-
Notifications
You must be signed in to change notification settings - Fork 14k
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
chore(docs-v2): moving more markdown content to new documentation site (
#17736) * chore: move markdown content and images for docs installation directory to docs-v2 * chore: move docs miscellaneous directory content to docs-v2 * chore(docs-v2): move over connecting to databases content and rename some files to .mdx Co-authored-by: Corbin Robb <corbin@Corbins-MacBook-Pro.local>
- Loading branch information
1 parent
1b2856b
commit 42e5ad2
Showing
74 changed files
with
4,209 additions
and
2 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,4 @@ | ||
| { | ||
| "label": "Connecting to Databases", | ||
| "position": 3 | ||
| } |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,16 @@ | ||
| --- | ||
| title: Ascend.io | ||
| hide_title: true | ||
| sidebar_position: 10 | ||
| version: 1 | ||
| --- | ||
|
|
||
| ## Ascend.io | ||
|
|
||
| The recommended connector library to Ascend.io is [impyla](https://github.com/cloudera/impyla). | ||
|
|
||
| The expected connection string is formatted as follows: | ||
|
|
||
| ``` | ||
| ascend://{username}:{password}@{hostname}:{port}/{database}?auth_mechanism=PLAIN;use_ssl=true | ||
| ``` |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,34 @@ | ||
| --- | ||
| title: Amazon Athena | ||
| hide_title: true | ||
| sidebar_position: 4 | ||
| version: 1 | ||
| --- | ||
|
|
||
| ## AWS Athena | ||
|
|
||
| ### PyAthenaJDBC | ||
|
|
||
| [PyAthenaJDBC](https://pypi.org/project/PyAthenaJDBC/) is a Python DB 2.0 compliant wrapper for the | ||
| [Amazon Athena JDBC driver](https://docs.aws.amazon.com/athena/latest/ug/connect-with-jdbc.html). | ||
|
|
||
| The connection string for Amazon Athena is as follows: | ||
|
|
||
| ``` | ||
| awsathena+jdbc://{aws_access_key_id}:{aws_secret_access_key}@athena.{region_name}.amazonaws.com/{schema_name}?s3_staging_dir={s3_staging_dir}&... | ||
| ``` | ||
|
|
||
