[TOC]
极客时间算法40讲中所出现的leetcode算法题
示例:
输入: 1->2->3->4->5->NULL
输出: 5->4->3->2->1->NULL
代码
递归
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) { val = x; }
* }
*/
class Solution {
public ListNode reverseList(ListNode head) {
if(head == null || head.next == null) return head;
ListNode node = reverseList(head.next);
head.next.next = head;
head.next = null;
return node;
}
}迭代
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) { val = x; }
* }
*/
class Solution {
public ListNode reverseList(ListNode head) {
ListNode prev = null;
while(head != null){
ListNode tmp = head.next;
head.next = prev;
prev = head;
head = tmp;
}
return prev;
}
}给定一个链表,两两交换其中相邻的节点,并返回交换后的链表。 你不能只是单纯的改变节点内部的值,而是需要实际的进行节点交换。
示例:
给定 1->2->3->4, 你应该返回 2->1->4->3.
代码
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) { val = x; }
* }
*/
class Solution {
public ListNode swapPairs(ListNode head) {
if(head == null || head.next == null) return head;
ListNode res = head.next;
ListNode pre = new ListNode(-1);
pre.next = head;
while(pre.next != null && pre.next.next != null){
ListNode a = pre.next;
ListNode b = a.next;
pre.next = b;
a.next = b.next;
b.next = a;
pre = a;
}
return res;
}
}给定一个链表,判断链表中是否有环。
为了表示给定链表中的环,我们使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。 如果 pos 是 -1,则在该链表中没有环。
示例 1:
输入:head = [3,2,0,-4], pos = 1
输出:true
解释:链表中有一个环,其尾部连接到第二个节点。

示例 2:
输入:head = [1,2], pos = 0
输出:true
解释:链表中有一个环,其尾部连接到第一个节点。

示例 3:
输入:head = [1], pos = -1
输出:false
解释:链表中没有环。

代码
双指针
/**
* Definition for singly-linked list.
* class ListNode {
* int val;
* ListNode next;
* ListNode(int x) {
* val = x;
* next = null;
* }
* }
*/
public class Solution {
public boolean hasCycle(ListNode head) {
if(head == null || head.next == null || head.next.next == null) return false;
ListNode slow = head;
ListNode fast = head;
while(fast != null && fast.next != null){
fast = fast.next.next;
slow = slow.next;
if(fast == slow){
return true;
}
}
return false;
}
}set检测重复
/**
* Definition for singly-linked list.
* class ListNode {
* int val;
* ListNode next;
* ListNode(int x) {
* val = x;
* next = null;
* }
* }
*/
public class Solution {
public boolean hasCycle(ListNode head) {
Set<ListNode> set = new HashSet<>();
while(head != null){
if(set.contains(head)) return true;
set.add(head);
head = head.next;
}
return false;
}
}给定一个链表,返回链表开始入环的第一个节点。 如果链表无环,则返回 null。
为了表示给定链表中的环,我们使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。 如果 pos 是 -1,则在该链表中没有环。
**说明:**不允许修改给定的链表。
示例 1:
输入:head = [3,2,0,-4], pos = 1
输出:tail connects to node index 1
解释:链表中有一个环,其尾部连接到第二个节点。

示例 2:
输入:head = [1,2], pos = 0
输出:tail connects to node index 0
解释:链表中有一个环,其尾部连接到第一个节点。

示例 3:
输出:no cycle
解释:链表中没有环。

代码
双指针
/**
* Definition for singly-linked list.
* class ListNode {
* int val;
* ListNode next;
* ListNode(int x) {
* val = x;
* next = null;
* }
* }
*/
public class Solution {
public ListNode detectCycle(ListNode head) {
boolean isCycle = false;
ListNode a = head;//慢指针
ListNode b = head;//快指针
while(b != null && b.next != null){
a = a.next;
b = b.next.next;
if(a == b){
isCycle = true;
break;
}
}
if(isCycle){
ListNode c = head;
while(c != a){
c = c.next;
a = a.next;
}
return a;
}else return null;
}
}set判断重复
/**
* Definition for singly-linked list.
* class ListNode {
* int val;
* ListNode next;
* ListNode(int x) {
* val = x;
* next = null;
* }
* }
*/
public class Solution {
public ListNode detectCycle(ListNode head) {
Set<ListNode> set = new HashSet<>();
while(head != null){
if(set.contains(head)) return head;
set.add(head);
head = head.next;
}
return null;
}
}给出一个链表,每 k 个节点一组进行翻转,并返回翻转后的链表。 k 是一个正整数,它的值小于或等于链表的长度。如果节点总数不是 k 的整数倍,那么将最后剩余节点保持原有顺序。
示例 :
给定这个链表:1->2->3->4->5
当 k = 2 时,应当返回: 2->1->4->3->5
当 k = 3 时,应当返回: 3->2->1->4->5
代码
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) { val = x; }
* }
*/
class Solution {
public ListNode reverseKGroup(ListNode head, int k) {
ListNode tmp = new ListNode(-1);
ListNode pre = tmp;
ListNode cur = pre;
tmp.next = head;
int num = 0;
while(cur != null){
cur = cur.next;
num ++;
}
while(num > k){
cur = pre.next;
for(int i = 1; i < k; i ++){
ListNode t = cur.next;
cur.next = t.next;
t.next = pre.next;
pre.next = t;
}
pre = cur;
num -= k;
}
return tmp.next;
}
}给定一个只包括 '(',')','{','}','[',']' 的字符串,判断字符串是否有效。
有效字符串需满足:
- 左括号必须用相同类型的右括号闭合。
- 左括号必须以正确的顺序闭合。
注意空字符串可被认为是有效字符串。
示例 1:
输入: "()"
输出: true
示例 2:
输入: "()[]{}"
输出: true
示例 3:
输入: "(]"
输出: false
示例 4:
输入: "([)]"
输出: false
示例 5:
输入: "{[]}"
输出: true
代码
class Solution {
public boolean isValid(String s) {
Map<Character, Character> map = new HashMap<>();
map.put(')', '(');
map.put('}', '{');
map.put(']', '[');
Stack<Character> stack = new Stack<>();
char[] arr = s.toCharArray();
for(char c : arr){
if(!map.containsKey(c)) stack.push(c);
else if(stack.isEmpty() || map.get(c) != stack.pop()) return false;
}
return stack.isEmpty();
}
}使用队列实现栈的下列操作:
- push(x) -- 元素 x 入栈
- pop() -- 移除栈顶元素
- top() -- 获取栈顶元素
- empty() -- 返回栈是否为空
代码
class MyStack {
Queue<Integer> q;
/** Initialize your data structure here. */
public MyStack() {
q = new LinkedList<>();
}
/** Push element x onto stack. */
public void push(int x) {
q.offer(x);
int n = q.size();
for(int i = 0; i < n - 1; i ++){
q.offer(q.poll());
}
}
/** Removes the element on top of the stack and returns that element. */
public int pop() {
return q.poll();
}
/** Get the top element. */
public int top() {
return q.peek();
}
/** Returns whether the stack is empty. */
public boolean empty() {
return q.isEmpty();
}
}使用栈实现队列的下列操作:
- push(x) -- 将一个元素放入队列的尾部。
- pop() -- 从队列首部移除元素。
- peek() -- 返回队列首部的元素。
