x86_64:
![]()
![]()
![]()
![]()
Other:
![]()
![]()
Kiwi는 빠른 속도와 범용적인 성능을 지향하는 한국어 형태소 분석기 라이브러리입니다. 한국어 처리에 관심 있는 사람이면 누구나 쉽게 사용할 수 있도록 오픈 소스로 공개 중이며, C++로 구현된 코어 라이브러리를 래핑하여 다양한 프로그래밍 언어에 사용할 수 있도록 준비 중입니다.
형태소 분석은 세종 품사 태그 체계를 기반으로 하고 있으며 모델 학습에는 세종계획 말뭉치와 모두의 말뭉치를 사용하고 있습니다. 웹 텍스트의 경우 약 87%, 문어 텍스트의 경우 약 94% 정도의 정확도로 한국어 문장의 형태소를 분석해 낼 수 있습니다. 또한 간단한 오타의 경우 모델 스스로 교정하는 기능을 지원합니다(0.13.0버전 이후).
아직 부족한 부분이 많기에 개발자분들의 많은 관심과 기여 부탁드립니다.
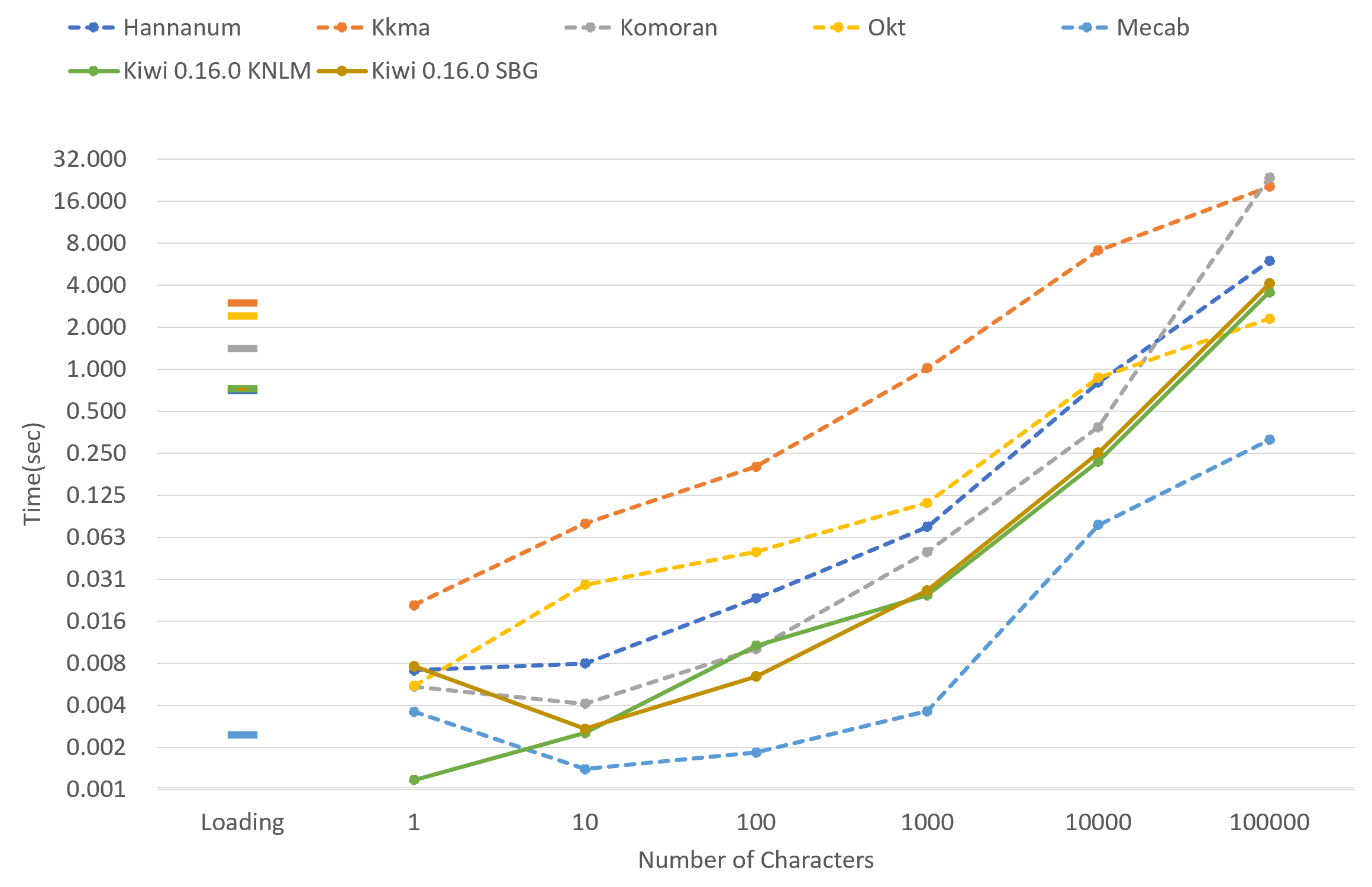
텍스트 분석 속도가 다른 한국어 형태소분석기들과 비교하여 꽤 빠른 편입니다. 자세한 벤치마크 결과는 이 문서에서 확인 가능합니다.
