Query about blank lines #159
Comments
|
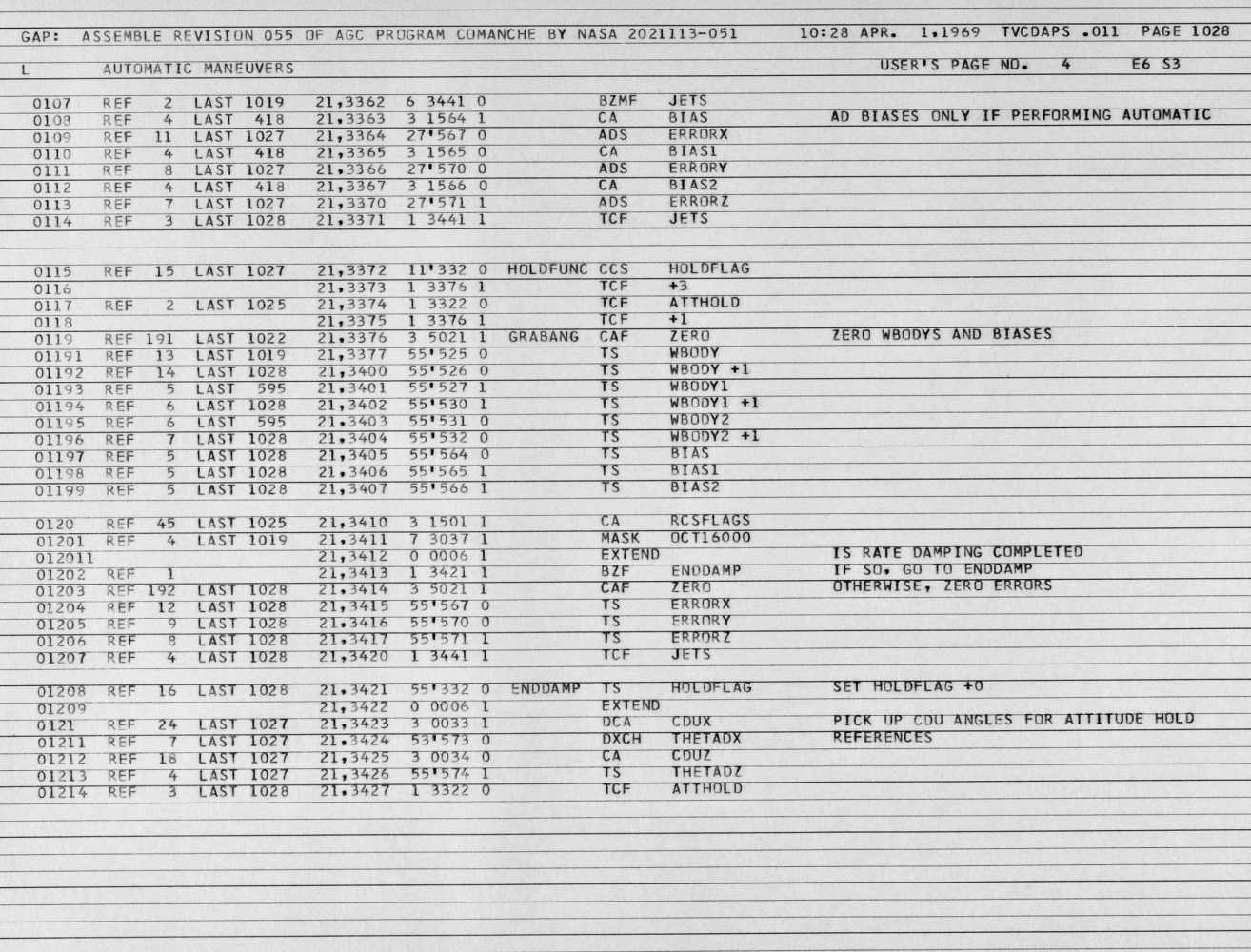
I believe that lines that do not have a corresponding line number are not part of the source code, so they should not be included. I think the final goal here is that every line number in a file corresponds to the line number in each page, so it's a 1:1 transcription. Of course though, we leave for last the actual removal of the page numbers from the code. |
|
Empty lines in the original should be empty lines here. Empty lines with a number at the beginning should be empty lines with a number at the beginning. The scans are the ground truth. This could be a bit of work. Lets use the broken windows theory and just make such fixes whenever we touch a file that happens to have this issue. Once we work our way through higher priority issues, we can focus on these. If we are at that point, then by all means. After a couple weeks, I am just now catching up on where we are at with everything. |
|
@oldmud0 @chrislgarry we'll never get a 1:1 transcription. The source code has multiple lines of code for some lines - i.e line 0119 has 01191 to 01199, then resumes with line 0120. Other pages have duplicated line numbers - where one has code and another is 'empty' {Page 1029](http://www.ibiblio.org/apollo/ScansForConversion/Comanche055/1029.jpg) I'm veering more to keeping the empty lines as they're shown in the source images - whether they have a line number or not, since the readability of the code gets pretty poor in some places - such as here
|




{kind=link}
{kind=link}
|
Hmm.. I guess it comes down to best judgment. |
|
Page 1028: I always assumed that these were cards that had been inserted into the source deck, and this numbering was used to avoid having to renumber subsequent cards, but I could be completely wrong about that. The images are scans of "listings" not source code, i.e. they are one of the outputs of the GAP cross-assembler (along with object code, etc). With respect to 2 lines