![]()
Schema and data analyzer for MongoDB written in Go.


Mongoeye provides a quick overview of the data in your MongoDB database.
- Fast: the fastest schema analyzer for MongoDB
- Single binary: pre-built binaries for Windows, Linux, and MacOS (Darwin)
- Local analysis: quick local analysis using a parallel algorithm (MongoDB 2.0+)
- Remote analysis: distributed analysis in database using the aggregation framework (MongoDB 3.5.10+)
- Rich features: histogram (value, length, weekday, hour), most frequent values, ...
- Integrable: table, JSON or YAML output

Mongoeye is one executable binary file.
You can download the archive from GitHub releases page and extract the binary file for your platform.
It is required to have Go 1.8. All external dependencies are part of the repository in the vendor directory.
Compilation process:
$ go get github.com/mongoeye/mongoeye
$ cd $GOPATH/src/github.com/mongoeye/mongoeye
$ make build
For development, you need additional dependencies that can be installed using make get-deps.
The test architecture uses the Docker to create the testing MongoDB database.
If you want to contribute to this project, see the actions in Makefile and the _contrib directory.
mongoeye [host] database collection [flags]
The command mongoeye --help lists all available options.
Default output format is table. It shows only schema without other analyzes.
Example table output:
KEY │ COUNT │ %
────────────────────────────────────────────
all documents │ 2548 │
analyzed documents │ 1000 │ 39.2
│ │
_id - objectId │ 1000 │ 100.0
address │ 1000 │ 100.0
│ - int │ 1 │ 0.1
└╴- string │ 999 │ 99.9
address line 2 - string │ 1000 │ 100.0
name - string │ 1000 │ 100.0
outcode - string │ 1000 │ 100.0
postcode - string │ 1000 │ 100.0
rating │ 1000 │ 100.0
│ - int │ 523 │ 52.3
│ - double │ 451 │ 45.1
└╴- string │ 26 │ 2.6
type_of_food - string │ 1000 │ 100.0
URL - string │ 1000 │ 100.0
OK 0.190s (local analysis)
1000/2548 docs (39.2%)
9 fields, depth 2
Use --format json or --format yaml flags to set these formats.
For output to a file use the option -F /path/to/file.
This chapter explains the features of Mongoeye and their various outputs.
Use --format json or --format yaml to get detailed results, otherwise only the schema table will appear.
The output of the analysis always contains these basic keys:
- database: database name
- collection: collection name
- plan:
localfor local analysis,dbfor analysis using aggregation framework - duration: duration of analysis
- allDocs: number of all documents in collection
- analyzedDocs: number of analyzed documents from collection
- fieldsCount: number of found fields
- fields: result of the analysis for each field
- name: name of field
- level: level of nested field,
0is root level - count: number of occurrences
- types: result of the analysis for each type of field
- type: name of type
- count: number of occurrences of type
Example result:
database: company
collection: users
plan: local
duration: 46.515331ms
allDocs: 2548
analyzedDocs: 1000
fieldsCount: 9
fields:
- name: rating
level: 0
count: 1000
types:
- type: int
count: 549
< other outputs according to settings >Use the flag --value or -v to enable calculation of minimum, maximum, and average values.
Supported types:
- Minimum and maximum:
objectId,double,string,bool,date,int,timestamp,long,decimal - Average:
double,bool,int,long,decimal
Example result:
value:
min: 11.565586
max: 60.206787
avg: 38.51128Use the flag --length or -l to enable calculation of minimum, maximum, and average lengths.
Supported types: string, array, object
Example result:
length:
min: 29
max: 153
avg: 112Use the flag --count-unique to count all unique values.
Supported types: double, string, date, int, timestamp, long, decimal
Example result:
unique: 894Use the flag --most-freq N or --least-freq N to get the most or least occurring values.
Supported types: double, string, date, int, timestamp, long, decimal
Example result:
mostFrequent:
- value: USD
count: 599
- value: EUR
count: 21
- value: GBP
count: 5
- value: CAD
count: 4
leastFrequent:
- value: EUR
count: 21
- value: GBP
count: 5
- value: CAD
count: 4
- value: JPY
count: 3Use the flag --value-hist or -V to generate value histogram.
Supported types: objectId - processed as a date, double, date, int, long, decimal
Flag --value-hist-steps sets the maximum number of steps (default 100).
- Step of the
intandlongtype is a whole number - Step of the
doubleanddecimaltype is:- the smallest possible multiplication of [
1,5or2.5] and10^nso the max. number of steps is kept - eg. ...,
100,50,25,10,5,2.5,1,0.5,0.25,0.1, ...
- the smallest possible multiplication of [
- Step of the
