[Streaming][DOC] Fix typo & formatting for JavaDoc #22593
Conversation
|
ok to test |
|
Test build #96805 has finished for PR 22593 at commit
|
| * - `OutputMode.Update()`: only the rows that were updated in the streaming DataFrame/Dataset | ||
| * <ul> | ||
| * <li> `OutputMode.Append()`: only the new rows in the streaming DataFrame/Dataset will be | ||
| * written to the sink.</li> |
There was a problem hiding this comment.
I would just format this similarly with
spark/sql/core/src/main/scala/org/apache/spark/sql/DataFrameReader.scala
Lines 338 to 366 in e06da95
|
ping @niofire |
|
This is fine, although unfortunately there are lots of instances of this type of formatting error. We don't need to fix them all, but what about looking for similar instances in |
|
Ping @niofire to update or close |
|
@srowen Guessing you're referring to some other files? Could you link? |
|
Test build #97204 has finished for PR 22593 at commit
|
|
Have a look at
That already seems fine. Are you looking at javadoc for these classes? scaladoc looks OK. |

|
From https://spark.apache.org/docs/2.3.2/api/java/org/apache/spark/sql/streaming/DataStreamWriter.html |
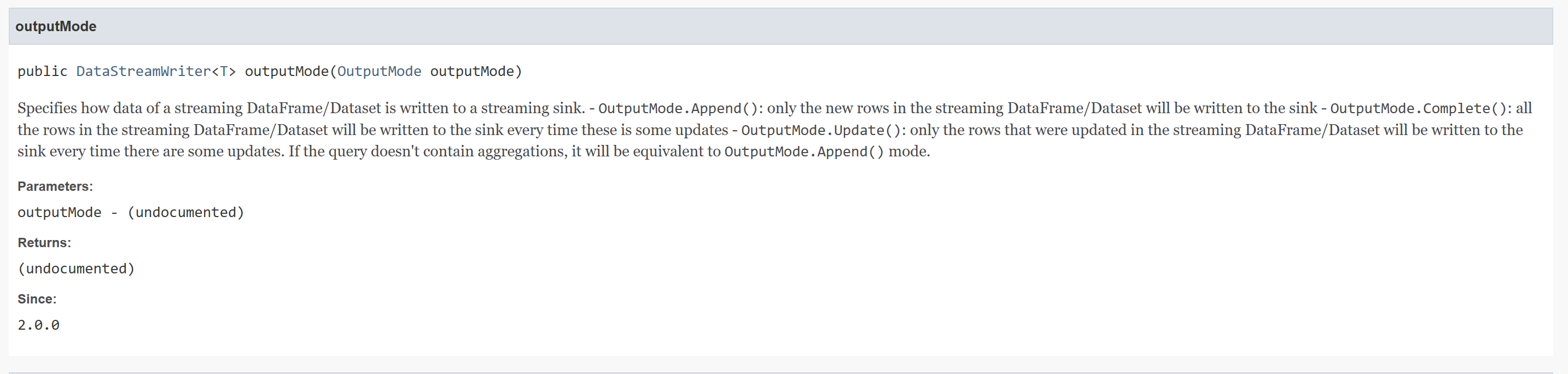
|
Although it's the Scala API, it's callable from Java just as well. There's no Java-specific API here. So, yeah, actually it makes sense to have javadoc and scaladoc for this. And I think there are probably many markdown-like things that work in scaladoc not in javadoc. While you're welcome to fix all of it ideally, it may be way too much. OK, I'd say go ahead but at least fix all the instances of bullet lists in the .sql package. It's easy enough to search for something like |
|
Test build #97205 has finished for PR 22593 at commit
|
|
Seems like this wasn't able to build due to a transient error with CI |
|
org.apache.spark.sql.hive.client.HiveClientSuites.(It is not a test it is a sbt.testing.SuiteSelector) |
|
retest this please |
|
Test build #97268 has finished for PR 22593 at commit
|
|
Hm, that's a weird error. Big javadoc failures from unrelated classes. This looks like errors you get when you run javadoc on translated Scala classes. No idea why it's just popped up. Let me run again. |
|
Test build #4371 has finished for PR 22593 at commit
|
|
Huh, I'm really confused why this would fail, or at least, start failing right now. We use these HTML tags elsewhere. You could try updating the unidoc plugin version, but I think it's a genjavadoc issue if anything. But we're on the latest genjavadoc. Really confused! |
|
Is this happening for other PRs as well? |
|
Usually no.. i only saw this once in Tdas's PR before - at that time the order of methods in the change was related |
|
|
||
| /** | ||
| * <ul> | ||
| * Specifies the behavior when data or table already exists. Options include: |
There was a problem hiding this comment.
This one looks wrongly formatted btw. Looks ul should be below of this line
|
Test build #97265 has finished for PR 22593 at commit
|
|
Also, let's mention this PR targets to fix javadoc in the PR description and/or title. |
|
Test build #97311 has finished for PR 22593 at commit
|
|
Merged to master/2.4 |
## What changes were proposed in this pull request?
- Fixed typo for function outputMode
- OutputMode.Complete(), changed `these is some updates` to `there are some updates`
- Replaced hyphenized list by HTML unordered list tags in comments to fix the Javadoc documentation.
Current render from most recent [Spark API Docs](https://spark.apache.org/docs/2.3.1/api/java/org/apache/spark/sql/streaming/DataStreamWriter.html):
#### outputMode(OutputMode) - List formatted as a prose.

#### outputMode(String) - List formatted as a prose.

#### partitionBy(String*) - List formatted as a prose.

## How was this patch tested?
This PR contains a document patch ergo no functional testing is required.
Closes #22593 from niofire/fix-typo-datastreamwriter.
Authored-by: Mathieu St-Louis <mastloui@microsoft.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
(cherry picked from commit 4e141a4)
Signed-off-by: Sean Owen <sean.owen@databricks.com>
{kind=link}
{kind=link}
{kind=link}
## What changes were proposed in this pull request?
- Fixed typo for function outputMode
- OutputMode.Complete(), changed `these is some updates` to `there are some updates`
- Replaced hyphenized list by HTML unordered list tags in comments to fix the Javadoc documentation.
Current render from most recent [Spark API Docs](https://spark.apache.org/docs/2.3.1/api/java/org/apache/spark/sql/streaming/DataStreamWriter.html):
#### outputMode(OutputMode) - List formatted as a prose.

#### outputMode(String) - List formatted as a prose.

#### partitionBy(String*) - List formatted as a prose.

## How was this patch tested?
This PR contains a document patch ergo no functional testing is required.
Closes apache#22593 from niofire/fix-typo-datastreamwriter.
Authored-by: Mathieu St-Louis <mastloui@microsoft.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
What changes were proposed in this pull request?
- OutputMode.Complete(), changed
these is some updatestothere are some updatesCurrent render from most recent Spark API Docs:
outputMode(OutputMode) - List formatted as a prose.
outputMode(String) - List formatted as a prose.
partitionBy(String*) - List formatted as a prose.
How was this patch tested?
This PR contains a document patch ergo no functional testing is required.