with the same number, e.g. the page 1029 example above, the second page 0174 is not part of the source deck. The assembler is indicating that card 0174 in the source deck occupies 2 words in memory. Finally, with respect to the blank lines, I would keep them. Possibly the original source deck had linefeed cards that are not otherwise represented in the listing (we'll never know I guess), but it does look like the vertical spacing is intentional. |
|
From my standpoint, question like this revolve around /criteria/, and I As Jim also points out, the online page scans are not the original As I understand it, GAP didn't operate directly from the card decks. I Jim says we'll never know about the original intentions behind the blank -- Ron On 08/15/2016 04:18 AM, Jim Lawton wrote:
|
|
If these are just GAP printouts, then where is the original source code? |
|
It was originally on punch card decks, then at some point in 1965 or so, they moved it to magnetic tapes. The actual builds for the flights were done from those mag tape libraries. I guess those mag tapes were lost a long time ago. The printouts survived because people kept them as souvenirs. |
|
If you're responding to what Jim Lawton and I said, perhaps I wasn't The point I was trying to make, ineptly, is that the formatting you see -- Ron On 08/15/2016 09:52 AM, oldmud0 wrote:
|
|
The original programmers worked mostly with the GAP printouts. They only On Mon, Aug 15, 2016 at 9:12 AM, rburkey2005 notifications@github.com
|
|
My apologies: I should have refreshed my memory about the WAF thing I guess my imaginary picture of that auditorium remained in my mind long On 08/15/2016 11:52 PM, proudindiv wrote:
|
What I've been doing when cross-checking the files is: fixing typos in the comments, modifying the positioning of comments to better match what was shown in the images/GAP printouts - mainly just the paragraphs - and adding (or in the rare case removing) blank lines by however many were shown on the printouts.
