![]()
Download • Quick Start • Contribution Guide • License • Documentation • Publication
ForteHealth is in the incubation stage and still under development
Bring good software engineering to your Biomedical/Clinical ML solutions, starting from Data!
ForteHealth is a biomedical and clinical domain centric framework designed to engineer complex ML workflows for several tasks including, but not limited to, Medical Entity Recognition, Negation Context Analysis and ICD Coding. ForteHealth allows practitioners to build ML components in a composable and modular way. It works in conjunction with Forte and Forte-wrappers project, and leverages the tools defined there to execute general tasks vital in the biomedical and clinical use cases.
To install from source:
git clone https://github.com/asyml/ForteHealth.git
cd ForteHealth
pip install .To install some Forte adapter for some existing libraries:
Install from PyPI:
pip install forte.healthSome tools are pre-requisites to a few tasks in our pipeline. For example, forte.spacy and stave maybe needed for a pipeline that implements NER with visualisation and so on, depending on the use case.
# To install other tools. Check here https://github.com/asyml/forte-wrappers#libraries-and-tools-supported for available tools.
pip install forte.spacy
pip install staveSome components or modules in forte may require some extra requirements:
Install ScispaCyProcessor:
pip install 'forte.health[scispacy_processor]'Install TemporalNormalizingProcessor:
pip install 'forte.health[normalizer_processor]'Writing biomedical NLP pipelines with ForteHealth is easy. The following example creates a simple pipeline that analyzes the sentences, tokens, and medical named entities from a discharge note.
Before we start, make sure the SpaCy wrapper is installed.
Also, make sure you have input text files in the input_path directory that are passed through to the processors.
pip install forte.spacyLet's look at an example of a full fledged medical pipeline:
from fortex.spacy import SpacyProcessor
from forte.data.data_pack import DataPack
from forte.data.readers import PlainTextReader
from forte.pipeline import Pipeline
from ft.onto.base_ontology import Sentence, EntityMention
from ftx.medical.clinical_ontology import NegationContext, MedicalEntityMention
from fortex.health.processors.negation_context_analyzer import (
NegationContextAnalyzer,
)
pl = Pipeline[DataPack]()
pl.set_reader(PlainTextReader())
pl.add(SpacyProcessor(), config={
"processors": ["sentence", "tokenize", "pos", "ner", "umls_link"],
"medical_onto_type": "ftx.medical.clinical_ontology.MedicalEntityMention",
"umls_onto_type": "ftx.medical.clinical_ontology.UMLSConceptLink",
"lang": "en_ner_bc5cdr_md"
})
pl.add(NegationContextAnalyzer())
pl.initialize()Here we have successfully created a pipeline with a few components:
- a
PlainTextReaderthat reads data from text files, given by theinput_path - a
SpacyProcessorthat calls SpaCy to split the sentences, create tokenization, pos tagging, NER and umls_linking - finally, the processor
NegationContextAnalyzerdetects negated contexts
Let's see it run in action!
for pack in pl.process_dataset(input_path):
for sentence in pack.get(Sentence):
medical_entities = []
for entity in pack.get(MedicalEntityMention, sentence):
for ent in entity.umls_entities:
medical_entities.append(ent)
negation_contexts = [
(negation_context.text, negation_context.polarity)
for negation_context in pack.get(NegationContext, sentence)
]
print("UMLS Entity Mentions detected:", medical_entities, "\n")
print("Entity Negation Contexts:", negation_contexts, "\n")We have successfully created a simple pipeline. In the nutshell, the DataPacks are
the standard packages "flowing" on the pipeline. They are created by the reader, and
then pass along the pipeline.
Each processor, such as our SpacyProcessor NegationContextAnalyzer,
interfaces directly with DataPacks and do not need to worry about the
other part of the pipeline, making the engineering process more modular.
The above mentioned code snippet has been taken from the Examples folder.
To learn more about the details, check out of documentation! The classes used in this guide can also be found in this repository or the Forte Wrappers repository
The data-centric abstraction of Forte opens the gate to many other opportunities. Go to this link for more information
To learn more about these, you can visit:
- Examples
- Documentation
- Currently we are working on some interesting tutorials, stay tuned for a full set of documentation on how to do NLP with Forte!