- empty() -- 返回队列是否为空。
代码
class MyQueue {
Stack<Integer> s1, s2;
/** Initialize your data structure here. */
public MyQueue() {
s1 = new Stack<>();
s2 = new Stack<>();
}
/** Push element x to the back of queue. */
public void push(int x) {
s1.push(x);
}
/** Removes the element from in front of queue and returns that element. */
public int pop() {
if(!s2.isEmpty()) return s2.pop();
else{
while(!s1.isEmpty()){
s2.push(s1.pop());
}
return s2.pop();
}
}
/** Get the front element. */
public int peek() {
if(!s2.isEmpty()) return s2.peek();
else{
while(!s1.isEmpty()){
s2.push(s1.pop());
}
return s2.peek();
}
}
/** Returns whether the queue is empty. */
public boolean empty() {
return s1.isEmpty() && s2.isEmpty();
}
}设计一个找到数据流中第K大元素的类(class)。注意是排序后的第K大元素,不是第K个不同的元素。
你的 KthLargest 类需要一个同时接收整数 k 和整数数组nums 的构造器,它包含数据流中的初始元素。每次调用 KthLargest.add,返回当前数据流中第K大的元素。
示例:
int k = 3;
int[] arr = [4,5,8,2];
KthLargest kthLargest = new KthLargest(3, arr);
kthLargest.add(3); // returns 4
kthLargest.add(5); // returns 5
kthLargest.add(10); // returns 5
kthLargest.add(9); // returns 8
kthLargest.add(4); // returns 8
说明: 你可以假设 nums 的长度≥ k-1 且k ≥ 1。
代码
class KthLargest {
PriorityQueue<Integer> q;
int k;
public KthLargest(int k, int[] nums) {
this.k = k;
q = new PriorityQueue<>();
for(int i : nums) add(i);
}
public int add(int val) {
if(q.size() < k) q.offer(val);
else if(val > q.peek()){
q.poll();
q.offer(val);
}
return q.peek();
}
}给定一个数组 nums,有一个大小为 k 的滑动窗口从数组的最左侧移动到数组的最右侧。你只可以看到在滑动窗口 k 内的数字。滑动窗口每次只向右移动一位。
返回滑动窗口最大值。
示例:
输入: nums = [1,3,-1,-3,5,3,6,7], 和 k = 3
输出: [3,3,5,5,6,7]
解释:
滑动窗口的位置 最大值
--------------- -----
[1 3 -1] -3 5 3 6 7 3
1 [3 -1 -3] 5 3 6 7 3
1 3 [-1 -3 5] 3 6 7 5
1 3 -1 [-3 5 3] 6 7 5
1 3 -1 -3 [5 3 6] 7 6
1 3 -1 -3 5 [3 6 7] 7
注意:
你可以假设 k 总是有效的,1 ≤ k ≤ 输入数组的大小,且输入数组不为空。
代码
优先队列
class Solution {
public int[] maxSlidingWindow(int[] nums, int k) {
if(nums.length == 0) return new int[0];
int[] res = new int[nums.length - k + 1];
PriorityQueue<Integer> q = new PriorityQueue<>(k, Comparator.reverseOrder());
for(int i = 0; i < k; i ++){
q.offer(nums[i]);
}
res[0] = q.peek();
int index = 1;
for(int i = k; i < nums.length; i ++){
q.remove(nums[index - 1]);
q.offer(nums[i]);
res[index++] = q.peek();
}
return res;
}
}双端队列
class Solution {
public int[] maxSlidingWindow(int[] nums, int k) {
if(nums.length == 0) return new int[0];
int[] res = new int[nums.length - k + 1];
Deque<Integer> q = new LinkedList<>();
int index = 0;
for(int i = 0; i < nums.length; i ++){
while(!q.isEmpty() && nums[q.peekLast()] <= nums[i]){
q.pollLast();
}
q.offerLast(i);
if(q.peek() == i - k) q.pollFirst();
if(i >= k - 1) res[index ++] = nums[q.peek()];
}
return res;
}
}给定两个字符串 s 和 t ,编写一个函数来判断 t 是否是 s 的一个字母异位词。
示例 1:
输入: s = "anagram", t = "nagaram"
输出: true
示例 2:
输入: s = "rat", t = "car"
输出: false
说明: 你可以假设字符串只包含小写字母。
代码
hashmap
class Solution {
public boolean isAnagram(String s, String t) {
Map<Character, Integer> sMap = new HashMap<>();
Map<Character, Integer> tMap = new HashMap<>();
char[] sC = s.toCharArray();
char[] sT = t.toCharArray();
for(char c : sC){
sMap.put(c, sMap.getOrDefault(c, 0) + 1);
}
for(char c : sT){
tMap.put(c, tMap.getOrDefault(c, 0) + 1);
}
return sMap.equals(tMap);
}
}数组映射
class Solution {
public boolean isAnagram(String s, String t) {
int[] a = new int[26];
int[] b = new int[26];
char[] sC = s.toCharArray();
char[] tC = t.toCharArray();
for(char c : sC){
a[c - 'a'] += 1;
}
for(char c : tC){
b[c - 'a'] += 1;
}
return Arrays.equals(a, b);
}
}给定一个整数数组 nums 和一个目标值 target,请你在该数组中找出和为目标值的那 两个 整数,并返回他们的数组下标。
你可以假设每种输入只会对应一个答案。但是,你不能重复利用这个数组中同样的元素。
示例:
给定 nums = [2, 7, 11, 15], target = 9
因为 nums[0] + nums[1] = 2 + 7 = 9
所以返回 [0, 1]
代码
class Solution {
public int[] twoSum(int[] nums, int target) {
Map<Integer, Integer> map = new HashMap<>();
for(int i = 0; i < nums.length; i ++){
if(map.containsKey(target - nums[i])) {
return new int[]{map.get(target - nums[i]), i};
}
map.put(nums[i], i);
}
return new int[2];
}
}给定一个包含 n 个整数的数组 nums,判断 nums 中是否存在三个元素 *a,b,c ,*使得 a + b + c = 0 ?找出所有满足条件且不重复的三元组。
**注意:**答案中不可以包含重复的三元组。
例如, 给定数组 nums = [-1, 0, 1, 2, -1, -4],
满足要求的三元组集合为:
[
[-1, 0, 1],
[-1, -1, 2]
]
代码
排序后枚举
class Solution {
public List<List<Integer>> threeSum(int[] nums) {
Arrays.sort(nums);
Set<List<Integer>> res = new HashSet<>();
for(int i = 0; i < nums.length - 1; i ++){
if(i > 0 && nums[i] == nums[i - 1]) continue;
Set<Integer> set = new HashSet<>();
for(int j = i + 1; j < nums.length; j ++){
if(!set.contains(nums[j])) set.add(-nums[i]-nums[j]);
else {
res.add(Arrays.asList(nums[i], -nums[i] - nums[j], nums[j]));
}
}
}
return new ArrayList<>(res);
}
}排序后使用双指针
class Solution {
public List<List<Integer>> threeSum(int[] nums) {
Arrays.sort(nums);
List<List<Integer>> res = new ArrayList<>();
for(int i = 0; i < nums.length - 1; i ++){
if(i > 0 && nums[i] == nums[i - 1]) continue;
int start = i + 1;
int end = nums.length - 1;
while(start < end){
int sum = nums[i] + nums[start] + nums[end];
if(sum > 0) end --;
else if(sum < 0) start ++;
else {
res.add(Arrays.asList(nums[i], nums[start], nums[end]));
//判重
while(start < end && nums[start] == nums[start + 1]) start ++;
while(start < end && nums[end] == nums[end - 1]) end --;
start ++;
end --;
}
}
}
return res;
}
}给定一个二叉树,判断其是否是一个有效的二叉搜索树。
假设一个二叉搜索树具有如下特征:
- 节点的左子树只包含小于当前节点的数。
- 节点的右子树只包含大于当前节点的数。
- 所有左子树和右子树自身必须也是二叉搜索树。
示例 1:
输入:
2
/ \
1 3
输出: true
示例 2:
输入:
5
/ \
1 4
/ \
3 6
输出: false
解释: 输入为: [5,1,4,null,null,3,6]。
根节点的值为 5 ,但是其右子节点值为 4 。
代码
利用中序遍历的有序性
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
List<Integer> list = new ArrayList<>();
