Overview
原文
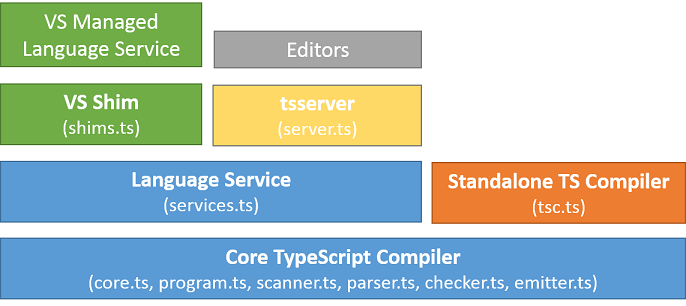
Parser: Starting from a set of sources, and following the productions of the language grammar, to generate an Abstract Syntax Tree (AST) Binder: Linking declarations contributing to the same structure using a Symbol (e.g. different declarations of the same interface or module, or a function and a module with the same name). This allows the type system to reason about these named declarations.Type resolver/ Checker: Resolving types of each construct, checking semantic operations and generate diagnostics as appropriate.
Emitter: Output generated from a set of inputs (.ts and .d.ts) files can be one of: JavaScript (.js), definitions (.d.ts), or source maps (.js.map)
Pre-processor: The "Compilation Context" refers to all files involved in a "program". The context is created by inspecting all files passed in to the compiler on the command line, in order, and then adding any files they may reference directly or indirectly through import statements and /// tags. The result of walking the reference graph is an ordered list of source files, that constitute the program. When resolving imports, preference is given to ".ts" files over ".d.ts" files to ensure the most up-to-date files are processed. The compiler does a node-like process to resolve imports by walking up the directory chain to find a source file with a .ts or .d.ts extension matching the requested import. Failed import resolution does not result in an error, as an ambient module could be already declared.
Standalone compiler (tsc): The batch compilation CLI. Mainly handle reading and writing files for different supported engines (e.g. Node.js)
Language Service: The "Language Service" exposes an additional layer around the core compiler pipeline that are best suiting editor-like applications. The language service supports the common set of a typical editor operations like statement completions, signature help, code formatting and outlining, colorization, etc... Basic re-factoring like rename, Debugging interface helpers like validating breakpoints as well as TypeScript-specific features like support of incremental compilation (--watch equivalent on the command-line). The language service is designed to efficiently handle scenarios with files changing over time within a long-lived compilation context; in that sense, the language service provides a slightly different perspective about working with programs and source files from that of the other compiler interfaces.
Please refer to the Using the Language Service API page for more details.
Standalone Server (tsserver): The tsserver wraps the compiler and services layer, and exposes them through a JSON protocol. Please refer to the Standalone Server (tsserver) for more details.
-
Parser: 获取sources, 遵从语言语法, 生成抽象语法树 (AST)
-
Binder: 使用Symbol链接有关联的声明到同一结构 (e.g. 同一接口或模块的不同声明, 或者有同一名字的函数和模块). 这使得类型系统可以对这些命名声明进行推断.
-
Type resolver/ Checker: 解析每个构造(construct)的类型, 检查语义操作并生成适当的诊断程序.
-
Emitter: 从一组输入文件(.ts和.d.ts)生成的输出可以是以下之一: JavaScript(.js),定义(.d.ts)或源映射(.js.map).
-
Pre-processor: “编译上下文”(Compilation Context)是指“程序”("program")中涉及的所有文件. 通过按顺序检查在命令行中传递给编译器的所有文件, 然后添加使用import语句和/// 标记直接或间接引用的所有文件, 来创建上下文. 遍历参考图(the reference graph)的结果是构成程序的源文件的有序列表. 解决导入时,优先处理“.ts”文件而不是“.d.ts”文件,以确保处理的是最新文件. 编译器执行类似节点的过程来解析导入, 其方法是在目录链中向上查找(walking up the directory chain)以扩展名为.ts或.d.ts的源文件来匹配请求的导入. 导入解析失败不会导致错误,因为可能已经声明了环境模块(ambient module).
-
Standalone compiler (tsc): 批处理编译CLI. 主要处理读取和写入文件, 以支持不同的引擎(例如Node.js).