| Note that you'll need to escape & encode when forming the connection string like so: | ||
|
|
||
| ``` | ||
| s3://... -> s3%3A//... | ||
| ``` | ||
|
|
||
| ### PyAthena | ||
|
|
||
| You can also use [PyAthena library](https://pypi.org/project/PyAthena/) (no Java required) with the | ||
| following connection string: | ||
|
|
||
| ``` | ||
| awsathena+rest://{aws_access_key_id}:{aws_secret_access_key}@athena.{region_name}.amazonaws.com/{schema_name}?s3_staging_dir={s3_staging_dir}&... | ||
| ``` |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,89 @@ | ||
| --- | ||
| title: Google BigQuery | ||
| hide_title: true | ||
| sidebar_position: 20 | ||
| version: 1 | ||
| --- | ||
|
|
||
| ## Google BigQuery | ||
|
|
||
| The recommended connector library for BigQuery is | ||
| [pybigquery](https://github.com/mxmzdlv/pybigquery). | ||
|
|
||
| ### Install BigQuery Driver | ||
|
|
||
| Follow the steps [here](/docs/databases/dockeradddrivers) about how to | ||
| install new database drivers when setting up Superset locally via docker-compose. | ||
|
|
||
| ``` | ||
| echo "pybigquery" >> ./docker/requirements-local.txt | ||
| ``` | ||
|
|
||
| ### Connecting to BigQuery | ||
|
|
||
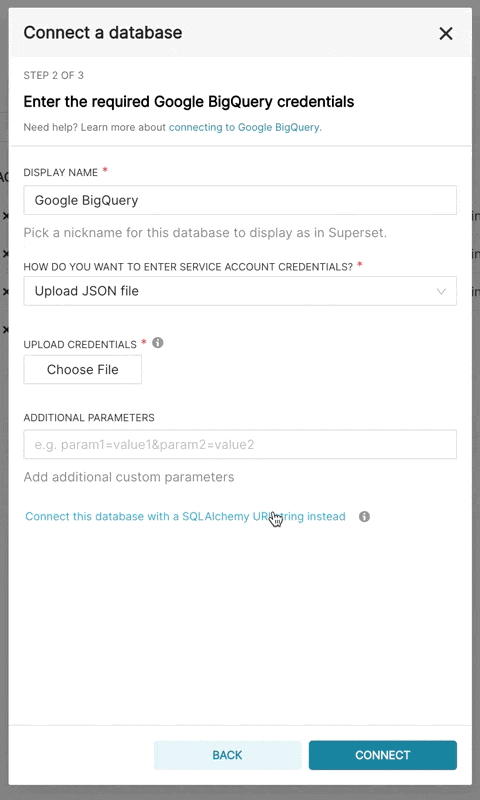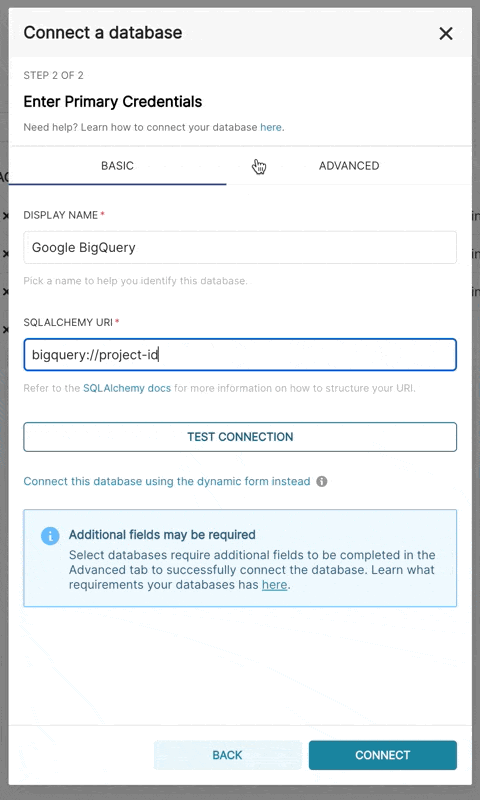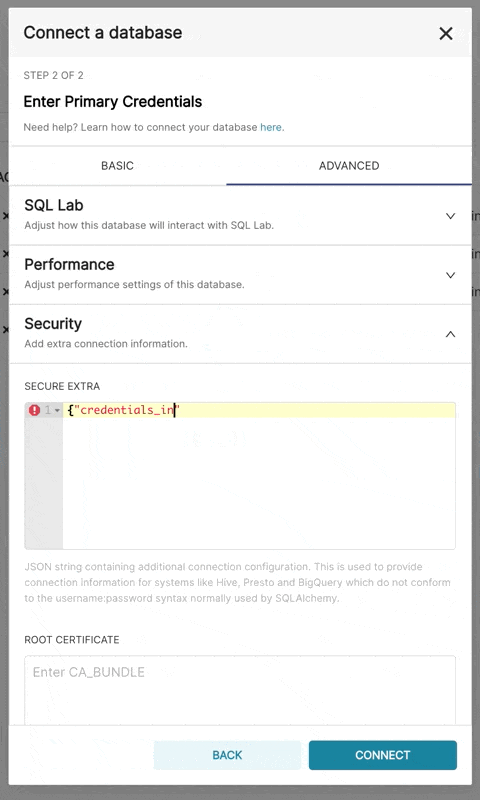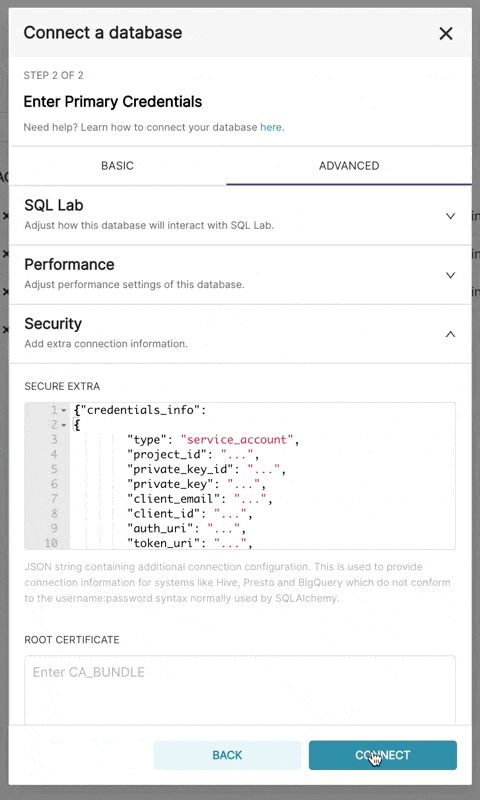
| When adding a new BigQuery connection in Superset, you'll need to add the GCP Service Account | ||
| credentials file (as a JSON). | ||
|
|
||
| 1. Create your Service Account via the Google Cloud Platform control panel, provide it access to the | ||
| appropriate BigQuery datasets, and download the JSON configuration file for the service account. | ||
| 2. In Superset, you can either upload that JSON or add the JSON blob in the following format (this should be the content of your credential JSON file): | ||
|
|
||
| ``` | ||
| { | ||
| "type": "service_account", | ||
| "project_id": "...", | ||
| "private_key_id": "...", | ||
| "private_key": "...", | ||