public boolean isValidBST(TreeNode root) {
midOrder(root);
if(list.size() == 0) return true;
int tmp = list.get(0);
for(int i = 1,length = list.size(); i < length; i ++){
if(list.get(i) <= tmp){
return false;
}
tmp = list.get(i);
}
return true;
}
public void midOrder(TreeNode root){
if(root != null){
midOrder(root.left);
list.add(root.val);
midOrder(root.right);
}
}
}递归
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
TreeNode pre = null;
public boolean isValidBST(TreeNode root) {
if(root == null) return true;
if(!isValidBST(root.left)) return false;
if(pre != null && pre.val >= root.val) return false;
pre = root;
return isValidBST(root.right);
}
}给定一个二叉搜索树, 找到该树中两个指定节点的最近公共祖先。
百度百科中最近公共祖先的定义为:“对于有根树 T 的两个结点 p、q,最近公共祖先表示为一个结点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”
例如,给定如下二叉搜索树: root = [6,2,8,0,4,7,9,null,null,3,5]
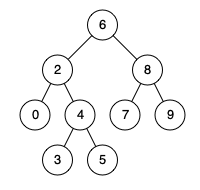
代码
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
while(root != null){
if(p.val > root.val && q.val > root.val) root = root.right;
else if(p.val < root.val && q.val < root.val) root = root.left;
else return root;
}
return null;
}
}实现 pow(x, n) ,即计算 x 的 n 次幂函数。
示例 1:
输入: 2.00000, 10
输出: 1024.00000
示例 2:
输入: 2.10000, 3
输出: 9.26100
示例 3:
输入: 2.00000, -2
输出: 0.25000
解释: 2-2 = 1/22 = 1/4 = 0.25
说明:
- -100.0 < x < 100.0
- n 是 32 位有符号整数,其数值范围是 [−231, 231 − 1] 。
代码
class Solution {
public double myPow(double x, int n) {
if (n < 0) return 1.0 / myPow(x, -n);
if (n == 0) return 1;
double v = myPow(x, n / 2);
return n % 2 == 0 ? v * v : v * v * x;
}
}给定一个大小为 n 的数组,找到其中的众数。众数是指在数组中出现次数大于 ⌊ n/2 ⌋ 的元素。
你可以假设数组是非空的,并且给定的数组总是存在众数。
示例 1:
输入: [3,2,3]
输出: 3
示例 2:
输入: [2,2,1,1,1,2,2]
输出: 2
代码
利用map计数
class Solution {
public int majorityElement(int[] nums) {
Map<Integer, Integer> map = new HashMap<>();
for(int i = 0, length = nums.length; i < length; i ++){
if(map.containsKey(nums[i])){
map.put(nums[i], map.get(nums[i]) + 1);
}else{
map.put(nums[i], 1);
}
}
Set<Integer> set = map.keySet();
for(Integer key : set){
if(map.get(key) > nums.length/2) return key;
}
return 0;
}
}排序计数
class Solution {
public int majorityElement(int[] nums) {
if(nums.length == 1) return nums[0];
Arrays.sort(nums);
int count = 1;
for(int i = 1; i < nums.length; i ++){
if(nums[i] == nums[i-1]){
count ++;
} else count = 1;
if(count > nums.length / 2) return nums[i];
}
return 0;
}
}给定一个数组,它的第 i 个元素是一支给定股票第 i 天的价格。
设计一个算法来计算你所能获取的最大利润。你可以尽可能地完成更多的交易(多次买卖一支股票)。
**注意:**你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。
示例 1:
输入: [7,1,5,3,6,4]
输出: 7
解释: 在第 2 天(股票价格 = 1)的时候买入,在第 3 天(股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5-1 = 4 。
随后,在第 4 天(股票价格 = 3)的时候买入,在第 5 天(股票价格 = 6)的时候卖出, 这笔交易所能获得利润 = 6-3 = 3 。
示例 2:
输入: [1,2,3,4,5]
输出: 4
解释: 在第 1 天(股票价格 = 1)的时候买入,在第 5 天 (股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5-1 = 4 。
注意你不能在第 1 天和第 2 天接连购买股票,之后再将它们卖出。
因为这样属于同时参与了多笔交易,你必须在再次购买前出售掉之前的股票。
示例 3:
输入: [7,6,4,3,1]
输出: 0
解释: 在这种情况下, 没有交易完成, 所以最大利润为 0。
代码
class Solution {
public int maxProfit(int[] prices) {
if(prices == null || prices.length == 0) return 0;
int cur = prices[0];
int length = prices.length;
int res = 0;
for(int i = 0; i < length; i ++){
if(prices[i] > cur){
res += (prices[i] - cur);
cur = prices[i];
}else{
cur = prices[i];
}
}
return res;
}
}BFS()
{
输入起始点;
初始化所有顶点标记为未遍历;
初始化一个队列queue并将起始点放入队列;
while(queue不为空)
{
从队列中删除一个顶点s并标记为已遍历;
将s邻接的所有还没遍历的点加入队列;
}
}
DFS(顶点v)
{
标记v为已遍历;
for(对于每一个邻接v且未标记遍历的点u)
DFS(u);
}
给定一个二叉树,返回其按层次遍历的节点值。 (即逐层地,从左到右访问所有节点)。
例如:
给定二叉树: [3,9,20,null,null,15,7],
3
/ \
9 20
/ \
15 7
返回其层次遍历结果:
[
[3],
[9,20],
[15,7]
]
代码
bfs
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public List<List<Integer>> levelOrder(TreeNode root) {
if(root == null) return new ArrayList<>();
Queue<TreeNode> queue = new LinkedList<>();
List<List<Integer>> result = new ArrayList<>();
queue.offer(root);
while (!queue.isEmpty()){
List<Integer> node = new ArrayList<>();
int length = queue.size();
while (length > 0){
TreeNode tree = queue.poll();
if(tree.left != null){
queue.offer(tree.left);
}
if(tree.right != null){
queue.offer(tree.right);
}
node.add(tree.val);
length --;
}
result.add(node);
}
return result;
}
}也可以用dfs
class Solution {
public List<List<Integer>> levelOrder(TreeNode root) {
if(root == null) return new ArrayList<>();
List<List<Integer>> res = new ArrayList<>();
_dfs(res, root, 0);
return res;
}
public void _dfs(List<List<Integer>> list, TreeNode node, int level){
if(node == null) return;
if(list.size() < level + 1){
list.add(new ArrayList<>());
}
list.get(level).add(node.val);
_dfs(list, node.left, level + 1);
_dfs(list, node.right, level + 1);
}
}给定一个二叉树,找出其最大深度。
二叉树的深度为根节点到最远叶子节点的最长路径上的节点数。
说明: 叶子节点是指没有子节点的节点。
示例:
给定二叉树 [3,9,20,null,null,15,7],
3
/ \
9 20
/ \
15 7
返回它的最大深度 3 。
代码
DFS
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public int maxDepth(TreeNode root) {
return root == null ? 0 : Math.max(maxDepth(root.left),maxDepth(root.right)) + 1;
}
}BFS
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public int maxDepth(TreeNode root) {
if(root == null) return 0;
Queue<TreeNode> q = new LinkedList<>();
q.offer(root);
int count = 1;
while(!q.isEmpty()){
int length = q.size();
boolean flag = false;
for(int i = 0; i < length; i ++){
TreeNode node = q.poll();
if(node.left != null || node.right != null) flag = true;
if(node.left != null) q.offer(node.left);
if(node.right != null) q.offer(node.right);
}
if(flag) count ++;
}
return count;
}
}给定一个二叉树,找出其最小深度。
最小深度是从根节点到最近叶子节点的最短路径上的节点数量。
说明: 叶子节点是指没有子节点的节点。
示例:
给定二叉树 [3,9,20,null,null,15,7],
3
/ \
9 20
/ \
15 7
返回它的最小深度 2.