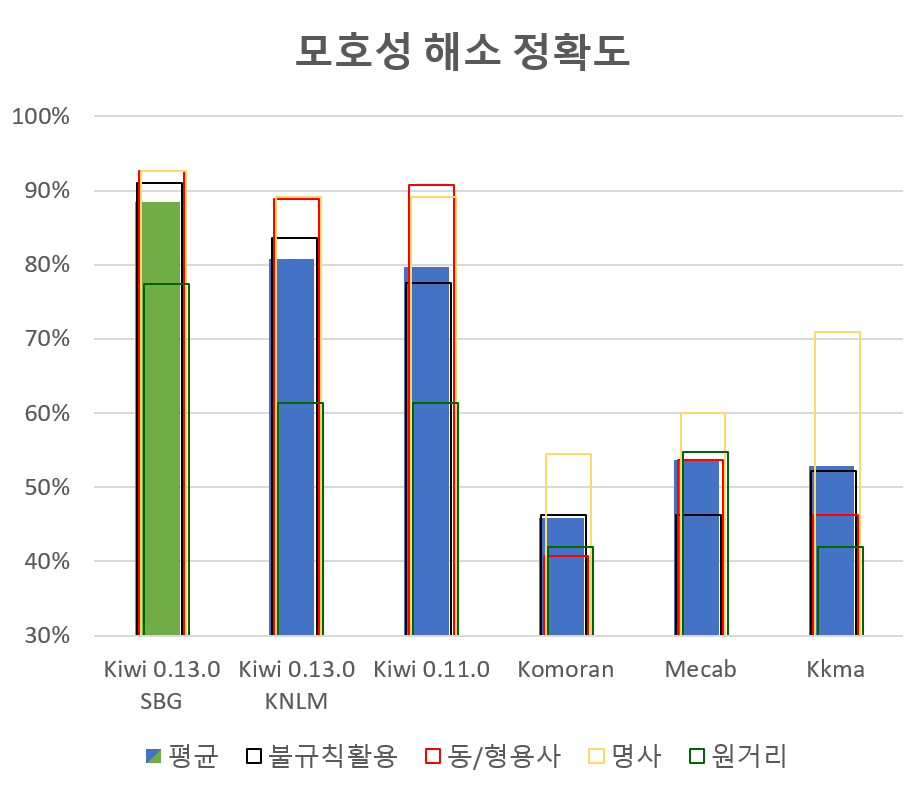
또한 자체적으로 경량 언어모델을 탑재하여 모호성이 있는 경우에도 제법 정확하게 형태소를 분석해냅니다. 특히 SBG모델을 사용 시 모호성 해소 성능이 크게 향상됩니다. (모호성 해소 성능 평가는 이 페이지에서 수행가능합니다. )
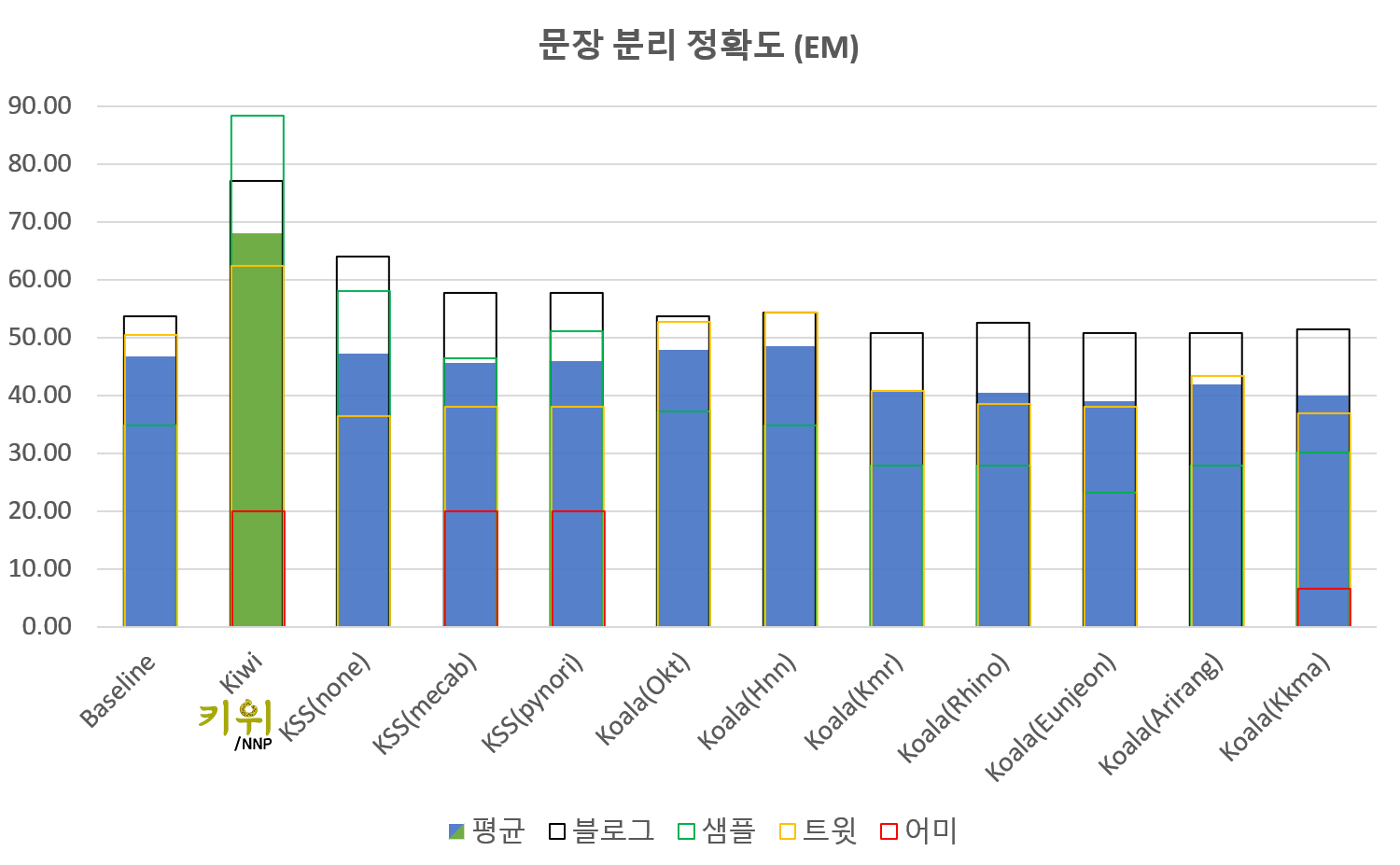
문장 분리 기능을 비롯한 다양한 편의기능을 제공합니다. (문장 분리 성능 평가는 이 페이지에서 수행가능합니다. )
라이브러리 차원에서 멀티스레딩을 지원하기 때문에 대량의 텍스트를 분석해야할 경우 멀티코어를 활용하여 빠른 분석이 가능합니다. 또한 다양한 시스템에서 상황에 맞춰 선택할 수 있도록 소형/중형/대형 모델을 제공합니다.
https://github.com/bab2min/Kiwi/releases 에서 Windows, Linux, macOS 버전으로 컴파일된 Library 파일과 모델 파일을 다운로드 받을 수 있습니다.
Visual Studio 2019 이상을 사용하여 Kiwi.sln 파일을 실행하여 컴파일할 수 있습니다.
이 레포지토리를 clone한 뒤 cmake>=3.12를 사용하여 컴파일합니다.
모델 파일은 용량이 큰 관계로 Git LFS를 통해 공유됩니다. 따라서 git clone에 앞서 Git LFS가 설치되어있는지 확인해주세요.
$ git clone https://github.com/bab2min/Kiwi
$ cd Kiwi
$ git lfs pull
$ git submodule sync
$ git submodule update --init --recursive
$ mkdir build && cd build
$ cmake -DCMAKE_BUILD_TYPE=Release ../
$ make
$ make install
$ ldconfigCentos5와 같이 gcc 4.8까지만 지원하는 환경에서는 googletest의 버전을 1.8.x로 낮춰야 컴파일 가능합니다.
