{kind=link}
{kind=link}

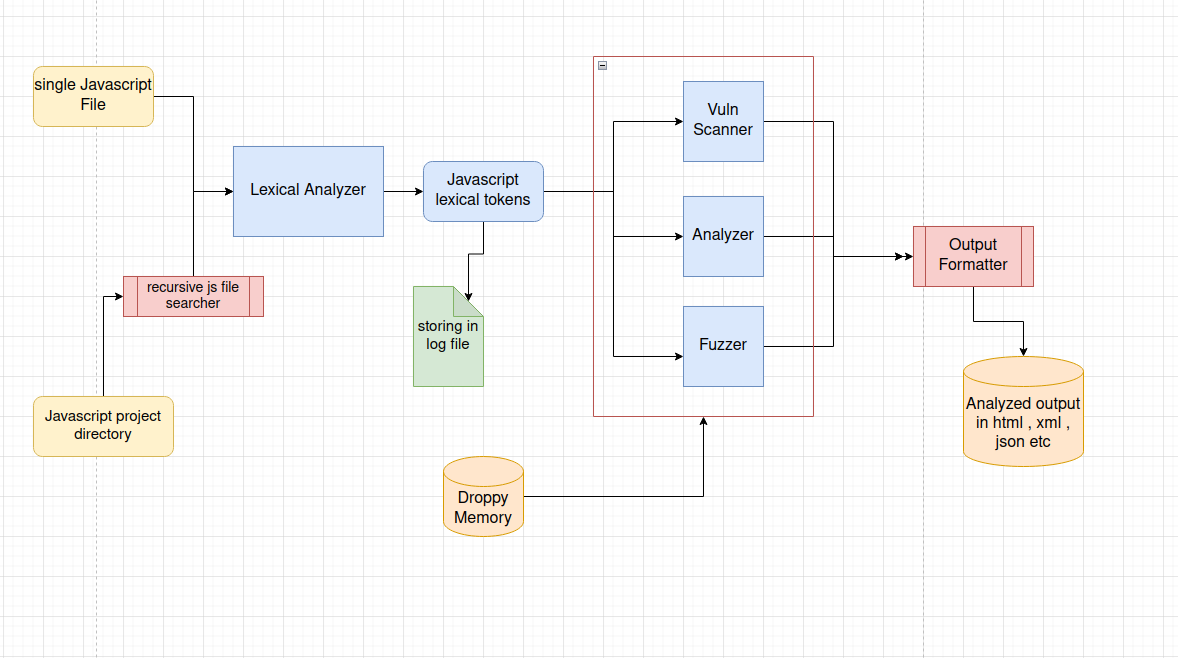
A tokenizer class is completely build from scratch for javascript . Lexical analysis is done by this class , by iterateting over each character by character . Each token is lexically analyzed and convert into a token object which have attributes like type , value , line number and number . These tokens are then used for fuzzing and analyzing the code with its attribute in the Tokenizer class . Scanner : Three types of scanner are used for analyzing the tokens produced by the tokenizer class
- Fuzzer
- Vuln Scanner
- Analyzer Vuln Scanner : The scanner fuzz for the presence of any obsolete function is present in the list of tokens . The Security Scanner searches for possible sources and sinks functions which can lead to security issues , if user input is not sanitized properly .
The analyze parse the javascript lex token and find if there are any statically evaluation conditions in it , which is unnecessary code in the codebase of any project . Then it also finds dead code , dead code is a section in the source code of a program which is executed but whose result is never used in any other computation. The execution of dead code wastes computation time and memory.
The fuzzer fuzzes the code for any log statements , comments which is not good for production-ready code . It also try to find the number of function , constants and variables present in the code . The arguments passed to the functions also parsed by the fuzzer for the final overview of the project
Logger is a module for logging various output of the different scanners in different formats like html , csv etc . The user can also increase the verbosity level of the tool for more info . It can also be used to analyze the performance measure of various function in the code analyzer .
Droopy brain is kind of fuel for the scanner module to scan the tokens . It includes various deprecated features list , sink and sources list for the javascript language .