代码
BFS
class Solution {
public int minDepth(TreeNode root) {
if(root == null) return 0;
Queue<TreeNode> q = new LinkedList<>();
q.offer(root);
int count = 1;
while(!q.isEmpty()){
int length = q.size();
boolean flag = false;
for(int i = 0; i < length; i ++){
TreeNode node = q.poll();
if(node.left == null && node.right == null) return count;
if(node.left != null || node.right != null) flag = true;
if(node.left != null) q.offer(node.left);
if(node.right != null) q.offer(node.right);
}
if(flag) count ++;
}
return count;
}
}DFS
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public int minDepth(TreeNode root) {
if(null == root) return 0;
if(null == root.left) return minDepth(root.right) + 1;
if(null == root.right) return minDepth(root.left) + 1;
return Math.min(minDepth(root.left),minDepth(root.right)) + 1;
}
}给出 n 代表生成括号的对数,请你写出一个函数,使其能够生成所有可能的并且有效的括号组合。
例如,给出 n = 3,生成结果为:
[
"((()))",
"(()())",
"(())()",
"()(())",
"()()()"
]
代码
class Solution {
public List<String> generateParenthesis(int n) {
List<String> res = new ArrayList<>();
_gen(res, 0, 0, n, "");
return res;
}
public void _gen(List<String> list, int left, int right, int n, String res){
if(left == n && right == n){
list.add(res);
return;
}
if(left < n){
_gen(list, left + 1, right, n, res + "(");
}
if(left > right && right < n){
_gen(list, left, right + 1, n, res + ")");
}
}
}n 皇后问题研究的是如何将 n 个皇后放置在 n×n 的棋盘上,并且使皇后彼此之间不能相互攻击。
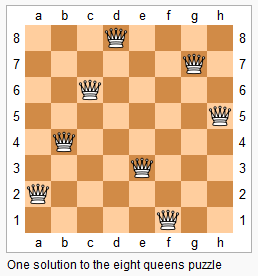
上图为 8 皇后问题的一种解法。
给定一个整数 n,返回所有不同的 n 皇后问题的解决方案。
每一种解法包含一个明确的 n 皇后问题的棋子放置方案,该方案中 'Q' 和 '.' 分别代表了皇后和空位。
示例:
输入: 4
输出: [
[".Q..", // 解法 1
"...Q",
"Q...",
"..Q."],
["..Q.", // 解法 2
"Q...",
"...Q",
".Q.."]
]
解释: 4 皇后问题存在两个不同的解法。
代码
class Solution {
private List<List<String>> res = new ArrayList<>();
private Set<Integer> cols = new HashSet<>();
private Set<Integer> pie = new HashSet<>();
private Set<Integer> na = new HashSet<>();
public List<List<String>> solveNQueens(int n) {
if (n < 1) {
return new ArrayList<>();
}
dfs(n, 0, new ArrayList<>());
return res;
}
public void dfs(int n, int row, List<String> curState) {
if (row >= n) {
res.add(curState);
return;
}
for (int i = 0; i < n; i ++) {
if (cols.contains(i) || pie.contains(row + i) || na.contains(row - i)) {
continue;
}
cols.add(i);
pie.add(row + i);
na.add(row - i);
StringBuilder sb = new StringBuilder();
for(int j = 0; j < n; j ++) {
if (j == i) {
sb.append("Q");
} else {
sb.append(".");
}
}
List<String> tmp = new ArrayList(curState);
tmp.add(sb.toString());
dfs(n, row + 1, tmp);
cols.remove(i);
pie.remove(row + i);
na.remove(row - i);
}
}
}判断一个 9x9 的数独是否有效。只需要根据以下规则,验证已经填入的数字是否有效即可。
- 数字
1-9在每一行只能出现一次。 - 数字
1-9在每一列只能出现一次。 - 数字
1-9在每一个以粗实线分隔的3x3宫内只能出现一次。

上图是一个部分填充的有效的数独。
数独部分空格内已填入了数字,空白格用 '.' 表示。
示例 1:
输入:
[
["5","3",".",".","7",".",".",".","."],
["6",".",".","1","9","5",".",".","."],
[".","9","8",".",".",".",".","6","."],
["8",".",".",".","6",".",".",".","3"],
["4",".",".","8",".","3",".",".","1"],
["7",".",".",".","2",".",".",".","6"],
[".","6",".",".",".",".","2","8","."],
[".",".",".","4","1","9",".",".","5"],
[".",".",".",".","8",".",".","7","9"]
]
输出: true
示例 2:
输入:
[
["8","3",".",".","7",".",".",".","."],
["6",".",".","1","9","5",".",".","."],
[".","9","8",".",".",".",".","6","."],
["8",".",".",".","6",".",".",".","3"],
["4",".",".","8",".","3",".",".","1"],
["7",".",".",".","2",".",".",".","6"],
[".","6",".",".",".",".","2","8","."],
[".",".",".","4","1","9",".",".","5"],
[".",".",".",".","8",".",".","7","9"]
]
输出: false
解释: 除了第一行的第一个数字从 5 改为 8 以外,空格内其他数字均与 示例1 相同。
但由于位于左上角的 3x3 宫内有两个 8 存在, 因此这个数独是无效的。
说明:
- 一个有效的数独(部分已被填充)不一定是可解的。
- 只需要根据以上规则,验证已经填入的数字是否有效即可。
- 给定数独序列只包含数字
1-9和字符'.'。 - 给定数独永远是
9x9形式的。
代码
class Solution {
public boolean isValidSudoku(char[][] board) {
// 记录某行,某位数字是否已经被摆放
boolean[][] row = new boolean[9][9];
// 记录某列,某位数字是否已经被摆放
boolean[][] col = new boolean[9][9];
// 记录某 3x3 宫格内,某位数字是否已经被摆放
boolean[][] block = new boolean[9][9];
for (int i = 0; i < 9; i++) {
for (int j = 0; j < 9; j++) {
if (board[i][j] != '.') {
int num = board[i][j] - '1';
int blockIndex = i / 3 * 3 + j / 3;
if (row[i][num] || col[j][num] || block[blockIndex][num]) {
return false;
} else {
row[i][num] = true;
col[j][num] = true;
block[blockIndex][num] = true;
}
}
}
}
return true;
}
}编写一个程序,通过已填充的空格来解决数独问题。
一个数独的解法需遵循如下规则:
- 数字
1-9在每一行只能出现一次。 - 数字
1-9在每一列只能出现一次。 - 数字
1-9在每一个以粗实线分隔的3x3宫内只能出现一次。
空白格用 '.' 表示。

一个数独。

答案被标成红色。
Note:
- 给定的数独序列只包含数字
1-9和字符'.'。 - 你可以假设给定的数独只有唯一解。
- 给定数独永远是
9x9形式的。
代码
class Solution {
public void solveSudoku(char[][] board) {
if (board == null || board.length == 0) return;
solve(board);
}
private boolean solve(char[][] board) {
for (int i = 0; i < board.length; i ++) {
for (int j = 0; j < board[0].length; j ++) {
if (board[i][j] == '.') {
for (char c = '1'; c <= '9'; c ++) {
if (isValid(board, i, j, c)) {
board[i][j] = c;
if (solve(board)) {
return true;
} else {
board[i][j] = '.';//还原
}
}
}
return false;
}
}
}
return true;
}
private boolean isValid(char[][] board, int row, int col, char c) {
for (int i = 0; i < 9; i ++) {
if(board[i][col] != '.' && board[i][col] == c) return false;
if(board[row][i] != '.' && board[row][i] == c) return false;
int blocki = 3 * (row / 3) + i / 3;
int blockj = 3 * (col / 3) + i % 3;
if(board[blocki][blockj] != '.' && board[blocki][blockj] == c) return false;
}
return true;
}
}public int getTargetIndex(int[] arr, int target) {
int left = 0;
int right = arr.length - 1;
while (left <= right) {
int mid = (left + right) / 2;
if (arr[mid] == target) {
return mid;
} else if (arr[mid] < target) {
left = mid + 1;
} else {
right = mid - 1;
}
}
return -1;
}实现 int sqrt(int x) 函数。
计算并返回 x 的平方根,其中 x 是非负整数。
由于返回类型是整数,结果只保留整数的部分,小数部分将被舍去。
示例 1:
输入: 4
输出: 2
示例 2:
输入: 8
输出: 2
说明: 8 的平方根是 2.82842...,
由于返回类型是整数,小数部分将被舍去。
代码
class Solution {
public int mySqrt(int x) {
if(x == 0 || x == 1) return x;
int left = 1;
int right = x;
while (left <= right) {
int mid = (left + right) / 2;
if (mid == x / mid) {
return mid;
} else if (mid > x / mid) {
right = mid - 1;
} else {
left = mid + 1;
}
}
return left - 1;
}
}给定一个正整数 num,编写一个函数,如果 num 是一个完全平方数,则返回 True,否则返回 False。
**说明:**不要使用任何内置的库函数,如 sqrt。
示例 1:
输入:16
输出:True
示例 2:
输入:14
输出:False
代码
公式法--1+3+5+7+9+…+(2n-1)=n^2
class Solution {
public boolean isPerfectSquare(int num) {