-
Language Service: 其在核心编译器的管道周围公开了一个附加层,该层用于编辑器类应用程序. 语言服务支持一组常见的典型编辑器操作,如语句补全、帮助签名(signature help)、代码格式化和大纲(outlining)、着色、基本的重构(如重命名), 调试接口助手(如验证断点)以及TypeScript特有的功能(如支持增量编译)(相当于命令行上的--watch)等... 其旨在高效地处理在长期编译中随时可能发生上下文变化的源文件; 从这层意义上说, Language Service在处理程序和源文件方面提供了一个与其他编译器接口稍有些不同的视角(slightly different perspective).
更多有关信息,请参阅: Using the Language Service API
- Standalone Server (tsserver): tsserver包装了编译器层和服务层, 并通过简要的JSON协议公开了它们.
更多有关信息,请参阅: Standalone Server (tsserver)
原文
Node: The basic building block of the Abstract Syntax Tree (AST). In general node represent non-terminals in the language grammar; some terminals are kept in the tree such as identifiers and literals.SourceFile: The AST of a given source file. A SourceFile is itself a Node; it provides an additional set of interfaces to access the raw text of the file, references in the file, the list of identifiers in the file, and mapping from a position in the file to a line and character numbers.
Program: A collection of SourceFiles and a set of compilation options that represent a compilation unit. The program is the main entry point to the type system and code generation.
Symbol: A named declaration. Symbols are created as a result of binding. Symbols connect declaration nodes in the tree to other declarations contributing to the same entity. Symbols are the basic building block of the semantic system.
Type: Types are the other part of the semantic system. Types can be named (e.g. classes and interfaces), or anonymous (e.g. object types).
Signature: There are three types of signatures in the language: call, construct and index signatures.
-
Node: 抽象语法树(AST)的基本组件. 一般而言, Node代表语言语法中的非终结符; 一些终结符保存在树中, 例如标识符和常量(identifiers and literals).
-
SourceFile: 给定源文件的AST. SourceFile本身就是一个节点; 它提供了一组额外的接口来访问文件的原始文本、文件中的引用、文件中的标识符列表以及从文件中的位置到行和字符号(line and character numbers)的映射.
-
Program: SourceFiles和一组表示编译单元的编译选项的集合. 该Program是类型系统和代码生成的主要入口.
-
Symbol: 一个命名了的声明. Symbols作为绑定的结果(a result of binding)而创建. Simbols将树中声明的节点连接到对同一实体有贡献的其他声明. Symbols是语义系统的基本组成部分.
-
Type: Types是语义系统的另一部分. Types可以被命名(如类和接口), 也可以匿名(例如 对象类型).
-
Signature: 该语言有三种类型的签名: 调用(call), 构造(construct)和索引(index)签名.
原文
The process starts with preprocessing. The preprocessor figures out what files should be included in the compilation by following references (/// tags and import statements).The parser then generates AST Nodes. These are just an abstract representation of the user input in a tree format. A SourceFile object represents an AST for a given file with some additional information like the file name and source text.
The binder then passes over the AST nodes and generates and binds Symbols. One Symbol is created for each named entity. There is a subtle distinction but several declaration nodes can name the same entity. That means that sometimes different Nodes will have the same Symbol, and each Symbol keeps track of its declaration Nodes. For example, a class and a namespace with the same name can merge and will have the same Symbol. The binder also handles scopes and makes sure that each Symbol is created in the correct enclosing scope.
Generating a SourceFile (along with its Symbols) is done through calling the createSourceFile API.
So far, Symbols represent named entities as seen within a single file, but several declarations can merge multiple files, so the next step is to build a global view of all files in the compilation by building a Program.
A Program is a collection of SourceFiles and a set of CompilerOptions. A Program is created by calling the createProgram API.
From a Program instance a TypeChecker can be created. TypeChecker is the core of the TypeScript type system. It is the part responsible for figuring out relationships between Symbols from different files, assigning Types to Symbols, and generating any semantic Diagnostics (i.e. errors).
The first thing a TypeChecker will do is to consolidate all the Symbols from different SourceFiles into a single view, and build a single Symbol Table by "merging" any common Symbols (e.g. namespaces spanning multiple files).
After initializing the original state, the TypeChecker is ready to answer any questions about the program. Such "questions" might be:
What is the Symbol for this Node? What is the Type of this Symbol? What Symbols are visible in this portion of the AST? What are the available Signatures for a function declaration? What errors should be reported for a file? The TypeChecker computes everything lazily; it only "resolves" the necessary information to answer a question. The checker will only examine Nodes/Symbols/Types that contribute to the question at hand and will not attempt to examine additional entities.