$ git clone https://github.com/bab2min/Kiwi
$ cd Kiwi
$ git lfs pull
$ git submodule sync
$ git submodule update --init --recursive
$ cd third_party/googletest && git checkout v1.8.x && cd ../../
$ mkdir build && cd build
$ cmake -DCMAKE_BUILD_TYPE=Release ../
$ make
$ make install
$ ldconfig설치가 잘 됐는지 확인하기 위해서는 kiwi-evaluator를 실행해봅니다.
$ ./kiwi-evaluator --model ../models/base ../eval_data/* --sbg
Loading Time : 981.745 ms
ArchType : avx2
LM Size : 34.1853 MB
Mem Usage : 278.129 MB
Test file: eval_data/web.txt
0.862114, 0.852863
Total (158 lines) Time : 301.702 ms
Time per Line : 1.9095 ms
================
Test file: eval_data/written.txt
0.942892, 0.943506
Total (33 lines) Time : 62.3999 ms
Time per Line : 1.89091 ms
================
Test file: eval_data/web_with_typos.txt
0.754417, 0.720886
Total (97 lines) Time : 99.7661 ms
Time per Line : 1.02852 ms
================
================
Avg Score
0.853141, 0.839085
================0.13.0 버전부터 추가된 오타 교정 기능이 잘 작동하는지 확인하기 위해서는 다음과 같이 실행합니다.
$ ./kiwi-evaluator --model ../models/base ../eval_data/* --sbg --typo 6
Loading Time : 9414.45 ms
ArchType : avx2
LM Size : 34.1853 MB
Mem Usage : 693.945 MB
Test file: eval_data/web.txt
0.86321, 0.85566
Total (158 lines) Time : 432.236 ms
Time per Line : 2.73567 ms
================
Test file: eval_data/written.txt
0.941712, 0.942217
Total (33 lines) Time : 95.3079 ms
Time per Line : 2.88812 ms
================
Test file: eval_data/web_with_typos.txt
0.869582, 0.865393
Total (97 lines) Time : 169.416 ms
Time per Line : 1.74656 ms
================
================
Avg Score
0.891501, 0.887757
================include/kiwi/capi.h 를 참조하세요.
https://github.com/bab2min/Kiwi/releases 에서 Windows, Linux, macOS 버전으로 컴파일된 Library 파일과 모델 파일을 다운로드 받을 수 있습니다.
https://github.com/bab2min/kiwi-gui
또한 Python3용 API인 Kiwipiepy가 제공됩니다. 이에 대해서는 https://github.com/bab2min/kiwipiepy 를 참조하시길 바랍니다.
Java 1.8 이상에서 사용 가능한 KiwiJava가 Java binding으로 제공됩니다. 이에 대해서는 bindings/java를 참조하시길 바랍니다.
mrchypark님께서 기여해주신 R언어용 wrapper인 elbird가 있습니다.
codingpot 커뮤니티가 작업해주신 go언어용 wrapper인 kiwigo가 있습니다.
RicBent님께서 기여해주신 Web Assembly binding이 있습니다. 이에 대해서는 bindings/wasm를 참조하시길 바랍니다.
Kiwi는 C# 기반의 GUI 형태로도 제공됩니다. 형태소 분석기는 사용해야하지만 별도의 프로그래밍 지식이 없는 경우 이 프로그램을 사용하시면 됩니다. 다음 프로그램은 Windows에서만 구동 가능합니다. https://github.com/bab2min/kiwi-gui 에서 다운받을 수 있습니다.
업데이트 내역은 릴리즈 노트를 참고해주세요.
세종 품사 태그를 기초로 하되, 일부 품사 태그를 추가/수정하여 사용하고 있습니다.