| "client_email": "...", | ||
| "client_id": "...", | ||
| "auth_uri": "...", | ||
| "token_uri": "...", | ||
| "auth_provider_x509_cert_url": "...", | ||
| "client_x509_cert_url": "..." | ||
| } | ||
| ``` | ||
|
|
||
|  | ||
|
|
||
| 3. Additionally, can connect via SQLAlchemy URI instead | ||
|
|
||
| The connection string for BigQuery looks like: | ||
|
|
||
| ``` | ||
| bigquery://{project_id} | ||
| ``` | ||
|
|
||
| Go to the **Advanced** tab, Add a JSON blob to the **Secure Extra** field in the database configuration form with | ||
| the following format: | ||
|
|
||
| ``` | ||
| { | ||
| "credentials_info": <contents of credentials JSON file> | ||
| } | ||
| ``` | ||
|
|
||
| The resulting file should have this structure: | ||
|
|
||
| ``` | ||
| { | ||
| "credentials_info": { | ||
| "type": "service_account", | ||
| "project_id": "...", | ||
| "private_key_id": "...", | ||
| "private_key": "...", | ||
| "client_email": "...", | ||
| "client_id": "...", | ||
| "auth_uri": "...", | ||
| "token_uri": "...", | ||
| "auth_provider_x509_cert_url": "...", | ||
| "client_x509_cert_url": "..." | ||
| } | ||
| } | ||
| ``` | ||
|
|
||
| You should then be able to connect to your BigQuery datasets. | ||
|
|
||
|  | ||
|
|
||
| To be able to upload CSV or Excel files to BigQuery in Superset, you'll need to also add the | ||
| [pandas_gbq](https://github.com/pydata/pandas-gbq) library. |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,44 @@ | ||
| --- | ||
| title: Clickhouse | ||
| hide_title: true | ||
| sidebar_position: 15 | ||
| version: 1 | ||
| --- | ||
|
|
||
| ## Clickhouse | ||
|
|
||
| To use Clickhouse with Superset, you will need to add the following Python libraries: | ||
|
|
||
| ``` | ||
| clickhouse-driver==0.2.0 | ||
| clickhouse-sqlalchemy==0.1.6 | ||
| ``` | ||
|
|
||
| If running Superset using Docker Compose, add the following to your `./docker/requirements-local.txt` file: | ||
|
|
||
| ``` | ||
| clickhouse-driver>=0.2.0 | ||
| clickhouse-sqlalchemy>=0.1.6 | ||
| ``` | ||