int sum = 0;
for(int i = 1; num > 0; i +=2){
num -= i;
}
return num == 0;
}
}二分法
class Solution {
public boolean isPerfectSquare(int num) {
if(num == 0 || num == 1) return true;
int left = 1;
int right = num;
int res = 0;
while (left <= right) {
int mid = (left + right) / 2;
if (mid == num / mid) {
res = mid;
break;
} else if (mid > num / mid) {
right = mid - 1;
} else {
left = mid + 1;
res = mid;
}
}
return res * res == num;
}
}实现一个 Trie (前缀树),包含 insert, search, 和 startsWith 这三个操作。
示例:
Trie trie = new Trie();
trie.insert("apple");
trie.search("apple"); // 返回 true
trie.search("app"); // 返回 false
trie.startsWith("app"); // 返回 true
trie.insert("app");
trie.search("app"); // 返回 true
说明:
- 你可以假设所有的输入都是由小写字母
a-z构成的。 - 保证所有输入均为非空字符串。
代码
class Trie {
Trie[] children = new Trie[26];
boolean isEndOfWord = false;
/** Initialize your data structure here. */
public Trie() {
}
/** Inserts a word into the trie. */
public void insert(String word) {
char[] arr = word.toCharArray();
Trie[] childs = children;
for (int i = 0; i < arr.length; i ++) {
if (childs[arr[i] - 'a'] == null) {
childs[arr[i] - 'a'] = new Trie();
}
if (i == arr.length - 1) {
childs[arr[i] - 'a'].isEndOfWord = true;
}
childs = childs[arr[i] - 'a'].children;
}
}
/** Returns if the word is in the trie. */
public boolean search(String word) {
char[] arr = word.toCharArray();
Trie[] childs = children;
for (int i = 0; i < arr.length; i ++) {
if (childs[arr[i] - 'a'] == null) {
return false;
}
if (i == arr.length - 1 && !childs[arr[i] - 'a'].isEndOfWord) {
return false;
}
childs = childs[arr[i] - 'a'].children;
}
return true;
}
/** Returns if there is any word in the trie that starts with the given prefix. */
public boolean startsWith (String prefix) {
char[] arr = prefix.toCharArray();
Trie[] childs = children;
for (int i = 0; i < arr.length; i ++) {
if (childs[arr[i] - 'a'] == null) {
return false;
}
childs = childs[arr[i] - 'a'].children;
}
return true;
}
}
/**
* Your Trie object will be instantiated and called as such:
* Trie obj = new Trie();
* obj.insert(word);
* boolean param_2 = obj.search(word);
* boolean param_3 = obj.startsWith(prefix);
*/给定一个二维网格 board 和一个字典中的单词列表 words,找出所有同时在二维网格和字典中出现的单词。
单词必须按照字母顺序,通过相邻的单元格内的字母构成,其中“相邻”单元格是那些水平相邻或垂直相邻的单元格。同一个单元格内的字母在一个单词中不允许被重复使用。
示例:
输入:
words = ["oath","pea","eat","rain"] and board =
[
['o','a','a','n'],
['e','t','a','e'],
['i','h','k','r'],
['i','f','l','v']
]
输出: ["eat","oath"]
说明:
你可以假设所有输入都由小写字母 a-z 组成。
提示:
- 你需要优化回溯算法以通过更大数据量的测试。你能否早点停止回溯?
- 如果当前单词不存在于所有单词的前缀中,则可以立即停止回溯。什么样的数据结构可以有效地执行这样的操作?散列表是否可行?为什么? 前缀树如何?如果你想学习如何实现一个基本的前缀树,请先查看这个问题: 实现Trie(前缀树)。
代码
class Solution {
Set<String> res = new HashSet<>();
public List<String> findWords(char[][] board, String[] words) {
Trie trie = new Trie();
for (String word : words) {
trie.insert(word);
}
int m = board.length;
int n = board[0].length;
boolean[][] visited = new boolean[m][n];
for (int i = 0; i < m; i ++) {
for (int j = 0; j < n; j ++) {
dfs(board, visited, "", i, j, trie);
}
}
return new ArrayList<>(res);
}
private void dfs(char[][] board, boolean[][] visited, String str, int x, int y, Trie trie) {
if (x < 0 || x >= board.length || y < 0 || y >= board[0].length) return;
if (visited[x][y]) return;
str += board[x][y];
if (!trie.startsWith(str)) return;
if (trie.search(str)) {
res.add(str);
}
visited[x][y] = true;
dfs(board, visited, str, x - 1, y, trie);
dfs(board, visited, str, x + 1, y, trie);
dfs(board, visited, str, x, y - 1, trie);
dfs(board, visited, str, x, y + 1, trie);
visited[x][y] = false;
}
}
class Trie {
Trie[] children = new Trie[26];
boolean isEndOfWord = false;
/** Initialize your data structure here. */
public Trie() {
}
/** Inserts a word into the trie. */
public void insert(String word) {
char[] arr = word.toCharArray();
Trie[] childs = children;
for (int i = 0; i < arr.length; i ++) {
if (childs[arr[i] - 'a'] == null) {
childs[arr[i] - 'a'] = new Trie();
}
if (i == arr.length - 1) {
childs[arr[i] - 'a'].isEndOfWord = true;
}
childs = childs[arr[i] - 'a'].children;
}
}
/** Returns if the word is in the trie. */
public boolean search(String word) {
char[] arr = word.toCharArray();
Trie[] childs = children;
for (int i = 0; i < arr.length; i ++) {
if (childs[arr[i] - 'a'] == null) {
return false;
}
if (i == arr.length - 1 && !childs[arr[i] - 'a'].isEndOfWord) {
return false;
}
childs = childs[arr[i] - 'a'].children;
}
return true;
}
/** Returns if there is any word in the trie that starts with the given prefix. */
public boolean startsWith (String prefix) {
char[] arr = prefix.toCharArray();
Trie[] childs = children;
for (int i = 0; i < arr.length; i ++) {
if (childs[arr[i] - 'a'] == null) {
return false;
}
childs = childs[arr[i] - 'a'].children;
}
return true;
}
}编写一个函数,输入是一个无符号整数,返回其二进制表达式中数字位数为 ‘1’ 的个数(也被称为汉明重量)。
示例 1:
输入:00000000000000000000000000001011
输出:3
解释:输入的二进制串 00000000000000000000000000001011 中,共有三位为 '1'。
示例 2:
输入:00000000000000000000000010000000
输出:1
解释:输入的二进制串 00000000000000000000000010000000 中,共有一位为 '1'。
示例 3:
输入:11111111111111111111111111111101
输出:31
解释:输入的二进制串 11111111111111111111111111111101 中,共有 31 位为 '1'。
提示:
- 请注意,在某些语言(如 Java)中,没有无符号整数类型。在这种情况下,输入和输出都将被指定为有符号整数类型,并且不应影响您的实现,因为无论整数是有符号的还是无符号的,其内部的二进制表示形式都是相同的。
- 在 Java 中,编译器使用二进制补码记法来表示有符号整数。因此,在上面的 示例 3 中,输入表示有符号整数
-3。
代码
遍历每一位是否为1
public class Solution {
// you need to treat n as an unsigned value
public int hammingWeight(int n) {
int count = 0;
for (int i = 0; i < 32; i ++) {
count += n & 1;
n >>= 1;
}
return count;
}
}逐步打掉最后的1
public class Solution {
// you need to treat n as an unsigned value
public int hammingWeight(int n) {
int count = 0;
while (n != 0) {
count ++;
n = n & (n-1);
}
return count;
}
}给定一个整数,编写一个函数来判断它是否是 2 的幂次方。
示例 1:
输入: 1
输出: true
解释: 20 = 1
示例 2:
输入: 16
输出: true
解释: 24 = 16
示例 3:
输入: 218
输出: false
代码
迭代判断
class Solution {
public boolean isPowerOfTwo(int n) {
if (n < 1) return false;
while (n > 1) {
if(n % 2 != 0) return false;
n /= 2;
}
return true;
}
}位运算(2的幂二进制只有一个1)
class Solution {
public boolean isPowerOfTwo(int n) {
return n > 0 && (n & (n - 1)) == 0;
}
}给定一个非负整数 num。对于 0 ≤ i ≤ num 范围中的每个数字 i ,计算其二进制数中的 1 的数目并将它们作为数组返回。
示例 1:
输入: 2
输出: [0,1,1]
示例 2:
输入: 5
输出: [0,1,1,2,1,2]
进阶:
- 给出时间复杂度为**O(n*sizeof(integer))的解答非常容易。但你可以在线性时间O(n)**内用一趟扫描做到吗?