| 대분류 | 태그 | 설명 |
|---|---|---|
| 체언(N) | NNG | 일반 명사 |
| NNP | 고유 명사 | |
| NNB | 의존 명사 | |
| NR | 수사 | |
| NP | 대명사 | |
| 용언(V) | VV | 동사 |
| VA | 형용사 | |
| VX | 보조 용언 | |
| VCP | 긍정 지시사(이다) | |
| VCN | 부정 지시사(아니다) | |
| 관형사 | MM | 관형사 |
| 부사(MA) | MAG | 일반 부사 |
| MAJ | 접속 부사 | |
| 감탄사 | IC | 감탄사 |
| 조사(J) | JKS | 주격 조사 |
| JKC | 보격 조사 | |
| JKG | 관형격 조사 | |
| JKO | 목적격 조사 | |
| JKB | 부사격 조사 | |
| JKV | 호격 조사 | |
| JKQ | 인용격 조사 | |
| JX | 보조사 | |
| JC | 접속 조사 | |
| 어미(E) | EP | 선어말 어미 |
| EF | 종결 어미 | |
| EC | 연결 어미 | |
| ETN | 명사형 전성 어미 | |
| ETM | 관형형 전성 어미 | |
| 접두사 | XPN | 체언 접두사 |
| 접미사(XS) | XSN | 명사 파생 접미사 |
| XSV | 동사 파생 접미사 | |
| XSA | 형용사 파생 접미사 | |
| XSM | 부사 파생 접미사* | |
| 어근 | XR | 어근 |
| 부호, 외국어, 특수문자(S) | SF | 종결 부호(. ! ?) |
| SP | 구분 부호(, / : ;) | |
| SS | 인용 부호 및 괄호(' " ( ) [ ] < > { } ― ‘ ’ “ ” ≪ ≫ 등) | |
| SSO | SS 중 여는 부호* | |
| SSC | SS 중 닫는 부호* | |
| SE | 줄임표(…) | |
| SO | 붙임표(- ~) | |
| SW | 기타 특수 문자 | |
| SL | 알파벳(A-Z a-z) | |
| SH | 한자 | |
| SN | 숫자(0-9) | |
| SB | 순서 있는 글머리(가. 나. 1. 2. 가) 나) 등)* | |
| 분석 불능 | UN | 분석 불능* |
| 웹(W) | W_URL | URL 주소* |
| W_EMAIL | 이메일 주소* | |
| W_HASHTAG | 해시태그(#abcd)* | |
| W_MENTION | 멘션(@abcd)* | |
| W_SERIAL | 일련번호(전화번호, 통장번호, IP주소 등)* | |
| W_EMOJI | 이모지* | |
| 기타 | Z_CODA | 덧붙은 받침* |
| Z_SIOT | 사이시옷* | |
| USER0~4 | 사용자 정의 태그* |
* 세종 품사 태그와 다른 독자적인 태그입니다.
0.12.0 버전부터 VV, VA, VX, XSA 태그에 불규칙 활용여부를 명시하는 접미사 -R와 -I이 덧붙을 수 있습니다.
-R은 규칙 활용, -I은 불규칙 활용을 나타냅니다.
| 모델(파일 크기) | 웹 | 정제된 웹 | 신문기사 | 문학작품 |
|---|---|---|---|---|
| 소형(15.9MB) | 86.85 | 93.58 | 89.73 | 95.19 |
| 중형(39.9MB) | 87.09 | 94.12 | 91.23 | 96.73 |
| 대형(90.4MB) | 86.99 | 93.47 | 92.37 | 97.68 |
결과 예시
프랑스의 세계적인 의상 디자이너 엠마누엘 웅가로가 실내 장식용 직물 디자이너로 나섰다.
(정답) 프랑스/NNP 의/JKG 세계/NNG 적/XSN 이/VCP ㄴ/ETM 의상/NNG 디자이너/NNG 엠마누엘/NNP 웅가로/NNP 가/JKS 실내/NNG 장식/NNG 용/XSN 직물/NNG 디자이너/NNG 로/JKB 나서/VV 었/EP 다/EF ./SF
(Kiwi) 프랑스/NNP 의/JKG 세계/NNG 적/XSN 이/VCP ᆫ/ETM 의상/NNG 디자이너/NNG 엠마누/NNP 에/JKB ᆯ/JKO 웅가로/NNP 가/JKS 실내/NNG 장식/NNG 용/XSN 직물/NNG 디자이너/NNG 로/JKB 나서/VV 었/EP 다/EF ./SF
둥글둥글한 돌은 아무리 굴러도 흔적이 남지 않습니다.