|
|
||
| The recommended connector library for Clickhouse is | ||
| [sqlalchemy-clickhouse](https://github.com/cloudflare/sqlalchemy-clickhouse). | ||
|
|
||
| The expected connection string is formatted as follows: | ||
|
|
||
| ``` | ||
| clickhouse+native://<user>:<password>@<host>:<port>/<database>[?options…]clickhouse://{username}:{password}@{hostname}:{port}/{database} | ||
| ``` | ||
|
|
||
| Here's a concrete example of a real connection string: | ||
|
|
||
| ``` | ||
| clickhouse+native://demo:demo@github.demo.trial.altinity.cloud/default?secure=true | ||
| ``` | ||
|
|
||
| If you're using Clickhouse locally on your computer, you can get away with using a native protocol URL that | ||
| uses the default user without a password (and doesn't encrypt the connection): | ||
|
|
||
| ``` | ||
| clickhouse+native://localhost/default | ||
| ``` |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,17 @@ | ||
| --- | ||
| title: CockroachDB | ||
| hide_title: true | ||
| sidebar_position: 16 | ||
| version: 1 | ||
| --- | ||
|
|
||
| ## CockroachDB | ||
|
|
||
| The recommended connector library for CockroachDB is | ||
| [sqlalchemy-cockroachdb](https://github.com/cockroachdb/sqlalchemy-cockroachdb). | ||
|
|
||
| The expected connection string is formatted as follows: | ||
|
|
||
| ``` | ||
| cockroachdb://root@{hostname}:{port}/{database}?sslmode=disable | ||
| ``` |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,24 @@ | ||
| --- | ||
| title: CrateDB | ||
| hide_title: true | ||
| sidebar_position: 36 | ||
| version: 1 | ||
| --- | ||
|
|
||
| ## CrateDB | ||
|
|
||
| The recommended connector library for CrateDB is | ||
| [crate](https://pypi.org/project/crate/). | ||
| You need to install the extras as well for this library. | ||
| We recommend adding something like the following | ||
| text to your requirements file: | ||
|
|
||
| ``` | ||
| crate[sqlalchemy]==0.26.0 | ||
| ``` | ||
|
|
||
| The expected connection string is formatted as follows: | ||
|
|
||
| ``` | ||