- 要求算法的空间复杂度为O(n)。
- 你能进一步完善解法吗?要求在C++或任何其他语言中不使用任何内置函数(如 C++ 中的 __builtin_popcount)来执行此操作。
代码
求每个数的1的数目
class Solution {
public int[] countBits(int num) {
int[] res = new int[num + 1];
for (int i = 0; i <= num; i ++) {
res[i] = get1num(i);
}
return res;
}
private int get1num(int num) {
int count = 0;
while (num != 0) {
count ++;
num &= num-1;
}
return count;
}
}利用位运算 i&(i-1)要比i少一个1
class Solution {
public int[] countBits(int num) {
int[] res = new int[num + 1];
for (int i = 1; i <= num; i ++) {
res[i] = res[i & (i - 1)] + 1;
}
return res;
}
}斐波那契数,通常用 F(n) 表示,形成的序列称为斐波那契数列。该数列由 0 和 1 开始,后面的每一项数字都是前面两项数字的和。也就是:
F(0) = 0, F(1) = 1
F(N) = F(N - 1) + F(N - 2), 其中 N > 1.
给定 N,计算 F(N)。
示例 1:
输入:2
输出:1
解释:F(2) = F(1) + F(0) = 1 + 0 = 1.
示例 2:
输入:3
输出:2
解释:F(3) = F(2) + F(1) = 1 + 1 = 2.
示例 3:
输入:4
输出:3
解释:F(4) = F(3) + F(2) = 2 + 1 = 3.
代码
递归
public int fib(int N) {
if(N < 2) return N;
return fib(N - 1) + fib(N - 2);
}动态规划
public int fib(int N) {
//dp[N] = dp[N - 1] + dp[N - 2];
int[] dp = new int[N + 1];
if(N == 0) return 0;
dp[0] = 0;
dp[1] = 1;
for(int i = 2; i <= N; i ++){
dp[i] = dp[i - 1] + dp[i - 2];
}
return dp[N];
}遍历
public int fib(int N) {
if(N < 2) return N;
int a = 0;
int b = 1;
int c = 0;
for(int i = 2; i <= N; i ++){
c = a + b;
a = b;
b = c;
}
return c;
}假设你正在爬楼梯。需要 n 阶你才能到达楼顶。
每次你可以爬 1 或 2 个台阶。你有多少种不同的方法可以爬到楼顶呢?
**注意:**给定 n 是一个正整数。
示例 1:
输入: 2
输出: 2
解释: 有两种方法可以爬到楼顶。
1. 1 阶 + 1 阶
2. 2 阶
示例 2:
输入: 3
输出: 3
解释: 有三种方法可以爬到楼顶。
1. 1 阶 + 1 阶 + 1 阶
2. 1 阶 + 2 阶
3. 2 阶 + 1 阶
代码
class Solution {
public int climbStairs(int n) {
int[] dp = new int[n + 1];
dp[0] = 1;
dp[1] = 1;
for (int i = 2; i <= n; i ++) {
dp[i] = dp[i - 1] + dp[i - 2];
}
return dp[n];
}
}给定一个三角形,找出自顶向下的最小路径和。每一步只能移动到下一行中相邻的结点上。
例如,给定三角形:
[
[2],
[3,4],
[6,5,7],
[4,1,8,3]
]
自顶向下的最小路径和为 11(即,2 + 3 + 5 + 1 = 11)。
说明:
如果你可以只使用 O(n) 的额外空间(n 为三角形的总行数)来解决这个问题,那么你的算法会很加分。
代码
二维数组
class Solution {
public int minimumTotal(List<List<Integer>> triangle) {
//dp[i][j] = min(dp[i + 1][j], dp[i + 1][j + 1]) + triangle.get(i).get(j)
int m = triangle.size();
int[][] dp = new int[m][triangle.get(m - 1).size()];
for (int i = 0; i < triangle.get(m - 1).size(); i ++) {
dp[m - 1][i] = triangle.get(m - 1).get(i);
}
for (int i = m - 2; i >= 0; i --) {
for (int j = 0; j < triangle.get(i).size(); j ++) {
dp[i][j] = Math.min(dp[i + 1][j],
dp[i + 1][j + 1]) + triangle.get(i).get(j);
}
}
return dp[0][0];
}
}一维数组
class Solution {
public int minimumTotal(List<List<Integer>> triangle) {
//dp[j] = Math.min(dp[j], dp[j + 1]) + triangle.get(i).get(j);
int m = triangle.size();
int n = triangle.get(m - 1).size();
int[] dp = new int[n];
for (int i = 0; i < n; i ++) {
dp[i] = triangle.get(m - 1).get(i);
}
for (int i = m - 2; i >= 0; i --) {
for (int j = 0; j < triangle.get(i).size(); j ++) {
dp[j] = Math.min(dp[j], dp[j + 1]) + triangle.get(i).get(j);
}
}
return dp[0];
}
}给定一个整数数组 nums ,找出一个序列中乘积最大的连续子序列(该序列至少包含一个数)。
示例 1:
输入: [2,3,-2,4]
输出: 6
解释: 子数组 [2,3] 有最大乘积 6。
示例 2:
输入: [-2,0,-1]
输出: 0
解释: 结果不能为 2, 因为 [-2,-1] 不是子数组。
代码
解法1
class Solution {
public int maxProduct(int[] nums) {
int[][] dp = new int[2][2];
dp[0][1] = nums[0];//最小值
dp[0][0] = nums[0];//最大值
int res = nums[0];
for (int i = 1; i < nums.length; i ++) {
int x = i % 2;
int y = (i - 1) % 2;
dp[x][0] = Math.max(Math.max(dp[y][0] * nums[i], dp[y][1] * nums[i]), nums[i]);