My question was indeed a simple "should we keep then or not" in the original post, however since then and looking back other past files I've cross-checked I came to notice that the single lines were mostly used for general formatting and legibility - such as separating each label and their instructions (although this appears to be inconsistent), while the double/triple lines were mainly splitting different sections of the documentation up. Page 1263 of the Comanche055 is one of the better examples of this: http://www.ibiblio.org/apollo/ScansForConversion/Comanche055/1263.jpg. So my question is now: Was the formatting of the comments (with the multiple line breaks) the original intentions of the programmers who wrote the code, or formatting artifacts introduced in the keypunching process. As if it was intentional i'd rather these line breaks be restored. |
{kind=link}
|
I'll pass your question along to Hugh Blair-Smith. I have contact info It has been so many years now that I had actually forgotten why I wasn't On 08/16/2016 05:04 PM, James Harris wrote:
|
|
Okay, I think you'll be please with this. Here is Hugh's answer in -- Ron On 08/16/2016 05:04 PM, James Harris wrote:
|
|
Thanks, I was just thinking about suggesting something like that. I had On Tue, Aug 16, 2016 at 7:14 PM, rburkey2005 notifications@github.com
|
|
No, no formatting-related pseudo ops are supported by yaYUL. You have to realize that there's no manual describing any of that stuff, or even some very basic aspects of the syntax of the assembly language. (At least as far as I could find out at the time.) Nor did I have any AGC developers to ask about it until long afterward. So most of syntax was reverse engineered by me, and only to the extent of getting the correct binary produced in yaYUL, which was my be-all and end-all. And to this day there is still a way (the SBANK pseudo-op) in which yaYUL fails to comply, and needs extra SBANKs to be inserted manually. Sent on my Virgin Mobile Samsung Galaxy S® 5 -------- Original message -------- Thanks, I was just thinking about suggesting something like that. I had counted characters on a line and wondered about how the 81-120 positions were entered. Is there a reference for pseudo op codes, such as "END" for the end card of the deck, that affected the listing and operation of the assembler but didn't print in the listing? On Tue, Aug 16, 2016 at 7:14 PM, rburkey2005 notifications@github.com wrote:
— {"api_version":"1.0","publisher":{"api_key":"05dde50f1d1a384dd78767c55493e4bb","name":"GitHub"},"entity":{"external_key":"github/chrislgarry/Apollo-11","title":"chrislgarry/Apollo-11","subtitle":"GitHub repository","main_image_url":"https://cloud.githubusercontent.com/assets/143418/17495839/a5054eac-5d88-11e6-95fc-7290892c7bb5.png","avatar_image_url":"https://cloud.githubusercontent.com/assets/143418/15842166/7c72db34-2c0b-11e6-9aed-b52498112777.png","action":{"name":"Open in GitHub","url":"https://github.com/chrislgarry/Apollo-11"}},"updates":{"snippets":[{"icon":"PERSON","message":"@proudindiv in #159: Thanks, I was just thinking about suggesting something like that. I had\ncounted characters on a line and wondered about how the 81-120 positions\nwere entered. Is there a reference for pseudo op codes, such as "END" for\nthe end card of the deck, that affected the listing and operation of the\nassembler but didn't print in the listing?\n\nOn Tue, Aug 16, 2016 at 7:14 PM, rburkey2005 \u003cnotifications@github.com\u003e\nwrote:\n\n\u003e Okay, I think you'll be please with this. Here is Hugh's answer in\n\u003e full, and I will refrain from expressing further personal opinions on\n\u003e the topic. Needless to say, I suppose, the yaYUL assembler does not use\n\u003e the column 1 characters Hugh mentions, and does not attempt to duplicate\n\u003e any of this specific formatting, and instead applies a colorized syntax\n\u003e highlighting. Enjoy!\n\u003e\n\u003e One question is whether amanualpage break falls into your definition\n\u003e of "blank lines" in which case there could be any number of\n\u003e consecutive"blanklines" up to fifty-something for a very short\n\u003e page.I believe theonly way such page breaks were put in the code was\n\u003e to begin a remarks card with P instead of Rin column 1, thereby\n\u003e forcing it to be the first line on a new page.That certainly implied\n\u003e a fairly major change of topic. On the other hand, it appears this\n\u003e info isn'tentirelylost becausesomebody has put in what looks like a\n\u003e full set of page number indicators in the form/#//#//Page 1234/.They\n\u003e look as if they appear at the originalautomaticpage breaks in most\n\u003e cases (as they should dobecause the symbol table and other indexy\n\u003e things are keyed to page numbers), but for manual page breaks they\n\u003e seem to appear after the page-top remarks cardsand just ahead of the\n\u003e first non-remark code on that page.A (small) pity, that, since\n\u003e itwould have expressedthe purpose of the manual page breaksbetter if\n\u003e it had preceded the page-top remarks.But not a big thing.