| crate://crate@127.0.0.1:4200 | ||
| ``` |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,67 @@ | ||
| --- | ||
| title: Databricks | ||
| hide_title: true | ||
| sidebar_position: 37 | ||
| version: 1 | ||
| --- | ||
|
|
||
| ## Databricks | ||
|
|
||
| To connect to Databricks, first install [databricks-dbapi](https://pypi.org/project/databricks-dbapi/) with the optional SQLAlchemy dependencies: | ||
|
|
||
| ```bash | ||
| pip install databricks-dbapi[sqlalchemy] | ||
| ``` | ||
|
|
||
| There are two ways to connect to Databricks: using a Hive connector or an ODBC connector. Both ways work similarly, but only ODBC can be used to connect to [SQL endpoints](https://docs.databricks.com/sql/admin/sql-endpoints.html). | ||
|
|
||
| ### Hive | ||
|
|
||
| To use the Hive connector you need the following information from your cluster: | ||
|
|
||
| - Server hostname | ||
| - Port | ||
| - HTTP path | ||
|
|
||
| These can be found under "Configuration" -> "Advanced Options" -> "JDBC/ODBC". | ||
|
|
||
| You also need an access token from "Settings" -> "User Settings" -> "Access Tokens". | ||
|
|
||
| Once you have all this information, add a database of type "Databricks (Hive)" in Superset, and use the following SQLAlchemy URI: | ||
|
|
||
| ``` | ||
| databricks+pyhive://token:{access token}@{server hostname}:{port}/{database name} | ||
| ``` | ||
|
|
||
| You also need to add the following configuration to "Other" -> "Engine Parameters", with your HTTP path: | ||
|
|
||
| ``` | ||
| {"connect_args": {"http_path": "sql/protocolv1/o/****"}} | ||
| ``` | ||
|
|
||
| ### ODBC | ||
|
|
||
| For ODBC you first need to install the [ODBC drivers for your platform](https://databricks.com/spark/odbc-drivers-download). | ||
|
|
||
| For a regular connection use this as the SQLAlchemy URI: | ||
|
|
||
| ``` | ||
| databricks+pyodbc://token:{access token}@{server hostname}:{port}/{database name} | ||
| ``` | ||
|
|
||
| And for the connection arguments: | ||
|
|
||
| ``` | ||