dateandobjectIdtype is rounded to:- 1, 2, 5, 10, 15, 30
seconds - 1, 2, 5, 10, 15, 30
minutes - 1, 2, 3, 6, 12
hours - 1, 2, 3, 4, ...
days
- 1, 2, 5, 10, 15, 30
Example result:
valueHistogram:
start: 2.5
end: 12
range: 9.5
step: 0.5
numOfSteps: 19
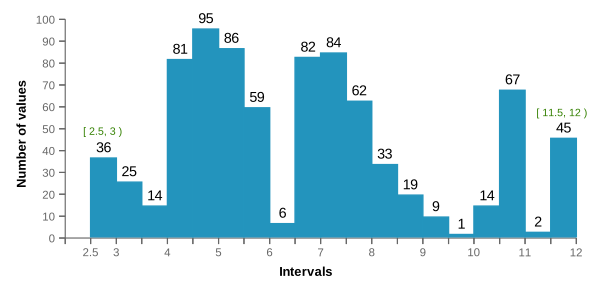
intervals: [36, 25, 14, 81, 95, 86, 59, 6, 82, 84, 62, 33, 19, 9, 1, 14, 67, 2, 45]Graphic representation:
Use the flag --length-hist or -L to generate length histogram.
Flag --length-hist-steps sets the maximum number of steps (default 100).
Supported types: string, array, object
Example result:
lengthHistogram:
start: 0
end: 300
range: 300
step: 50
numOfSteps: 6
intervals: [96, 78, 3, 1, 1, 0]Use the flag --weekday-hist or -W to generate weekday histogram.
To determine the day of week it uses the time zone from the --timezone flag (default local).
First day is Sunday.
Example result:
weekdayHistogram: [5, 48, 23, 124, 45, 15, 87]Use the flag --hour-hist or -H to generate weekday histogram.
To determine the hour it uses the time zone from the --timezone flag (default local).
First value is for interval [ 00, 01 ), last for interval [ 23, 24 ).
Example result:
hourHistogram: [47, 73, 18, 26, 30, 46, 91, 13, 28, 11, 52, 99, 76, 25, 94, 51, 87, 86, 19, 22, 11, 62, 28, 47]The scope of analysis is defined by the following options.
The --match option is applied as the first:
- it selects documents for the analysis using $match aggregation
- value is a string in JSON format
- suitable for include/exclude documents from analysis
- by default, all documents are included (if the argument is not present)
The --sample option is applied as the second:
- determines the sampling method using $sort, $limit and $sample aggregations
- valid values are:
all,first:N,last:N,random:N, whereN > 1 - default value is
random:1000
The --project option is applied as the third:
- before the analysis it modifies document using $project aggregation
- value is a string in JSON format
- suitable for include/exclude fields from analysis
- default is not applied (if the argument is not present)
Note: Be sure to escape JSON options correctly, eg. --project "{\"Field\": 0}".
--host mongodb host (default "localhost:27017")
--connection-mode connection mode (default "SecondaryPreferred")
--connection-timeout connection timeout (default 5)
--socket-timeout socket timeout (default 300)
--sync-timeout sync timeout (default 300)
-u, --user username for authentication (default "admin")
-p, --password password for authentication
--auth-db auth database (default: same as the working db)
--auth-mech auth mechanism
--db database for analysis
--col collection for analysis
--match filter documents before analysis (json, $match aggregation)
-s, --sample all, first:N, last:N, random:N (default "random:1000")
--project filter/project fields before analysis (json, $project aggregation)
-d, --depth max depth in nested documents (default 2)
--full all available analyzes
-v, --value get min, max, avg value
-l, --length get min, max, avg length
-V, --value-hist get value histogram
--value-hist-steps max steps of value histogram >=3 (default 100)
-L, --length-hist get length histogram
--length-hist-steps max steps of length histogram >=3 (default 100)
-W, --weekday-hist get weekday histogram for dates
-H, --hour-hist get hour histogram for dates
--count-unique get count of unique values
--most-freq get the N most frequent values
--least-freq get the N least frequent values
-f, --format output format: table, json, yaml (default "table")
-F, --file path to the output file
-t, --timezone timezone, eg. UTC, Europe/Berlin (default "local")
--use-aggregation analyze with aggregation framework (mongodb 3.5.10+)
--string-max-length max string length (default 100)
--array-max-length analyze only first N array elements (default 20)
--concurrency number of local processes (default 0 = auto)
--buffer size of the buffer between local stages (default 5000)
--batch size of batch from database (default 500)
--no-color disable color output
--version show version
-h, --help show this help
Environment variables can also be used for configuration.
The names of the environment variables have the MONGOEYE_ prefix and match the flags.
Instead of the --count-unique flag, for example, you can use export MONGOEYE_COUNT-UNIQUE=true.
- Create a shared library for integration into other languages (Python, Node.js, ...)
- Selection of fields for analysis (include and exclude list)
- TLS/SSL support
- Create a web interface.
If is this tool useful to you, so feel free to support its further development.

{kind=link}
Mongoeye is under the GPL-3.0 license. See the LICENSE file for details.
AMDG