dp[x][1] = Math.min(Math.min(dp[y][0] * nums[i], dp[y][1] * nums[i]), nums[i]);
res = Math.max(res, dp[x][0]);
}
return res;
}
}解法2
class Solution {
public int maxProduct(int[] nums) {
int curMin = nums[0];//最小值
int curMax = nums[0];//最大值
int res = nums[0];
for (int i = 1; i < nums.length; i ++) {
int tmpMax = curMax * nums[i];
int tmpMin = curMin * nums[i];
curMin = Math.min(Math.min(tmpMax, tmpMin), nums[i]);
curMax = Math.max(Math.max(tmpMax, tmpMin), nums[i]);
res = Math.max(res, curMax);
}
return res;
}
}给定一个数组,它的第 i 个元素是一支给定股票第 i 天的价格。
如果你最多只允许完成一笔交易(即买入和卖出一支股票),设计一个算法来计算你所能获取的最大利润。
注意你不能在买入股票前卖出股票。
示例 1:
输入: [7,1,5,3,6,4]
输出: 5
解释: 在第 2 天(股票价格 = 1)的时候买入,在第 5 天(股票价格 = 6)的时候卖出,最大利润 = 6-1 = 5 。
注意利润不能是 7-1 = 6, 因为卖出价格需要大于买入价格。
示例 2:
输入: [7,6,4,3,1]
输出: 0
解释: 在这种情况下, 没有交易完成, 所以最大利润为 0。
代码
循环
class Solution {
public int maxProfit(int[] prices) {
int tmp = 0;
int max = 0;
for (int i = 1; i < prices.length; i ++) {
int diff = prices[i] - prices[i - 1];
//连续差值和 如 1 5 3 6 -- (6 - 1) = (5 - 1) + (3 - 5) + (6 - 3)
tmp = tmp + diff > 0 ? tmp + diff : 0;
max = Math.max(max, tmp);
}
return max;
}
}动态规划
class Solution {
public int maxProfit(int[] prices) {
if (prices == null || prices.length == 0) return 0;
int res = 0;
int[][] profit = new int[prices.length][3];
profit[0][0] = 0;//没有买入股票
profit[0][1] = -prices[0];//买入股票没有卖出
profit[0][2] = 0;//之前买过股票,现在卖了
for (int i = 1; i < prices.length; i ++) {
profit[i][0] = profit[i - 1][0];
profit[i][1] = Math.max(profit[i - 1][1], profit[i - 1][0] - prices[i]);//前一天买入股票,或者之前没有股票今天刚买
profit[i][2] = profit[i - 1][1] + prices[i];
res = Math.max(Math.max(res, profit[i][0]), Math.max(profit[i][1], profit[i][2]));
}
return res;
}
}给定一个数组,它的第 i 个元素是一支给定的股票在第 i 天的价格。
设计一个算法来计算你所能获取的最大利润。你最多可以完成 两笔 交易。
注意: 你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。
示例 1:
输入: [3,3,5,0,0,3,1,4]
输出: 6
解释: 在第 4 天(股票价格 = 0)的时候买入,在第 6 天(股票价格 = 3)的时候卖出,这笔交易所能获得利润 = 3-0 = 3 。
随后,在第 7 天(股票价格 = 1)的时候买入,在第 8 天 (股票价格 = 4)的时候卖出,这笔交易所能获得利润 = 4-1 = 3 。
示例 2:
输入: [1,2,3,4,5]
输出: 4
解释: 在第 1 天(股票价格 = 1)的时候买入,在第 5 天 (股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5-1 = 4 。
注意你不能在第 1 天和第 2 天接连购买股票,之后再将它们卖出。
因为这样属于同时参与了多笔交易,你必须在再次购买前出售掉之前的股票。
示例 3:
输入: [7,6,4,3,1]
输出: 0
解释: 在这个情况下, 没有交易完成, 所以最大利润为 0。
代码
class Solution {
public int maxProfit(int[] prices) {
if (prices == null || prices.length == 0) return 0;
int res = 0;
//第一位代表天数,第二位代表交易次数,第三位0代表不持有股票,1代表持有股票
int[][][] profit = new int[prices.length][3][2];
for (int i = 0; i < 3; i ++) {
//初始化第1天的数据
profit[0][i][0] = 0;
profit[0][i][1] = -prices[0];
}
for (int i = 1; i < prices.length; i ++) {
for (int j = 0; j < 3; j ++) {
//不持有股票分两种情况
//1:前一天持有,今天卖了 profit[i - 1][j - 1][1] + prices[i] 如果操作数为0则不存在本情况
//2: 前一天就不持有,今天无操作 profit[i - 1][j][0]
profit[i][j][0] = j != 0 ? Math.max(profit[i - 1][j][0], profit[i - 1][j - 1][1] + prices[i]) : profit[i - 1][j][0];
//持有股票分两种情况
//1: 前一天持有,今天无操作 profit[i - 1][j][1]
//2:前一天不持有,今天买入 profit[i - 1][j][0] - prices[i]
profit[i][j][1] = Math.max(profit[i - 1][j][1], profit[i - 1][j][0] - prices[i]);
res = Math.max(res, profit[i][j][0]);
}
}
return res;
}
}给定一个无序的整数数组,找到其中最长上升子序列的长度。
示例:
输入: [10,9,2,5,3,7,101,18]
输出: 4
解释: 最长的上升子序列是 [2,3,7,101],它的长度是 4。
说明:
- 可能会有多种最长上升子序列的组合,你只需要输出对应的长度即可。
- 你算法的时间复杂度应该为 O(n2) 。
进阶: 你能将算法的时间复杂度降低到 O(n log n) 吗?