An Emitter can also be created from a given Program. The Emitter is responsible for generating the desired output for a given SourceFile; this includes .js, .jsx, .d.ts, and .js.map outputs.
然后解析器生成AST节点. 其只是用户输入后生成的树的抽象表示. SourceFile对象代表给定文件的AST, 其中包含一些其他信息, 如文件名和源文本.
然后绑定器(binder)传递AST节点并生成并绑定Symbols(每一个命名的实体都将创建一个Symbol). 虽然有细微的区别, 但是几个声明节点可以命名(can name)同一个实体. 这意味着有时不同的Nodes将具有相同的Symbol, 并且每个Symbol都会跟踪其声明的Nodes. 例如, 具有相同名称的类和名称空间可以被合并, 并将具有相同的Symbol. 绑定器还处理作用域, 确保每个Symbol在正确的作用域内被创建.
通过调用createSourceFile API来生成每一个SourceFile(及其Symbols).
到目前为止, Symbols代表在单个文件中看得到的命名实体, 但是几个声明可以合并多个文件, 因此下一步是通过构建Program来构建一个编译时的所有文件的全局视图.
Program是SourceFiles和一组CompilerOptions的集合. 其通过调用createProgram API来创建.
从Program实例可以创建一个TypeChecker. TypeChecker是TypeScript类型系统的核心. 它负责确定不同文件中Symbols的关系, 且为Symbols分配类型以及生成语义诊断(如错误).
TypeChecker要做的第一件事情是将来自不同SourceFiles的所有Symbol合并到同一个view中, 并通过“合并”一些常见Symbol(例如, 一个跨越多个文件的名称空间)来构建单个的Symbol表.
初始化完状态后, TypeChecker将准备回答有关程序的所有"问题". "问题"有可能会是:
- 该Node的Symbol是什么?
- 该Symbol的类型是什么?
- 哪些Symbols在AST的此部分中可见?
- 函数声明的可用签名是什么?
- 应该报告该文件的哪些错误?
TypeChecker是延迟计算(computes lazily)的; 它仅“解析”(resolve)必要的信息以回答上述问题. 检查器将仅检查有助于解决当前问题的Nodes/Symbols/Types, 而不会尝试检查其他实体.
也可以从给定的Program创建Emitter. Emitter负责为给定的SourceFile生成所需的输出, 包括.js, .jsx, .d.ts和.js.map输出.
原文
Full Start/Token Start Tokens themselves have what we call a "full start" and a "token start". The "token start" is the more natural version, which is the position in the file where the text of a token begins. The "full start" is the point at which the scanner began scanning since the last significant token. When concerned with trivia, we are often more concerned with the full start.Function Description ts.Node.getStart Gets the position in text where the first token of a node started. ts.Node.getFullStart Gets the position of the "full start" of the first token owned by the node.
Trivia
Syntax trivia represent the parts of the source text that are largely insignificant for normal understanding of the code, such as whitespace, comments, and even conflict markers.
Because trivia are not part of the normal language syntax (barring ECMAScript ASI rules) and can appear anywhere between any two tokens, they are not included in the syntax tree. Yet, because they are important when implementing a feature like refactoring and to maintain full fidelity with the source text, they are still accessible through our APIs on demand.
Because the EndOfFileToken can have nothing following it (neither token nor trivia), all trivia naturally precedes some non-trivia token, and resides between that token's "full start" and the "token start"
It is a convenient notion to state that a comment "belongs" to a Node in a more natural manner though. For instance, it might be visually clear that the genie function declaration owns the last two comments in the following example:
var x = 10; // This is x.
/**
- Postcondition: Grants all three wishes. */ function genie([wish1, wish2, wish3]: [Wish, Wish, Wish]) { while (true) { } } // End function This is despite the fact that the function declaration's full start occurs directly after var x = 10;.
We follow Roslyn's notion of trivia ownership for comment ownership. In general, a token owns any trivia after it on the same line up to the next token. Any comment after that line is associated with the following token. The first token in the source file gets all the initial trivia, and the last sequence of trivia in the file is tacked onto the end-of-file token, which otherwise has zero width.
