backfill: high latency when index backfill adds SSTs with large spans #36091
Description
We've been seeing significantly reduced throughput and increased latency for OLTP foreground traffic during index backfills in certain cases, as well as long running times for the index backfill itself.
This is related to what @awoods187 has also seen while testing with TPCC 1k (as reported in #34744), but this issue focuses on a workload specifically intended to demonstrate this behavior. It's possible that TPCC's variety and complexity in queries obscures some of the impact of a single index backfill.
I set up a roachtest to run the bulkingest workload on 4 nodes, which creates a table with 20 million rows with the table schema
CREATE TABLE bulkingest (
a INT,
b INT,
c INT,
payload BYTES,
PRIMARY KEY (a, b, c)
)
where a is populated with sequential values and payload is populated with random values. (To reproduce, run the test in master...lucy-zhang:repro, with the environment variable COCKROACH_IMPORT_WORKLOAD_FASTER set to true.). The test creates an index on (payload, a) and then on (a, payload), and issues updates to the table in parallel. The two backfills are visible below (and took 8min and 2min, respectively):
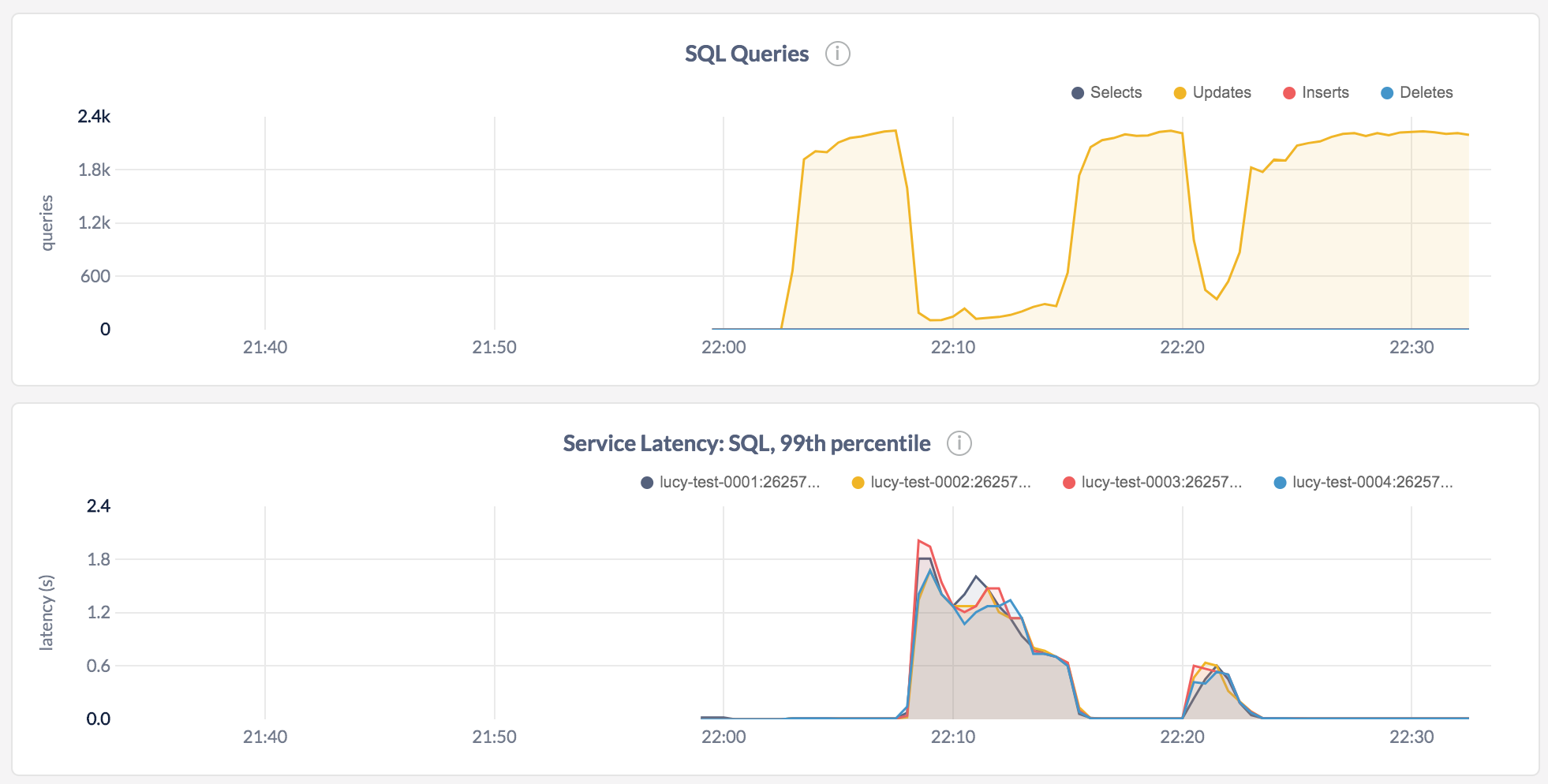
There are multiple issues here:
-
When an AddSSTable command is queued, all other writes to the same span will be blocked. When the index order is uncorrelated with the primary key order (since
payloadhas random values), the SSTs that are generated will cover very wide spans relative to the number of keys they contain, which is why adding the(payload, a)index is worse than adding the(a, payload)index.This is confirmed by logging the number of existing keys in the span in
EvalAddSSTable. For the(payload, a)index, the number of existing keys in each span is much higher. We add a lot of SSTs with only a few thousand keys that span an entire range that already contains 100,000s of keys.@dt has pointed out that this could be mitigated if we flushed an SST every time we detected a large gap in the index keys being written, to produce a larger number of denser SSTs.
