CS412 course project at University of Illinois at Chicago.
To perform sentiment analysis over a corpus of tweets during the U.S. 2012 Re-Election about the candidates Barack Obama and Mitt Romney.
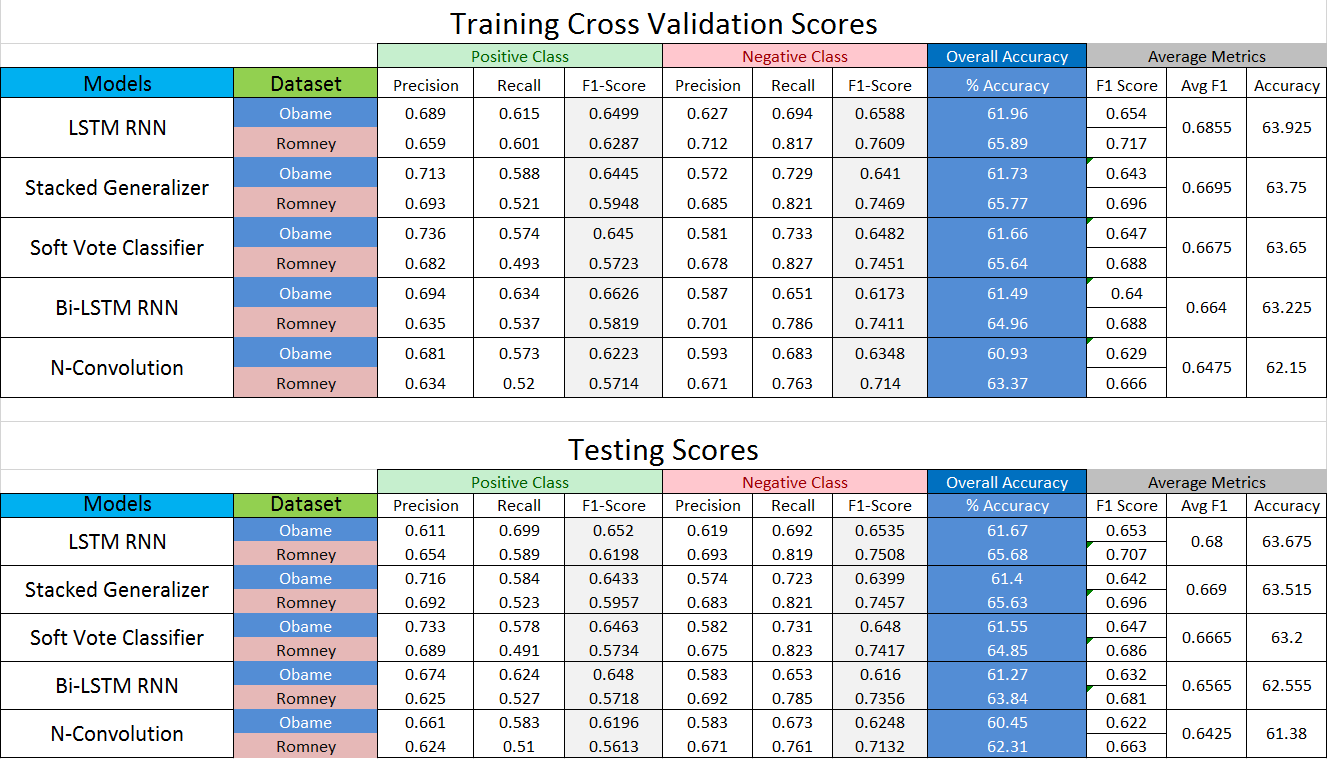
The previous best score on the test dataset was 64 % f1-score, suggesting that improvements can be obtained using modern machine learning / deep learning algorithms.
This task has several stages
The text corpus provided has many irrelevant textual information, such as hash tags, URLs and numbers which were deemed meaningless to a sentiment classifier. They were thus removed
The pre-processed datasets was then merged into a single text corpus, for an approach we describe as "Joint Training". This increases the number of samples that the deep learning models have to determing a classification, and that is highly benefitial considering the tendency of LSTMs to overfit.
Other pre-processing such as tokenization, n-grams, tf-idf vectorization and so on were also performed to improve the quality of the training data. GLoVe embeddings, which were trained on the 840 billion word dataset was used to provide a strong pre-trained initialization of embeddings for the deep learning models.
Training was split into 3 branches, Machine Learning, Deep Learning and Ensemble Learning.
Each machine learning model was trained on 100 fold stratified cross validation, to obtain 100 different models for the 7 different ML models we tried. All models were optimized using cross validation.
Each Deep Learning model was trained on 10 fold stratified cross validation, to obtain 10 different models for the 4 different DL models we tried. The LSTM model was optimized via cross validation.
We performed 10 fold cross validation on both the Stacked Generalization model and Soft Voting classifier.
The LSTM RNN performed the best, getting a test time score of nearly 68 %, beating the earlier 64 % benchmark.
The strongest ensemble learning model was the Stacked Ensemble, achieving the second highest score of 66.9 %.