[SPARK-5364] [SQL] HiveQL transform doesn't support the non output clause #4158
Conversation
|
Test build #25959 has started for PR 4158 at commit
|
|
Hi @chenghao-intel, I already did this and support for custom field delimiter and SerDe in PR #4014. |
|
Test build #25959 has finished for PR 4158 at commit
|
|
Test PASSed. |
|
Thank you @viirya . This is just a quick fix in my use case. Hope it merge soon. And I will give some comment in your PR. |
|
Test build #25996 has started for PR 4158 at commit
|
|
Test build #25996 has finished for PR 4158 at commit
|
|
Test PASSed. |
There was a problem hiding this comment.
According to Hive manual, there should be only two outputs key and value when no output schema is defined. So I am not sure if it is a bug because it is explictly described in the manual. I suppose that it is a well-known and expected behavior?
There was a problem hiding this comment.
Thanks for notice that. I think this's probably a bug in Hive.
I did the queries in Hive CLI:
set hive.cli.print.header=true;
select transform(key + 1, key - 1, key) using '/bin/cat' from src limit 4;
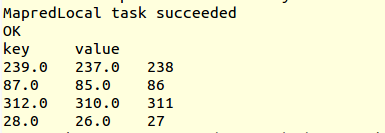
create table test2 as select transform(key + 1, key - 1, key) using '/bin/cat' from src limit 4;
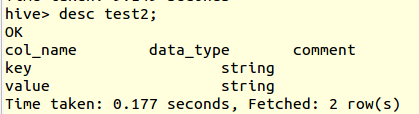
And print the result of the table test2:
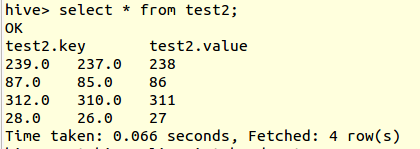
You will see, it's not the expected result, of key and value, that's why I added the default field name for more than 2 columns.
There was a problem hiding this comment.
I think it is expected results as the Hive manual describes about 'Schema-less Map-reduce Scripts
' in transform:
If there is no AS clause after USING my_script, Hive assumes that the output of the script contains 2 parts: key which is before the first tab, and value which is the rest after the first tab.
So in your results, value column gets all query outputs after the first tab. The results of table test2 is just the alignment problem caused by tabs. It should follow the same rule too.
There was a problem hiding this comment.
OK, I see. thanks for the explanation. I will update that.
|
@chenghao-intel overall it looks good for me except for small comments. |
|
Test build #26069 has started for PR 4158 at commit
|
|
Test build #26069 has finished for PR 4158 at commit
|
|
Test PASSed. |
|
Closing this since #4014 has been merged. |
This is a quick fix for query (in HiveContext) like:
Ideally, we need to refactor the
ScriptTransformation, which should support the custom SerDe for reader & writer. Will do that in the follow up.