-
When writing SSTs to nonempty ranges, repeatedly computing MVCC stats for the range is expensive, and we run into the known issue where a single node spends a lot of time computing stats while others node are blocked on AddSSTable calls (see storage/bulk: split and scatter during ingest #35016 (comment) and the accompanying PR).
I ran this test with batcheval: estimate stats in EvalAddSSTable #35231, which skips the stats recomputation in AddSSTable (and defers accurate stats recomputation to when ranges are split). This makes the first backfill much faster (from 8min to 4min), and I saw a similar 2x improvement when running a larger version of this test as well as the inverted index roachtest (which went from ~50 minutes to ~25 minutes).
The effect of the backfill on foreground traffic seems just as large (maybe larger?), but batcheval: estimate stats in EvalAddSSTable #35231 will still be an improvement if the total amount of time the backfill is holding up traffic goes down.
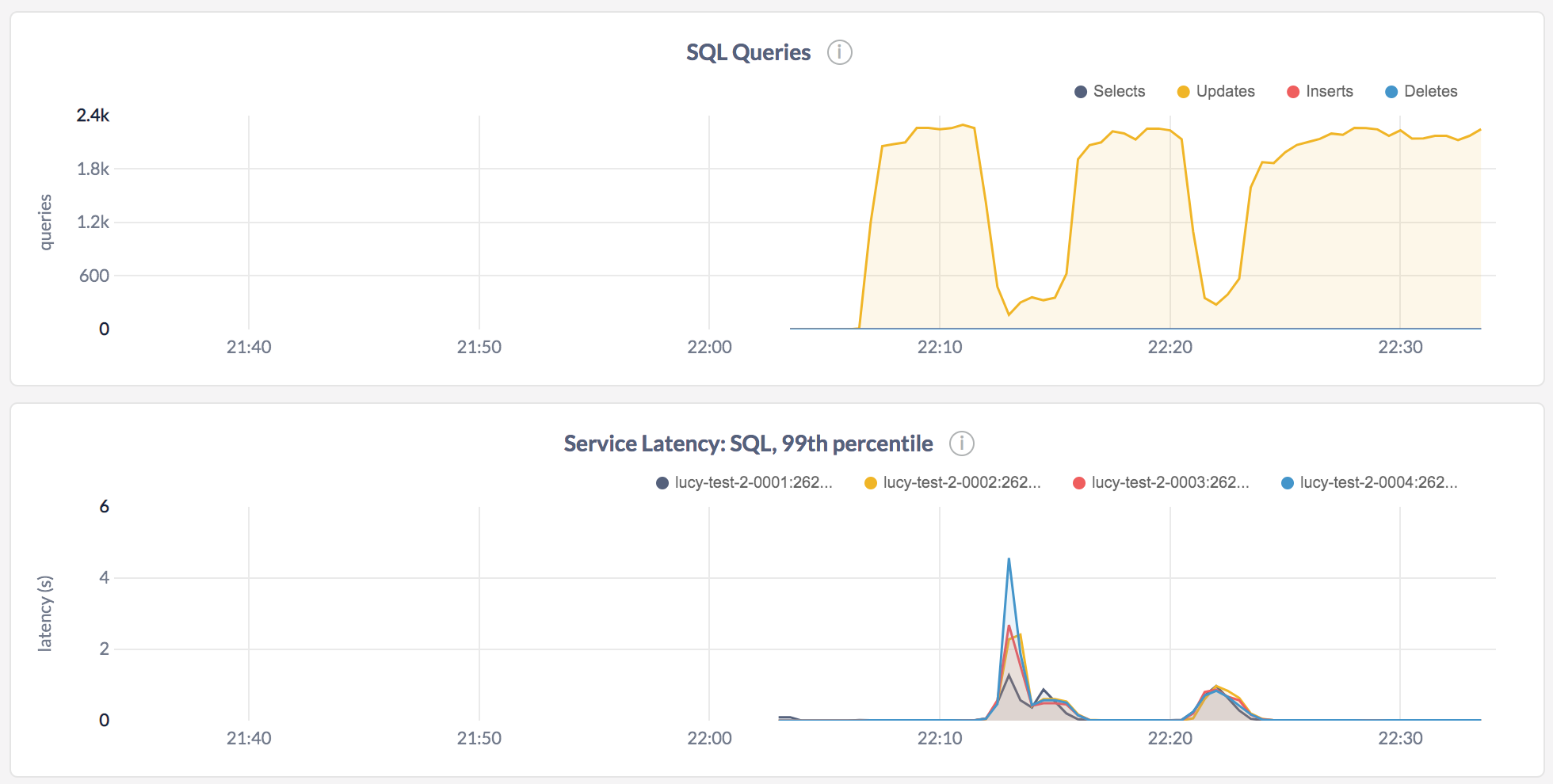
-
Even with the improvement offered by batcheval: estimate stats in EvalAddSSTable #35231 and on the "well-behaved" index on
(a, payload), the effect on foreground traffic is still significant, and I don't know of other reasons to pinpoint for this. Is this cluster underprovisioned?
Other notes:
- The inverted index roachtest, which also builds an index on a randomly generated payload, also consistently shows the severe drop in throughput for foreground traffic, and p99 latency increasing to 1s-10s.
- I tried running the test on @vivekmenezes's branch (WIP: sql: flush #35855) to store more KVs in memory before flushing SSTs and it didn't make an appreciable difference, at least for this workload.
Epic CRDB-8816
Jira issue: CRDB-4530