\n\u003e\n\u003e Within the code on a page, the blank lines were put in under control\n\u003e of an unprinted digit in card column8, between the card numberfield\n\u003e and the location field. A 2 there forced a double-space (1 blank\n\u003e line)after its card, a 3 there forceda triple-space (2 blank lines),\n\u003e and I'm pretty sure the values 4 through 8 were never used,\n\u003e thoughthey weredefinedand supported.Double-spacingseparated groups\n\u003e of assembler control commands from actual code-generating lines, or\n\u003e within codegenerally meant that the line above it (often a branch\n\u003e instruction) was not always followedat run timeby the line below it,\n\u003e and triple-spacing was generally a small change of topic, not big\n\u003e enoughto inducea manual page break.So yes, triple-spacing did mark\n\u003e differences in sections of code, but I don't see that much was lost\n\u003e by reducing them to double spacing.If your friends would like to\n\u003e restore the triple-spacings, they could(aside from peeking at sites\n\u003e with scanned hard-copy pages) limit their attention to blank lines\n\u003e that are preceded by a non-remark and followed by a remark\n\u003e line.Within that set, an educated guess as to where topic breaks\n\u003e occur will get pretty close.\n\u003e\n\u003e Having said all that, if you think there were any non-page-break\n\u003e cases with more than two consecutive blank lines, I like to hear\n\u003e about them.\n\u003e\n\u003e And yes, I am indeed the right fellow to ask. These minutiae were\n\u003e part of my determination to make the code easy to read.I can't think\n\u003e ofany reasons for blank lines beyondthose stated above, and I'd be\n\u003e pretty surprised if anybody else could.\n\u003e\n\u003e The reason for providing double-spacing and triple-spacing logic was\n\u003e to make it unnecessary to have physical blank cards in the decks,\n\u003e which were frequently pulled out, carriedto and from keypunches, and\n\u003e put back.A Steelcasefile drawerof 3000 punched cards was a heavy mutha.\n\u003e\n\u003e You can see evidence of the above in the fact that in the normal\n\u003e flow of card numbers, the one after such a spacing isgenerally1 more\n\u003e than that of the card before--no missing numbers due to spacing.But\n\u003e having said that, I have to explain why the card numberfollowing a\n\u003e remark over 72 columns wide is generally 2 more than the one you can\n\u003e see on the remark line. That's because the only way tomake such a\n\u003e remark was to have a second card, with a 9 in column 8, whose\n\u003e columns 9-48 were printed in print positions 81-120 of the previous\n\u003e line.That feature was called "right print."\n\u003e\n\u003e Hugh\n\u003e\n\u003e -- Ron\n\u003e\n\u003e\n\u003e On 08/16/2016 05:04 PM, James Harris wrote:\n\u003e \u003e\n\u003e \u003e As far as blank lines are concerned, I was happy with 1 line, for\n\u003e \u003e readability, but I had no interest in multiple blank lines in a\n\u003e \u003e row, and\n\u003e \u003e left them out. So by /my/ criteria, if you're working to cross-check\n\u003e \u003e yet once again the source code, as well as to correct the\n\u003e \u003e comments, and\n\u003e \u003e if it still assembles 100% byte-for-byte correctly, you're doing all I\n\u003e \u003e would have hoped for.\n\u003e \u003e\n\u003e \u003e What I've been doing when cross-checking the files is: fixing typos in\n\u003e \u003e the comments, modifying the positioning of comments to better match\n\u003e \u003e what was shown in the images/GAP printouts - mainly just the\n\u003e \u003e paragraphs - and adding (or in the rare case removing) blank lines by\n\u003e \u003e however many were shown on the printouts.\n\u003e \u003e\n\u003e \u003e Jim says we'll never know about the original intentions behind the\n\u003e \u003e blank\n\u003e \u003e lines, but we can probably find out if you're really excited to know.\n\u003e \u003e We can ask Hugh Blair-Smith, one of the original programmers, and the\n\u003e \u003e writer of GAP. I'll do that, if you like, but I'd like a fairly\n\u003e \u003e precisely-worded question before doing so. If the question just\n\u003e \u003e "should\n\u003e \u003e we keep them or not?", I don't think he'll have any more insight into\n\u003e \u003e the matter than I do ... but perhaps he would.