For most basic uses, comments are the "interesting" trivia. The comments that belong to a Node which can be fetched through the following functions:
Function Description ts.getLeadingCommentRanges Given the source text and position within that text, returns ranges of comments between the first line break following the given position and the token itself (probably most useful with ts.Node.getFullStart). ts.getTrailingCommentRanges Given the source text and position within that text, returns ranges of comments until the first line break following the given position (probably most useful with ts.Node.getEnd). As an example, imagine this portion of a source file:
debugger;/hello/
//bye
/hi/ function
The full start for the function keyword begins at the /hello/ comment, but getLeadingCommentRanges will only return the last 2 comments:
d e b u g g e r ; / * h e l l o * / _ _ _ _ _ [CR] [NL] _ _ _ _ / / b y e [CR] [NL] _ _ / * h i * / _ _ _ _ f u n c t i o n ↑ ↑ ↑ ↑ ↑ full start look for first comment second comment token start leading comments starting here Appropriately, calling getTrailingCommentRanges on the end of the debugger statement will extract the /hello/ comment.
In the event that you are concerned with richer information of the token stream, createScanner also has a skipTrivia flag which you can set to false, and use setText/setTextPos to scan at different points in a file.
Full Start/Token Start
Tokens本身具有我们所说的“full start”和“token start”. “token start”是更自然化的版本, 它是文件中令牌文本(text of token)开始的位置. 而“full start”是自上一个有效token以来扫描程序需要开始扫描的点(point at). 当涉及琐事(trivia)时, 我们通常更关心的是full start.
| Function | Description |
|---|---|
| ts.Node.getStart | Gets the position in text where the first token of a node started. |
| ts.Node.getFullStart | Gets the position of the "full start" of the first token owned by the node. |
Trivia
Syntax trivia表示源文本中对于正常理解代码来说不太重要的部分, 如空白、注释甚至冲突标记.
由于trivia不是常规语言语法的一部分(除ECMAScript ASI规则外), 并且可以出现在任何两个标记之间的任何位置, 因此它们并不包含在语法树中. 但是, 由于它们在实现诸如重构之类的功能并保持源文本的完全保真度时很重要, 因此仍然可以通过我们的API按需访问它们.
因为EndOfFileToken后面不能有任何内容(token和trivia都不能), 所以所有trivia自然都在某些非琐事令牌之前, 并且都位于该令牌的“full start”和“token start”之间.
不过,以更自然的方式声明trivia“属于”Node是一个方便的概念. 例如, 在下面的示例中, 从视觉上可以清楚地看出,函数genie的声明拥有最后两个注释:
var x = 10; // This is x.
/**
* Postcondition: Grants all three wishes.
*/
function genie([wish1, wish2, wish3]: [Wish, Wish, Wish]) {
while (true) {
}
} // End function尽管事实上函数声明的full start发生在var x = 10;之后.
我们遵循Roslyn关于trivia所有权的概念来处理comment的所有权. 通常, token拥有所有的在同一行之后直到下一个令牌前的trivia. 该行之后的任何注释都与以下token关联. 源文件中的第一个标记将获得所有开始的trivia, 文件中的最后一个trivia序列将附加到文件结束标记(end-of-file token)上, 否则它的宽度将为0.
对于大多数基本用途,注释是“有趣的”trivia. 可以通过以下函数获取属于节点的注释:
| Function | Description |
|---|---|
| ts.getLeadingCommentRanges | 给定源文本和该文本中的位置, 返回在给定位置之后的第一个换行符与token本身之间的所有注释(对于ts.Node.getFullStart可能最有用). |
| ts.getTrailingCommentRanges | 给定源文本和该文本中的位置, 返回直到在给定位置之后的第一行换行为止的所有注释(可能对ts.Node.getEnd最有用). |
例如, 想象一下源文件的这一部分:
debugger;/*hello*/
//bye
/*hi*/ functionfunction关键字的full start从/hello/注释开始, 但是getLeadingCommentRanges只返回最后两个注释:
d e b u g g e r ; / * h e l l o * / _ _ _ _ _ [CR] [NL] _ _ _ _ / / b y e [CR] [NL] _ _ / * h i * / _ _ _ _ f u n c t i o n
↑ ↑ ↑ ↑ ↑
full start look for first comment second comment token start
leading comments
starting here
相应地,在debugger语句的末尾调用getTrailingCommentRanges将提取到/hello/注释.
如果需要关注token stream的更多的信息, 那么createScanner还具有skipTrivia标志, 可以将其设置为false, 并使用setText/setTextPos来扫描文件中的不同的点.