| {"connect_args": {"http_path": "sql/protocolv1/o/****", "driver_path": "/path/to/odbc/driver"}} | ||
| ``` | ||
|
|
||
| The driver path should be: | ||
|
|
||
| - `/Library/simba/spark/lib/libsparkodbc_sbu.dylib` (Mac OS) | ||
| - `/opt/simba/spark/lib/64/libsparkodbc_sb64.so` (Linux) | ||
|
|
||
| For a connection to a SQL endpoint you need to use the HTTP path from the endpoint: | ||
|
|
||
| ``` | ||
| {"connect_args": {"http_path": "/sql/1.0/endpoints/****", "driver_path": "/path/to/odbc/driver"}} | ||
| ``` |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,76 @@ | ||
| --- | ||
| title: Using Database Connection UI | ||
| hide_title: true | ||
| sidebar_position: 3 | ||
| version: 1 | ||
| --- | ||
|
|
||
| Here is the documentation on how to leverage the new DB Connection UI. This will provide admins the ability to enhance the UX for users who want to connect to new databases. | ||
|
|
||
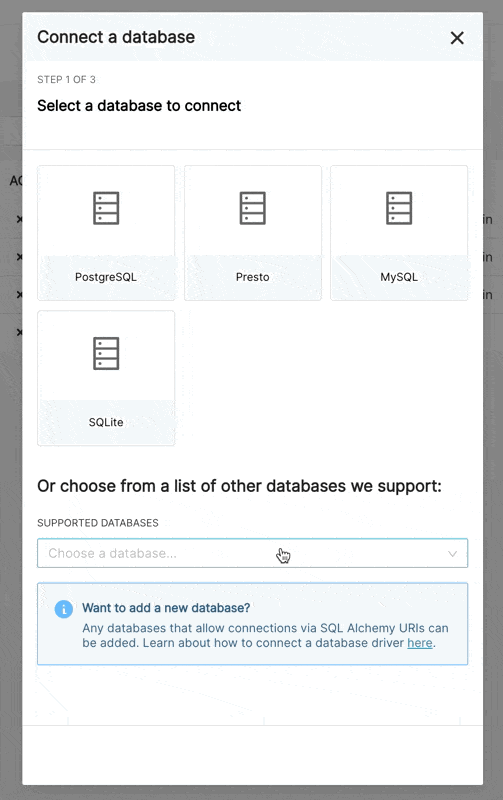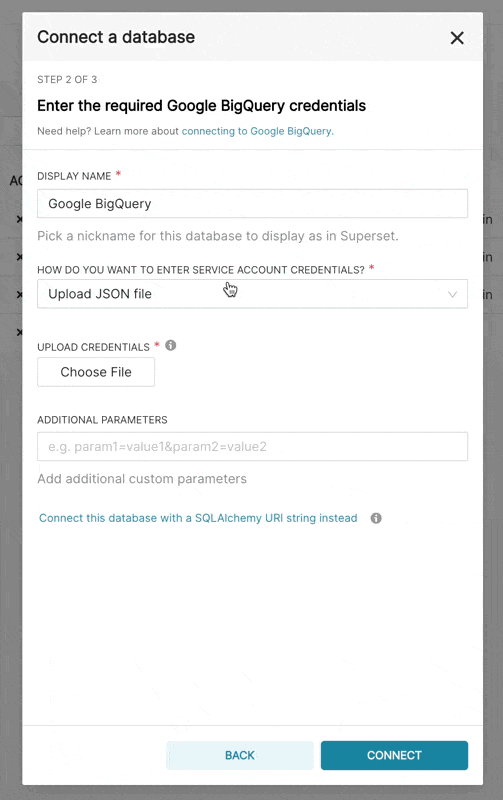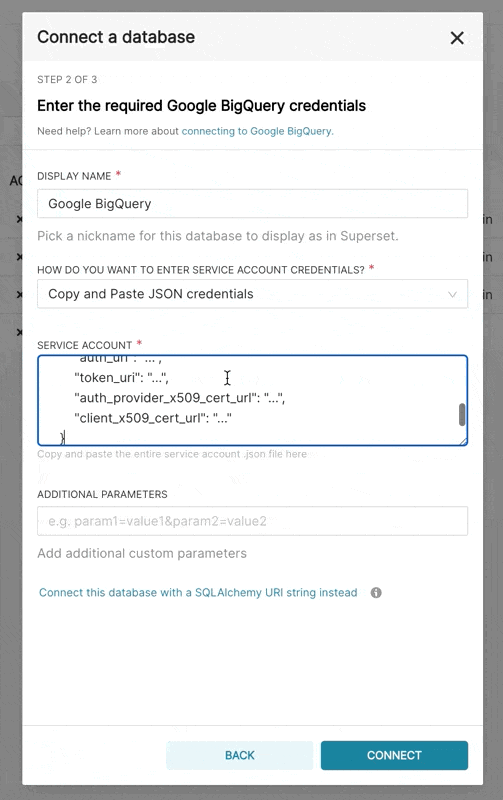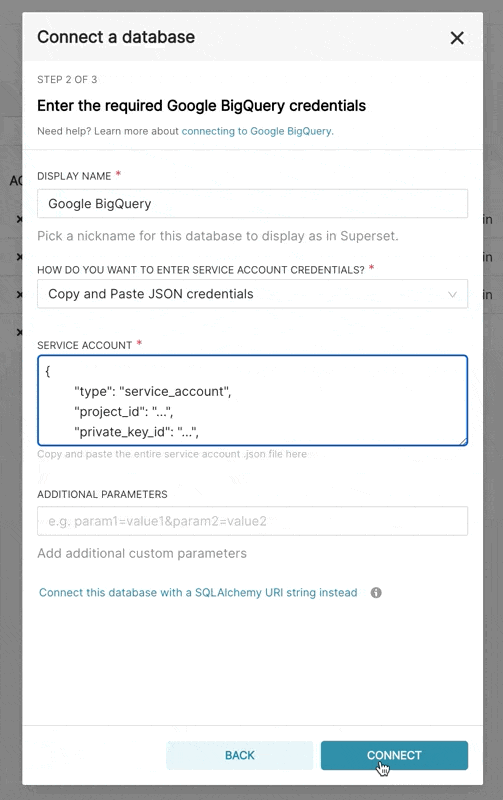
| 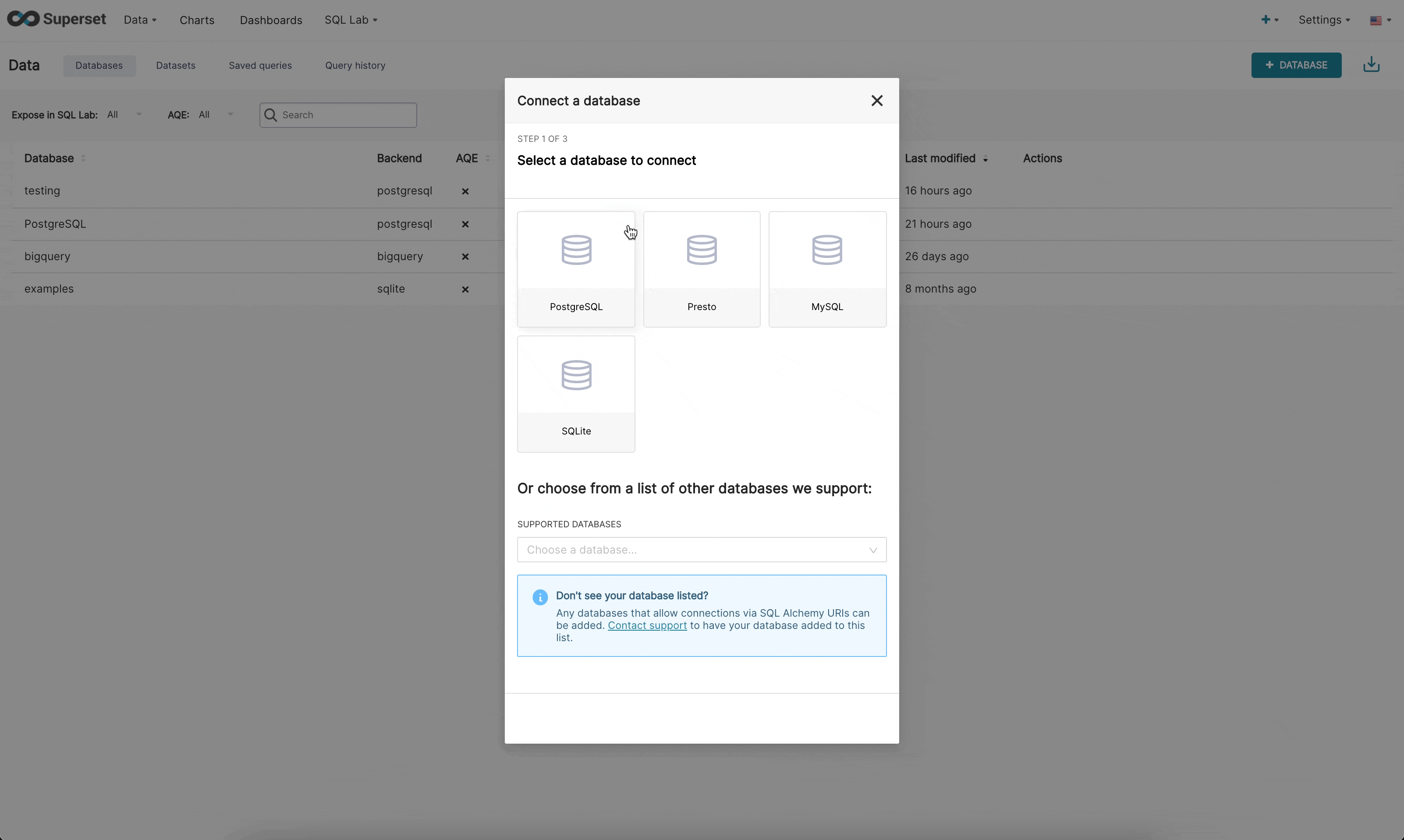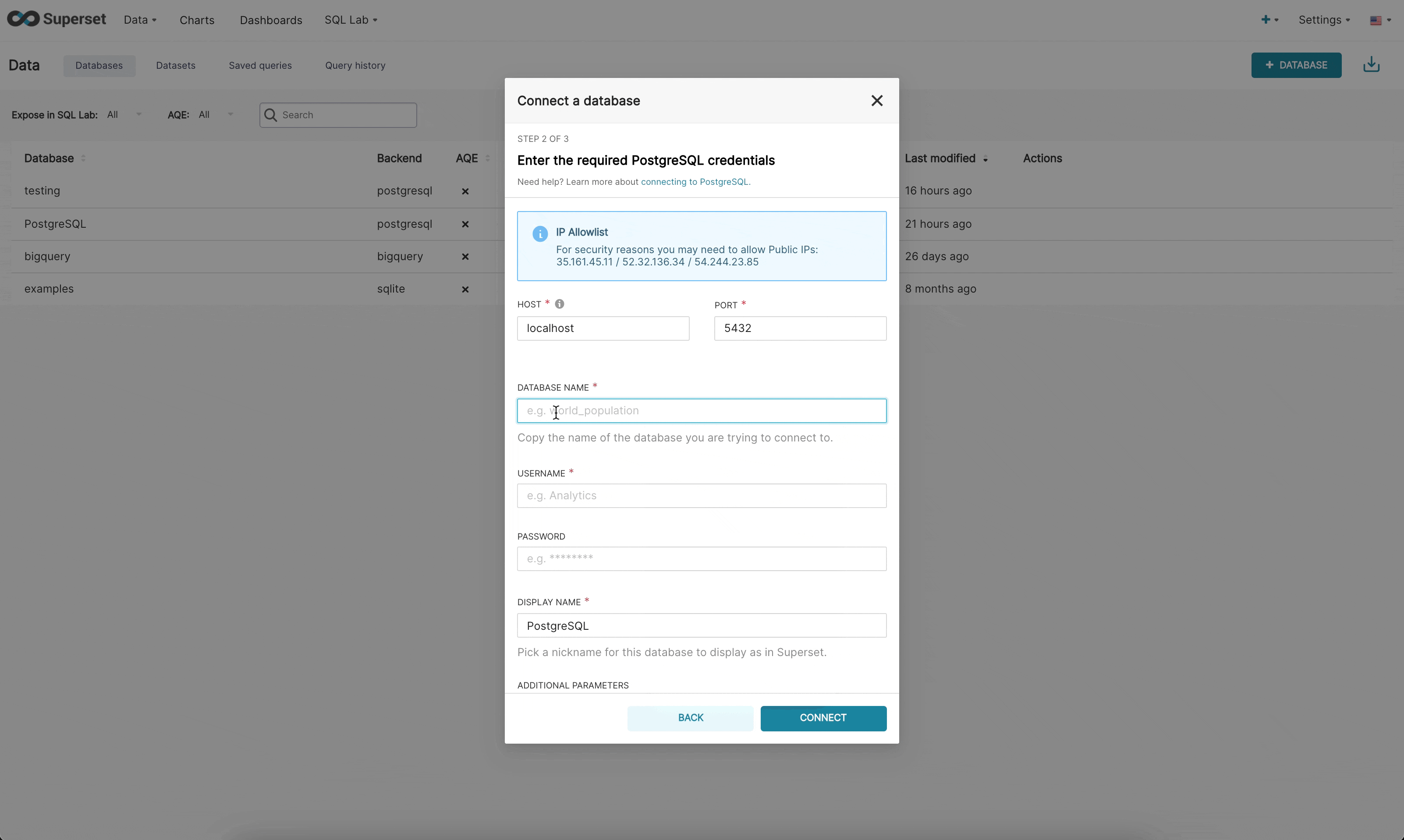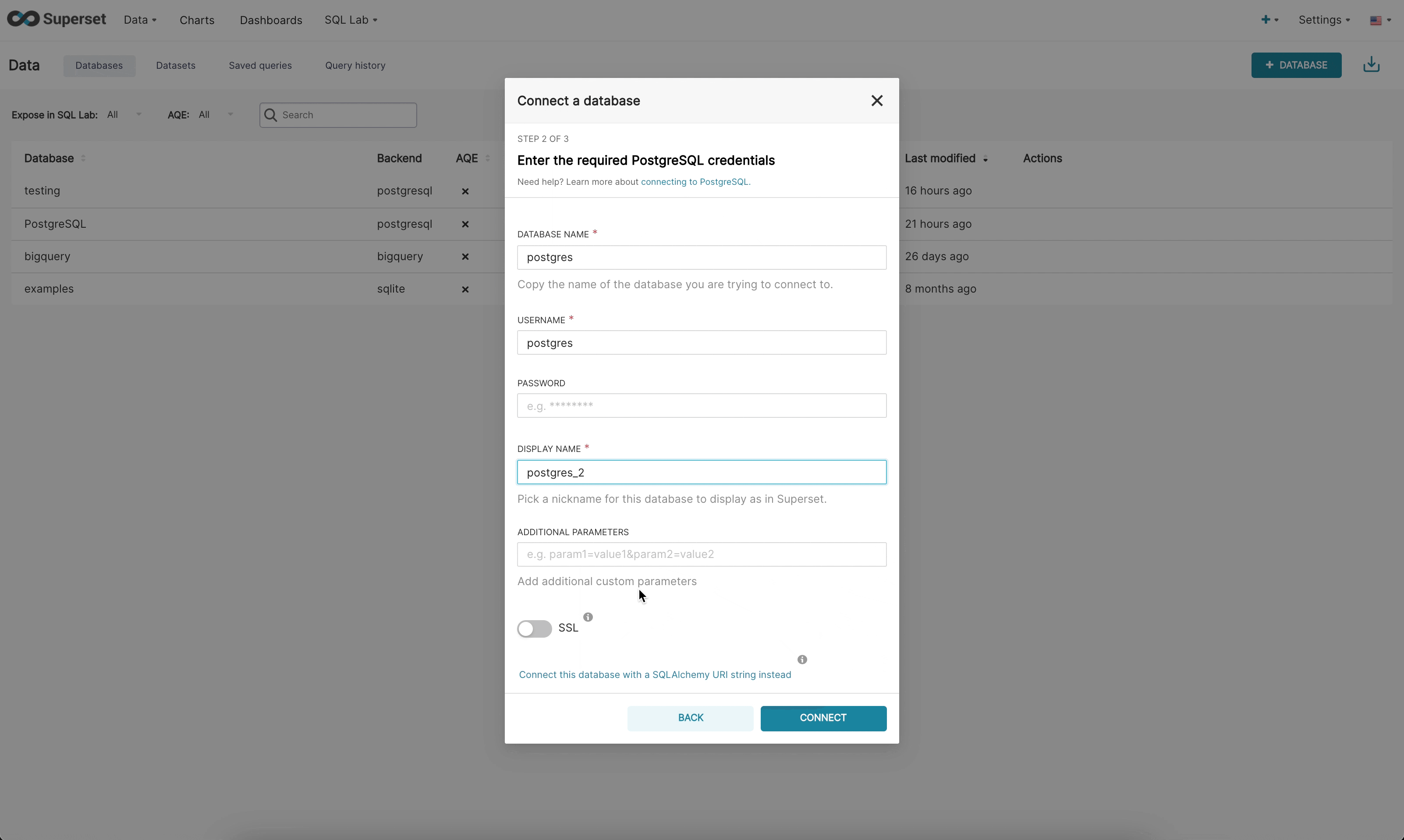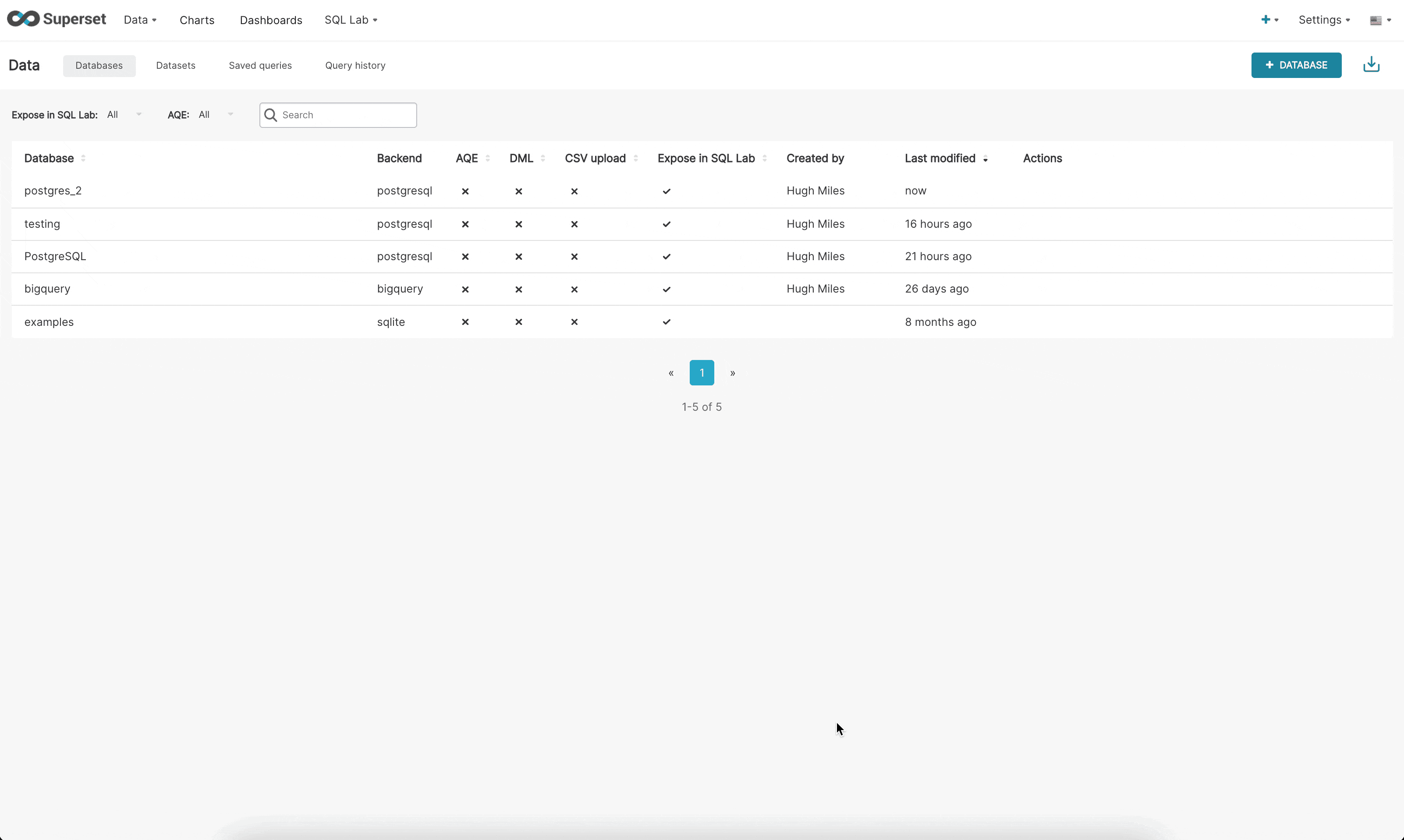 | ||
|
|
||
| There are now 3 steps when connecting to a database in the new UI: | ||
|
|
||
| Step 1: First the admin must inform superset what engine they want to connect to. This page is powered by the `/available` endpoint which pulls on the engines currently installed in your environment, so that only supported databases are shown. | ||
|
|
||
| Step 2: Next, the admin is prompted to enter database specific parameters. Depending on whether there is a dynamic form available for that specific engine, the admin will either see the new custom form or the legacy SQLAlchemy form. We currently have built dynamic forms for (Redshift, MySQL, Postgres, and BigQuery). The new form prompts the user for the parameters needed to connect (for example, username, password, host, port, etc.) and provides immediate feedback on errors. | ||
