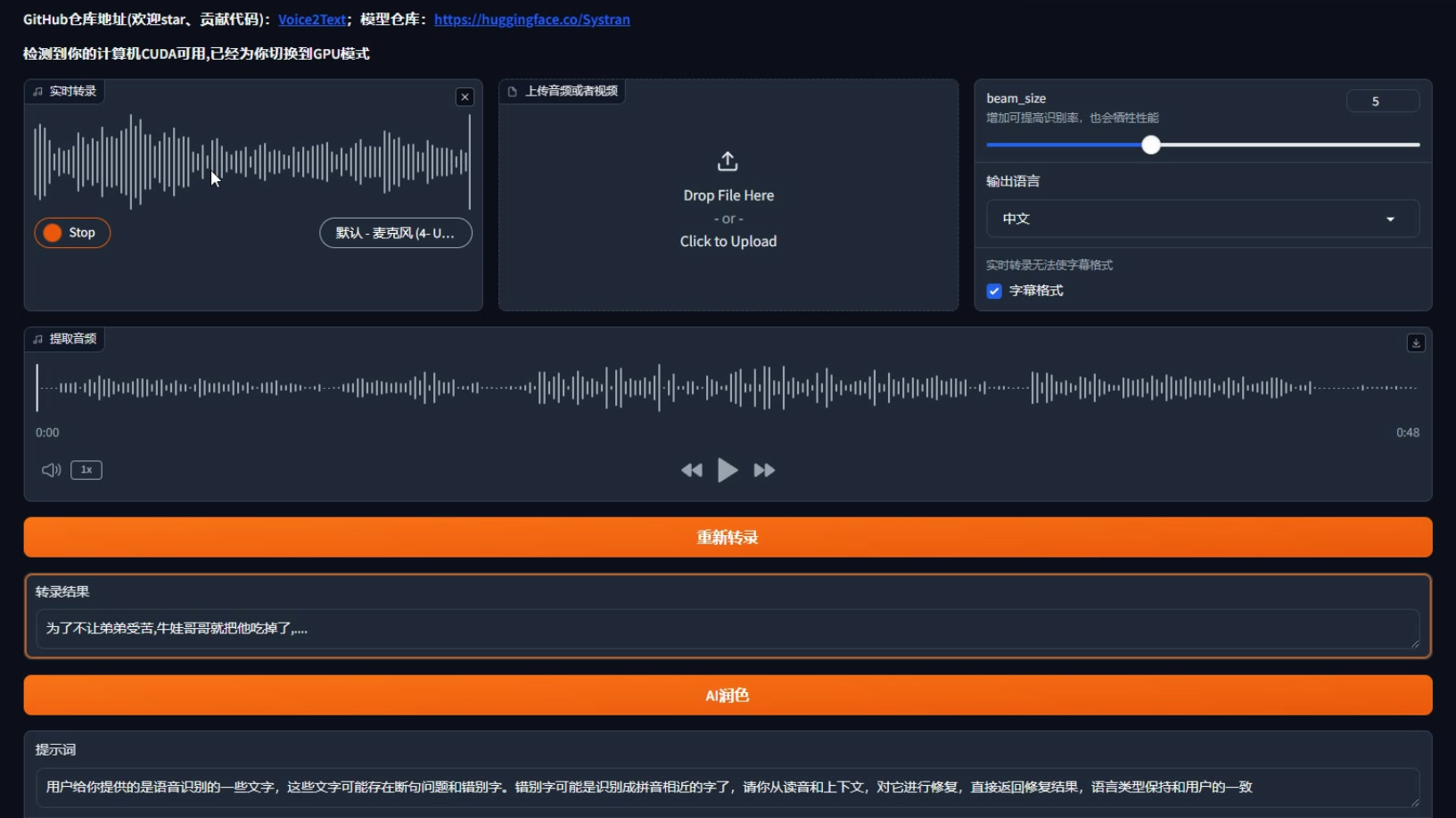
- 下载整合包Voice2Text-pkg.rar,然后解压
- 去 模型仓库 下载 faster-whisper-large-v2 模型放到models文件夹中
- windows 双击run.bat linux/mac 双击run.sh 运行
- 要使用GPU的自己下载安装CUDA12(方法二也一样)
1.拉取代码
git clone https://github.com/caiwuu/Voice2Text
cd ./Voice2Text
2.创建python虚拟环境
conda create -p ./env python==3.11.9
conda activate ./env
3.安装依赖
pip install -r requirements.txt
4.下载模型到models文件中,模型仓库:https://huggingface.co/Systran,默认使用 faster-whisper-large-v2,其他模型自己代码里改下模型名称
5.启动
python webUI.py