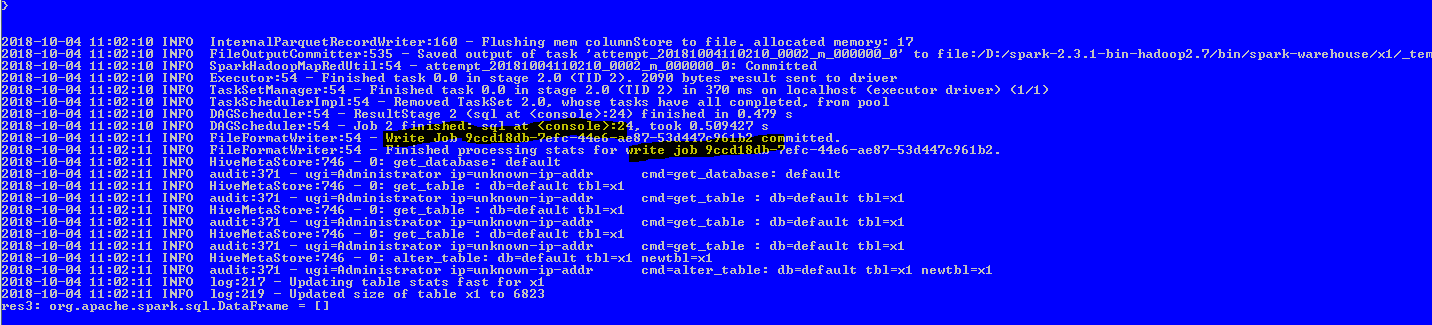
Let me know whether we shall update SparkHadoopWriter.scala flow as in this flow currently the jobid is been displayed properly , to display the job description uuid i need to explore as this flow doesnt holds any WriteJobDescription instance. |
|
ok to test |
|
Test build #96925 has finished for PR 22572 at commit
|
|
retest this please |
|
Test build #96938 has finished for PR 22572 at commit
|
|
thanks, merging to master/2.4! |
…ommand Job is finished. ## What changes were proposed in this pull request? ``As part of insert command in FileFormatWriter, a job context is created for handling the write operation , While initializing the job context using setupJob() API in HadoopMapReduceCommitProtocol , we set the jobid in the Jobcontext configuration.In FileFormatWriter since we are directly getting the jobId from the map reduce JobContext the job id will come as null while adding the log. As a solution we shall get the jobID from the configuration of the map reduce Jobcontext.`` ## How was this patch tested? Manually, verified the logs after the changes.  Closes #22572 from sujith71955/master_log_issue. Authored-by: s71955 <sujithchacko.2010@gmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit 4597007) Signed-off-by: Wenchen Fan <wenchen@databricks.com>
{kind=link}
…ommand Job is finished. ## What changes were proposed in this pull request? ``As part of insert command in FileFormatWriter, a job context is created for handling the write operation , While initializing the job context using setupJob() API in HadoopMapReduceCommitProtocol , we set the jobid in the Jobcontext configuration.In FileFormatWriter since we are directly getting the jobId from the map reduce JobContext the job id will come as null while adding the log. As a solution we shall get the jobID from the configuration of the map reduce Jobcontext.`` ## How was this patch tested? Manually, verified the logs after the changes.  Closes apache#22572 from sujith71955/master_log_issue. Authored-by: s71955 <sujithchacko.2010@gmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com>
…to command Job is finished. apache#22572 As part of insert command in FileFormatWriter, a job context is created for handling the write operation , While initializing the job context using setupJob() API in HadoopMapReduceCommitProtocol , we set the jobid in the Jobcontext configuration.In FileFormatWriter since we are directly getting the jobId from the map reduce JobContext the job id will come as null while adding the log. As a solution we shall get the jobID from the configuration of the map reduce Jobcontext.
What changes were proposed in this pull request?
As part of insert command in FileFormatWriter, a job context is created for handling the write operation , While initializing the job context using setupJob() API in HadoopMapReduceCommitProtocol , we set the jobid in the Jobcontext configuration.In FileFormatWriter since we are directly getting the jobId from the map reduce JobContext the job id will come as null while adding the log. As a solution we shall get the jobID from the configuration of the map reduce Jobcontext.How was this patch tested?
Manually, verified the logs after the changes.