|
|
||
| Step 3: Finally, once the admin has connected to their DB using the dynamic form they have the opportunity to update any optional advanced settings. | ||
|
|
||
| We hope this feature will help eliminate a huge bottleneck for users to get into the application and start crafting datasets. | ||
|
|
||
| ### How to setup up preferred database options and images | ||
|
|
||
| We added a new configuration option where the admin can define their preferred databases, in order: | ||
|
|
||
| ```python | ||
| # A list of preferred databases, in order. These databases will be | ||
| # displayed prominently in the "Add Database" dialog. You should | ||
| # use the "engine_name" attribute of the corresponding DB engine spec | ||
| # in `superset/db_engine_specs/`. | ||
| PREFERRED_DATABASES: List[str] = [ | ||
| "PostgreSQL", | ||
| "Presto", | ||
| "MySQL", | ||
| "SQLite", | ||
| ] | ||
| ``` | ||
|
|
||
| For copyright reasons the logos for each database are not distributed with Superset. | ||
|
|
||
| ### Setting images | ||
|
|
||
| - To set the images of your preferred database, admins must create a mapping in the `superset_text.yml` file with engine and location of the image. The image can be host locally inside your static/file directory or online (e.g. S3) | ||
|
|
||
| ```python | ||
| DB_IMAGES: | ||
| postgresql: "path/to/image/postgres.jpg" | ||
| bigquery: "path/to/s3bucket/bigquery.jpg" | ||
| snowflake: "path/to/image/snowflake.jpg" | ||
| ``` | ||
|
|
||
| ### How to add new database engines to available endpoint | ||
|
|
||
| Currently the new modal supports the following databases: | ||
|
|
||
| - Postgres | ||
| - Redshift | ||
| - MySQL | ||
| - BigQuery | ||
|
|
||
| When the user selects a database not in this list they will see the old dialog asking for the SQLAlchemy URI. New databases can be added gradually to the new flow. In order to support the rich configuration a DB engine spec needs to have the following attributes: | ||