\n\u003e \u003e\n\u003e \u003e My question was indeed a simple "should we keep then or not" in the\n\u003e \u003e original post, however since then and looking back other past files\n\u003e \u003e I've cross-checked I came to notice that the single lines were mostly\n\u003e \u003e used for general formatting and legibility - such as separating each\n\u003e \u003e label and their instructions (although this appears to be\n\u003e \u003e inconsistent), while the double/triple lines were mainly splitting\n\u003e \u003e different sections of the documentation up. Page 1263 of the\n\u003e \u003e Comanche055 is one of the better examples of this:\n\u003e \u003e http://www.ibiblio.org/apollo/ScansForConversion/Comanche055/1263.jpg.\n\u003e \u003e\n\u003e \u003e So my question is now: Was the formatting of the comments (with the\n\u003e \u003e multiple line breaks) the original intentions of the programmers who\n\u003e \u003e wrote the code, or formatting artifacts introduced in the keypunching\n\u003e \u003e process. As if it was intentional i'd rather these line breaks be\n\u003e \u003e restored.\n\u003e \u003e\n\u003e \u003e —\n\u003e \u003e You are receiving this because you were mentioned.\n\u003e \u003e Reply to this email directly, view it on GitHub\n\u003e \u003e \u003chttps://github.com/chrislgarry/Apollo-11/issues/\n\u003e 159#issuecomment-240253987\u003e,\n\u003e \u003e or mute the thread\n\u003e \u003e \u003chttps://github.com/notifications/unsubscribe-auth/\n\u003e ALSveAmA9nr0qUi4XJtQ2ZGfvFlw6ZWKks5qgjPegaJpZM4Jc9E6\u003e.\n\u003e \u003e\n\u003e\n\u003e —\n\u003e You are receiving this because you commented.\n\u003e Reply to this email directly, view it on GitHub\n\u003e \u003chttps://github.com//issues/159#issuecomment-240286839\u003e,\n\u003e or mute the thread\n\u003e \u003chttps://github.com/notifications/unsubscribe-auth/AG4k09UF6sXjyOMmRzaukejRuephEHk7ks5qgmB3gaJpZM4Jc9E6\u003e\n\u003e .\n\u003e\n"}],"action":{"name":"View Issue","url":"https://github.com/chrislgarry/Apollo-11/issues/159#issuecomment-240306164"}}} |
{kind=link}
{kind=link}
|
Actually, you did a great job and I'm very thankful I stumbled onto your I don't have too much at stake in the details of the formating. Your I'm about to start reverse engineering the algorithms used by the code. Gary Young On Wed, Aug 17, 2016 at 5:29 AM, rburkey2005 notifications@github.com
|
|
Too many email sigs. |
|
Thank you, and all my trusty minions thank you (I assume). :-) In return, it's nice to see some people interested enough once again to -- Ron On 08/17/2016 12:27 PM, proudindiv wrote:
|
|
@rburkey2005 Well if you need encouragement, we over at NASSP have been using your amazing work for years and are still working on landing it on the moon. We are very grateful we have the possibility to use the actual AGC code for our simulation. It's an immense challenge to make it work, but always very rewarding. I'm still hoping that one day Skylark and Luminary 1E become available. |
|
Unfortunately, nobody has ever given me the slightest hint of where -- Ron On 08/17/2016 12:56 PM, indy91 wrote:
|
|
@rburkey2005 thanks for digging into that for us. By chance you happened to be in contact with exactly the right person to ask. @wopian according to Hugh's response, any spacing with three consecutive blank lines or less that isn't a page break, let's make sure it conforms to what Hugh mentioned: double spaces seperate logical groups of assembly commands that together perform a specific function, and triple spaces separate these functional groups. Anything not following that heuristic should be suspect and we should correct it according to the heuristic (and apparently notify Hugh as well :)) |
After checking about 10% of the CONIC_SUBROUTINES.agc file, I've noticed that the digitisation is only using empty lines on lines marked as
R0000and ignores fully blank lines. However, outside of this file I've noticed in many places these fully empty lines have sometimes been included - the usage seems pretty inconsistent.Which would be best to make this as accurate to the source files as possible?
cc @chrislgarry @rburkey2005
Example (Page 1266
This page has a mixture of empty lines marked with
R0000and empty lines with no line number.The raw digitalised file has only used the
R0000empty lines (plus an erroneous blank line within the list)Vs. this version that includes the empty lines with no line number
The text was updated successfully, but these errors were encountered: