Speech-to-Text-WaveNet : End-to-end sentence level English speech recognition using DeepMind's WaveNet
A tensorflow implementation of speech recognition based on DeepMind's WaveNet: A Generative Model for Raw Audio. (Hereafter the Paper)
Although ibab and tomlepaine have already implemented WaveNet with tensorflow, they did not implement speech recognition. That's why we decided to implement it ourselves.
Some of Deepmind's recent papers are tricky to reproduce. The Paper also omitted specific details about the implementation, and we had to fill the gaps in our own way.
Here are a few important notes.
First, while the Paper used the TIMIT dataset for the speech recognition experiment, we used the free VTCK dataset.
Second, the Paper added a mean-pooling layer after the dilated convolution layer for down-sampling. We extracted MFCC from wav files and removed the final mean-pooling layer because the original setting was impossible to run on our TitanX GPU.
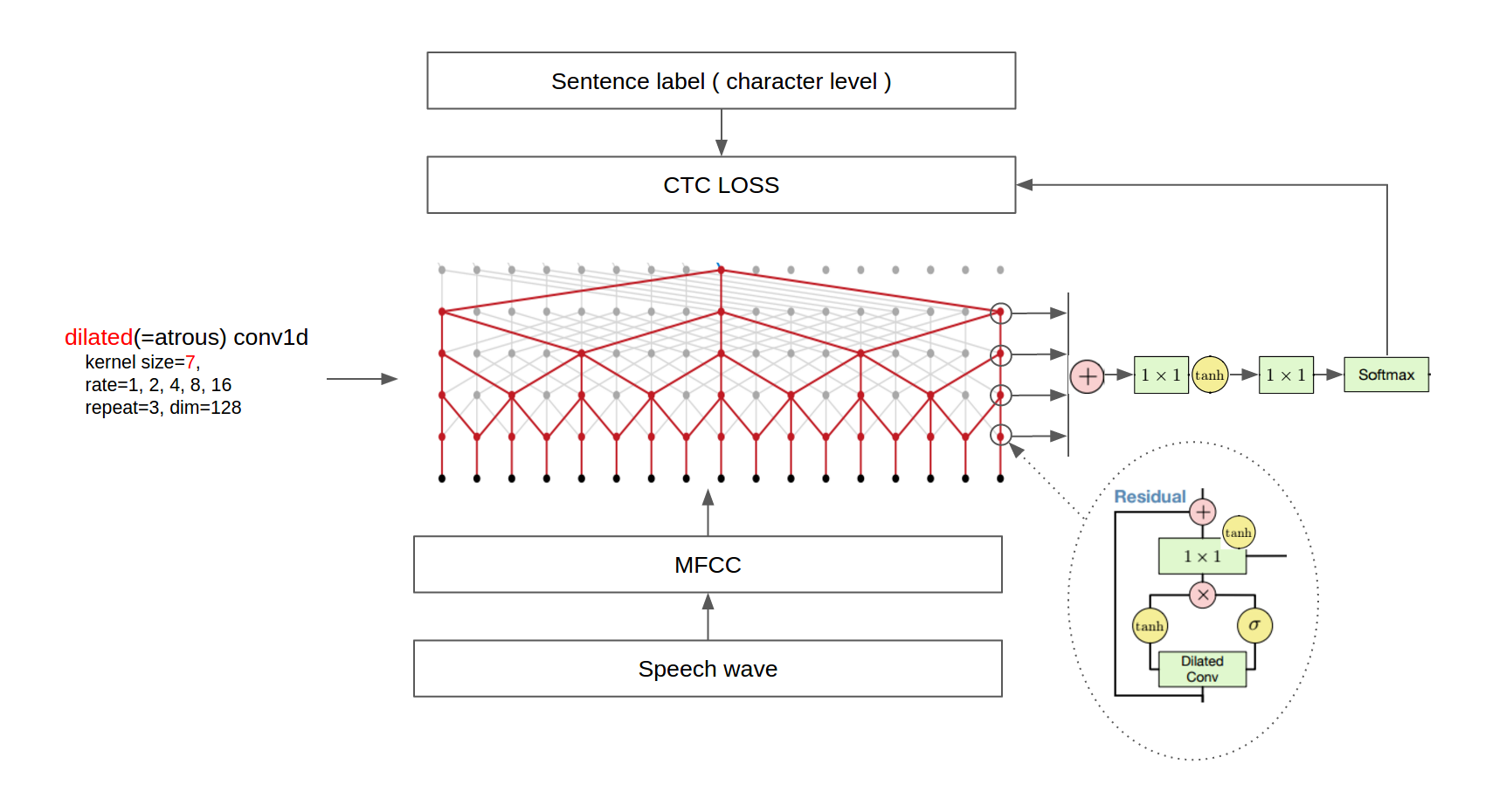
Third, since the TIMIT dataset has phoneme labels, the Paper trained the model with two loss terms, phoneme classification and next phoneme prediction. We, instead, used a single CTC loss because VCTK provides sentence-level labels. As a result, we used only dilated conv1d layers without any dilated conv1d layers.
Finally, we didn't do quantitative analyses such as BLEU score and post-processing by combining a language model due to the time constraints.
The final architecture is shown in the following figure.
Current Version : 0.0.0.2
- tensorflow == 1.0.0
- sugartensor == 1.0.0.2
- pandas >= 0.19.2
- librosa == 0.5.0
- scikits.audiolab==0.11.0
If you have problems with the librosa library, try to install ffmpeg by the following command. ( Ubuntu 14.04 )
sudo add-apt-repository ppa:mc3man/trusty-media
sudo apt-get update
sudo apt-get dist-upgrade -y
sudo apt-get -y install ffmpeg
We used VCTK, LibriSpeech and TEDLIUM release 2 corpus. Total number of sentences in the training set composed of the above three corpus is 240,612. Valid and test set is built using only LibriSpeech and TEDLIUM corpuse, because VCTK corpus does not have valid and test set. After downloading the each corpus, extract them in the 'asset/data/VCTK-Corpus', 'asset/data/LibriSpeech' and 'asset/data/TEDLIUM_release2' directories.
Audio was augmented by the scheme in the Tom Ko et al's paper. (Thanks @migvel for your kind information)
The TEDLIUM release 2 dataset provides audio data in the SPH format, so we should convert them to some format librosa library can handle. Run the following command in the 'asset/data' directory convert SPH to wave format.
find -type f -name '*.sph' | awk '{printf "sox -t sph %s -b 16 -t wav %s\n", $0, $0".wav" }' | bash
If you don't have installed sox, please installed it first.
sudo apt-get install sox
We found the main bottle neck is disk read time when training, so we decide to pre-process the whole audio data into
the MFCC feature files which is much smaller. And we highly recommend using SSD instead of hard drive.
Run the following command in the console to pre-process whole dataset.
python preprocess.py
Execute
python train.py ( <== Use all available GPUs )
or
CUDA_VISIBLE_DEVICES=0,1 python train.py ( <== Use only GPU 0, 1 )
to train the network. You can see the result ckpt files and log files in the 'asset/train' directory. Launch tensorboard --logdir asset/train/log to monitor training process.
We've trained this model on a 3 Nvidia 1080 Pascal GPUs during 40 hours until 50 epochs and we picked the epoch when the validatation loss is minimum. In our case, it is epoch 40. If you face the out of memory error, reduce batch_size in the train.py file from 16 to 4.
The CTC losses at each epoch are as following table:
| epoch | train set | valid set | test set |
|---|---|---|---|
| 20 | 79.541500 | 73.645237 | 83.607269 |
| 30 | 72.884180 | 69.738348 | 80.145867 |
| 40 | 69.948266 | 66.834316 | 77.316114 |
| 50 | 69.127240 | 67.639895 | 77.866674 |
After training finished, you can check valid or test set CTC loss by the following command.
python test.py --set train|valid|test --frac 1.0(0.01~1.0)
The frac option will be useful if you want to test only the fraction of dataset for fast evaluation.
Execute
python recognize.py --file
to transform a speech wave file to the English sentence. The result will be printed on the console.
For example, try the following command.
python recognize.py --file asset/data/LibriSpeech/test-clean/1089/134686/1089-134686-0000.flac
python recognize.py --file asset/data/LibriSpeech/test-clean/1089/134686/1089-134686-0001.flac
python recognize.py --file asset/data/LibriSpeech/test-clean/1089/134686/1089-134686-0002.flac
python recognize.py --file asset/data/LibriSpeech/test-clean/1089/134686/1089-134686-0003.flac
python recognize.py --file asset/data/LibriSpeech/test-clean/1089/134686/1089-134686-0004.flac
The result will be as follows:
he hoped there would be stoo for dinner turnips and charrats and bruzed patatos and fat mutton pieces to be ladled out in th thick peppered flower fatan sauce
stuffid into you his belly counsiled him
after early night fall the yetl lampse woich light hop here and there on the squalled quarter of the browfles
o berty and he god in your mind
numbrt tan fresh nalli is waiting on nou cold nit husband
The ground truth is as follows:
HE HOPED THERE WOULD BE STEW FOR DINNER TURNIPS AND CARROTS AND BRUISED POTATOES AND FAT MUTTON PIECES TO BE LADLED OUT IN THICK PEPPERED FLOUR FATTENED SAUCE
STUFF IT INTO YOU HIS BELLY COUNSELLED HIM
AFTER EARLY NIGHTFALL THE YELLOW LAMPS WOULD LIGHT UP HERE AND THERE THE SQUALID QUARTER OF THE BROTHELS
HELLO BERTIE ANY GOOD IN YOUR MIND
NUMBER TEN FRESH NELLY IS WAITING ON YOU GOOD NIGHT HUSBAND
As mentioned earlier, there is no language model, so there are some cases where capital letters, punctuations, and words are misspelled.
You can transform a speech wave file to English text with the pre-trained model on the VCTK corpus. Extract the following zip file to the 'asset/train/' directory.
See docker README.md.
- Language Model
- Polyglot(Multi-lingual) Model
We think that we should replace CTC beam decoder with a practical language model
and the polyglot speech recognition model will be a good candidate to future works.
- ibab's WaveNet(speech synthesis) tensorflow implementation
- tomlepaine's Fast WaveNet(speech synthesis) tensorflow implementation
- SugarTensor
- EBGAN tensorflow implementation
- Timeseries gan tensorflow implementation
- Supervised InfoGAN tensorflow implementation
- AC-GAN tensorflow implementation
- SRGAN tensorflow implementation
- ByteNet-Fast Neural Machine Translation
If you find this code useful please cite us in your work:
Kim and Park. Speech-to-Text-WaveNet. 2016. GitHub repository. https://github.com/buriburisuri/.
Namju Kim (namju.kim@kakaocorp.com) at KakaoBrain Corp.
Kyubyong Park (kbpark@jamonglab.com) at KakaoBrain Corp.