(정답) 둥글둥글/MAG 하/XSA ㄴ/ETM 돌/NNG 은/JX 아무리/MAG 구르/VV 어도/EC 흔적/NNG 이/JKS 남/VV 지/EC 않/VX 습니다/EF ./SF
(Kiwi) 둥글둥글/MAG 하/XSA ᆫ/ETM 돌/NNG 은/JX 아무리/MAG 구르/VV 어도/EC 흔적/NNG 이/JKS 남/VV 지/EC 않/VX 습니다/EF ./SF
하늘을 훨훨 나는 새처럼
(정답) 하늘/NNG 을/JKO 훨훨/MAG 날/VV 는/ETM 새/NNG 처럼/JKB
(Kiwi) 하늘/NNG 을/JKO 훨훨/MAG 날/VV 는/ETM 새/NNG 처럼/JKB
아버지가방에들어가신다
(정답) 아버지/NNG 가/JKS 방/NNG 에/JKB 들어가/VV 시/EP ㄴ다/EF
(Kiwi) 아버지/NNG 가/JKS 방/NNG 에/JKB 들어가/VV 시/EP ᆫ다/EC
https://lab.bab2min.pe.kr/kiwi 에서 데모를 실행해 볼 수 있습니다.
Kiwi는 LGPL v3 라이센스로 배포됩니다.
이메일: bab2min@gmail.com
블로그: http://bab2min.tistory.com/560
자세한 내용은 CONTRIBUTING.md 에서 확인해주세요.
DOI 혹은 아래의 BibTex를 이용해 인용해주세요.
@article{43508,
title = {Kiwi: 통계적 언어 모델과 Skip-Bigram을 이용한 한국어 형태소 분석기 구현},
journal = {디지털인문학},
volume = {1},
number = {1},
page = {109-136},
year = {2024},
issn = {3058-311X},
doi = {https://doi.org/10.23287/KJDH.2024.1.1.6},
url = {https://kjdh/v.1/1/109/43508},
author = {민철 이},
keywords = {한국어, 자연어처리, 형태소 분석기, 모호성 해소, 언어 모델},
abstract = {한국어 형태소 분석 시 모델이 마주하는 어려움 중 하나는 모호성이다. 이는 한국어에서 기저형이 전혀 다른 형태소 조합이 동일한 표면형을 가질 수 있기 때문에 발생하며 이를 바르게 분석하기 위해서는 문맥을 고려하는 능력이 모델에게 필수적이다. 형태소 분석기 Kiwi는 이를 해결하기 위해 근거리 맥락을 고려하는 통계적 언어 모델과 원거리 맥락을 고려하는 Skip-Bigram 모델을 조합하는 방식을 제안한다. 제안된 방식은 모호성 해소에서 평균 정확도 86.7%를 달성하여 평균 50~70%에 머무르는 기존의 오픈소스 형태소 분석기, 특히 딥러닝 기반의 분석기들보다도 앞서는 결과를 보였다. 또한 최적화된 경량 모델을 사용한 덕분에 타 분석기보다 빠른 속도를 보여 대량의 텍스트를 분석하는 데에도 유용하게 쓰일 수 있다. 오픈소스로 공개된 Kiwi는 전술한 특징들 덕분에 텍스트 마이닝, 자연어처리, 인문학 등 다양한 분야에서 널리 사용되고 있다. 본 연구는 형태소 분석의 정확도와 효율성을 모두 개선했으나, 미등록어 처리와 한국어 방언 분석 등의 과제에서 한계를 보여 이에 대한 추가 보완이 필요하다.},
}
@article{43508,
title = {Kiwi: Developing a Korean Morphological Analyzer Based on Statistical Language Models and Skip-Bigram},
journal = {Korean Journal of Digital Humanities},
volume = {1},
number = {1},
page = {109-136},
year = {2024},
issn = {3058-311X},
doi = {https://doi.org/10.23287/KJDH.2024.1.1.6},
url = {https://kjdh/v.1/1/109/43508},
author = {Min-chul Lee},
keywords = {한국어, 자연어처리, 형태소 분석기, 모호성 해소, 언어 모델},
abstract = {One of the challenges faced by models in Korean morphological analysis is ambiguity. This arises because different combinations of morphemes with completely different base forms can share the same surface form in Korean, necessitating the model's ability to consider context for accurate analysis. The morphological analyzer Kiwi addresses this issue by proposing a combination of a statistical language model that considers local context and a Skip-Bigram model that considers global context. This proposed method achieved an average accuracy of 86.7% in resolving ambiguities, outperforming existing open-source morphological analyzers, particularly deep learning-based ones, which typically achieve between 50-70%. Additionally, thanks to the optimized lightweight model, Kiwi shows faster speeds compared to other analyzers, making it useful for analyzing large volumes of text. Kiwi, released as open source, is widely used in various fields such as text mining, natural language processing, and the humanities due to these features. Although this study improved both the accuracy and efficiency of morphological analysis, it shows limitations in handling out-of-vocabulary problem and analyzing Korean dialects, necessitating further improvements in these areas.},
}