|
|
||
| 1. `parameters_schema`: a Marshmallow schema defining the parameters needed to configure the database. For Postgres this includes username, password, host, port, etc. ([see](https://github.com/apache/superset/blob/accee507c0819cd0d7bcfb5a3e1199bc81eeebf2/superset/db_engine_specs/base.py#L1309-L1320)). | ||
| 2. `default_driver`: the name of the recommended driver for the DB engine spec. Many SQLAlchemy dialects support multiple drivers, but usually one is the official recommendation. For Postgres we use "psycopg2". | ||
| 3. `sqlalchemy_uri_placeholder`: a string that helps the user in case they want to type the URI directly. | ||
| 4. `encryption_parameters`: parameters used to build the URI when the user opts for an encrypted connection. For Postgres this is `{"sslmode": "require"}`. | ||
|
|
||
| In addition, the DB engine spec must implement these class methods: | ||
|
|
||
| - `build_sqlalchemy_uri(cls, parameters, encrypted_extra)`: this method receives the distinct parameters and builds the URI from them. | ||
| - `get_parameters_from_uri(cls, uri, encrypted_extra)`: this method does the opposite, extracting the parameters from a given URI. | ||
| - `validate_parameters(cls, parameters)`: this method is used for `onBlur` validation of the form. It should return a list of `SupersetError` indicating which parameters are missing, and which parameters are definitely incorrect ([example](https://github.com/apache/superset/blob/accee507c0819cd0d7bcfb5a3e1199bc81eeebf2/superset/db_engine_specs/base.py#L1404)). | ||
|
|
||
| For databases like MySQL and Postgres that use the standard format of `engine+driver://user:password@host:port/dbname` all you need to do is add the `BasicParametersMixin` to the DB engine spec, and then define the parameters 2-4 (`parameters_schema` is already present in the mixin). | ||
|
|
||
| For other databases you need to implement these methods yourself. The BigQuery DB engine spec is a good example of how to do that. |
Oops, something went wrong.