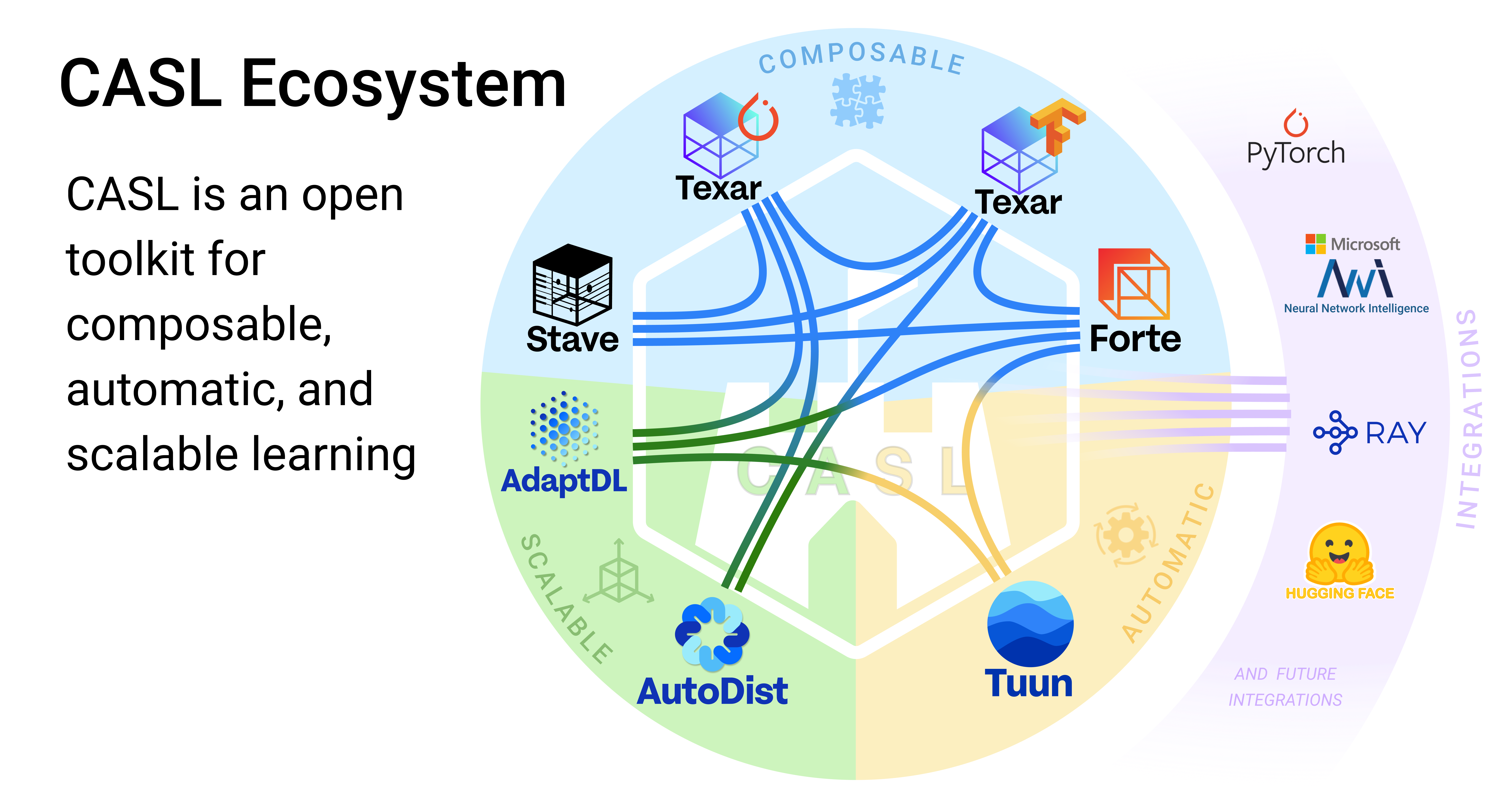
This project is part of the CASL Open Source family.
If you are interested in making enhancement to Forte, please first go over our Code of Conduct and Contribution Guideline