代码
动态规划
class Solution {
public int lengthOfLIS(int[] nums) {
if (nums == null || nums.length == 0) return 0;
int n = nums.length;
int[] dp = new int[n];
Arrays.fill(dp, 1);
int res = 1;
for (int i = 1; i < n; i ++) {
for (int j = 0; j < i; j ++) {
if (nums[i] > nums[j]) {
dp[i] = Math.max(dp[j] + 1, dp[i]);
}
}
res = Math.max(res, dp[i]);
}
return res;
}
}二分
class Solution {
public int lengthOfLIS(int[] nums) {
if (nums == null || nums.length == 0) return 0;
List<Integer> lis = new ArrayList<>();
lis.add(nums[0]);
for (int i = 1; i < nums.length; i ++) {
int left = 0;
int right = lis.size() - 1;
int it = -1;
while (left <= right) {
int mid = (left + right) / 2;
if (lis.get(mid) >= nums[i]) {
it = mid;
right = mid - 1;
} else {
left = mid + 1;
}
}
if (it == -1) {
lis.add(nums[i]);
} else {
lis.set(it, nums[i]);
}
}
return lis.size();
}
}给定不同面额的硬币 coins 和一个总金额 amount。编写一个函数来计算可以凑成总金额所需的最少的硬币个数。如果没有任何一种硬币组合能组成总金额,返回 -1。
示例 1:
输入: coins = [1, 2, 5], amount = 11
输出: 3
解释: 11 = 5 + 5 + 1
示例 2:
输入: coins = [2], amount = 3
输出: -1
说明: 你可以认为每种硬币的数量是无限的。
代码
class Solution {
public int coinChange(int[] coins, int amount) {
int max = amount + 1;
int[] dp = new int[max];
Arrays.fill(dp, max);
dp[0] = 0;
for (int i = 1; i < max; i ++) {
for (int j = 0; j < coins.length; j ++) {
if (coins[j] <= i) {
dp[i] = Math.min(dp[i], dp[i - coins[j]] + 1);
}
}
}
return dp[amount] > amount ? -1 : dp[amount];
}
}给定两个单词 word1 和 word2,计算出将 word1 转换成 word2 所使用的最少操作数 。
你可以对一个单词进行如下三种操作:
- 插入一个字符
- 删除一个字符
- 替换一个字符
示例 1:
输入: word1 = "horse", word2 = "ros"
输出: 3
解释:
horse -> rorse (将 'h' 替换为 'r')
rorse -> rose (删除 'r')
rose -> ros (删除 'e')
示例 2:
输入: word1 = "intention", word2 = "execution"
输出: 5
解释:
intention -> inention (删除 't')
inention -> enention (将 'i' 替换为 'e')
enention -> exention (将 'n' 替换为 'x')
exention -> exection (将 'n' 替换为 'c')
exection -> execution (插入 'u')
代码
class Solution {
public int minDistance(String word1, String word2) {
//dp[i][j] word1的前i个字符替换到word2的前j个字符最少需要的步数
int m = word1.length();
int n = word2.length();
int[][] dp = new int[m + 1][n + 1];
for (int i = 0; i < m + 1; i ++) dp[i][0] = i;//word2长度为0 逐个删除
for (int i = 0; i < n + 1; i ++) dp[0][i] = i;//word1长度为0 逐个添加
for (int i = 1; i < m + 1; i ++) {
for (int j = 1; j < n + 1; j ++) {
if (word1.charAt(i - 1) == word2.charAt(j - 1)) {
dp[i][j] = dp[i - 1][j - 1];
} else {
//dp[i - 1][j]代表word1插入一个字符
//dp[i][j - 1]代表word1删除一个字符
//dp[i - 1][j - 1]代表word1替换一个字符
dp[i][j] = Math.min(Math.min(dp[i - 1][j], dp[i][j - 1]), dp[i - 1][j - 1]) + 1;
}
}
}
return dp[m][n];
}
}public class UnionFind {
/**
* 根数组 i = roots[j]代表j的根是i
* 规定根相同的元素属于同一集合
*/
private int[] roots;
/**
* 并查集的深度(从0开始)
*/
private int[] rank;
/**
* 初始化根数组,每个元素的根为自己
* @param N
*/
public UnionFind(int N) {
roots = new int[N];
for (int i = 0; i < N; i++) {
roots[i] = i;
}
}
/**
* 判断两个元素是否属于同一个集合,即根元素是否相同
* @param p
* @param q
* @return
*/
public boolean connected(int p, int q) {
return findRoot(p) == findRoot(q);
}
/**
* 将两个集合合并为1个集合
* @param p
* @param q
*/
public void union(int p, int q) {
int qroot = findRoot(q);
int proot = findRoot(p);
if (qroot != proot) {
//优化并查集,减少并查集的深度
if (rank[proot] > rank[qroot]) {
roots[qroot] = proot;
} else if (rank[proot] < rank[qroot]) {
roots[proot] = qroot;
} else {
roots[proot] = qroot;
rank[qroot] += 1;
}
}
}
/**
* 寻找指定元素的根元素
* @param i
* @return
*/
private int findRoot(int i) {
int root = i;
while (root != roots[root]) {
root = roots[root];
}
//优化并查集,将元素直接指向根元素,压缩路径
while (i != roots[i]) {
int tmp = roots[i];
roots[i] = root;
i = tmp;
}
return root;
}
}
给定一个由 '1'(陆地)和 '0'(水)组成的的二维网格,计算岛屿的数量。一个岛被水包围,并且它是通过水平方向或垂直方向上相邻的陆地连接而成的。你可以假设网格的四个边均被水包围。
示例 1:
输入:
11110
11010
11000
00000
输出: 1
示例 2:
输入:
11000
11000
00100
00011
输出: 3
代码
DFS
class Solution {
int count = 0;
int[] dx = {-1, 1, 0, 0};
int[] dy = {0, 0, -1, 1};
public int numIslands(char[][] grid) {
for (int i = 0; i < grid.length; i ++) {
for (int j = 0; j < grid[0].length; j ++) {
if (grid[i][j] == '1') {
count ++;
dfs(grid, i, j);
}
}
}
return count;
}
private void dfs(char[][] grid, int i, int j) {
if (valid(grid, i, j)) {
grid[i][j] = '0';
for (int k = 0; k < 4; k ++) {
dfs(grid, i + dx[k], j + dy[k]);
}
}
}
private boolean valid(char[][] grid, int i, int j) {
return i >= 0 && i < grid.length && j >=0 && j < grid[0].length && grid[i][j] == '1';
}
}并查集
class Solution {
public int numIslands(char[][] grid) {
if (grid == null || grid.length == 0) return 0;
UnionFind uf = new UnionFind(grid);
int[] dx = {-1, 1, 0, 0};
int[] dy = {0, 0, -1, 1};
int m = grid.length;
int n = grid[0].length;
for (int i = 0; i < m; i ++) {
for (int j = 0; j < n; j ++) {
if (grid[i][j] == '0') {
continue;
}
for (int k = 0; k < 4; k ++) {
int a = i + dx[k];
int b = j + dy[k];
if (valid(grid, a, b)) {
uf.union(i * n + j, a * n + b);
}
}
}
}
return uf.getCount();
}
private boolean valid(char[][] grid, int i, int j) {
return i >= 0 && i < grid.length && j >=0 && j < grid[0].length && grid[i][j] == '1';
}
}
class UnionFind {
private int count;
private int[] roots;
private int[] rank;
public UnionFind(char[][] grid) {
int m = grid.length;
int n = grid[0].length;
count = 0;
roots = new int[m * n];
rank = new int[m * n];
Arrays.fill(roots, -1);
for (int i = 0; i < m; i ++) {
for (int j = 0; j < n; j ++) {
if (grid[i][j] == '1') {
roots[i * n + j] = i * n + j;
count += 1;
}
}
}
}
public int getCount() {
return this.count;
}
public void union(int p, int q) {
int proot = find(p);
int qroot = find(q);
if (qroot != proot) {
if (rank[proot] > rank[qroot]) {
roots[qroot] = proot;
} else if (rank[proot] < rank[qroot]) {
roots[proot] = qroot;
} else {
roots[proot] = qroot;
rank[qroot] += 1;
}
count -= 1;
}
}
private int find(int i) {
int root = i;
while (root != roots[root]) {
root = roots[root];
}
while (i != roots[i]) {
int tmp = roots[i];
roots[i] = root;
i = tmp;
}
return root;
}
}班上有 N 名学生。其中有些人是朋友,有些则不是。他们的友谊具有是传递性。如果已知 A 是 B 的朋友,B 是 C 的朋友,那么我们可以认为 A 也是 C 的朋友。所谓的朋友圈,是指所有朋友的集合。
给定一个 N * N 的矩阵 M,表示班级中学生之间的朋友关系。如果M[i][j] = 1,表示已知第 i 个和 j 个学生互为朋友关系,否则为不知道。你必须输出所有学生中的已知的朋友圈总数。
示例 1:
输入:
[[1,1,0],
[1,1,0],
[0,0,1]]
输出: 2
说明:已知学生0和学生1互为朋友,他们在一个朋友圈。
第2个学生自己在一个朋友圈。所以返回2。
示例 2:
输入:
[[1,1,0],
[1,1,1],
[0,1,1]]
输出: 1
说明:已知学生0和学生1互为朋友,学生1和学生2互为朋友,所以学生0和学生2也是朋友,所以他们三个在一个朋友圈,返回1。
注意:
- N 在[1,200]的范围内。
- 对于所有学生,有
M[i][i] = 1。 - 如果有
M[i][j] = 1,则有M[j][i]= 1。
代码
DFS
class Solution {
int count = 0;
public int findCircleNum(int[][] M) {
int[] mark = new int[M.length];//用于存储朋友圈路径
for (int i = 0; i < M.length; i ++) {
if (mark[i] == 0) {
//0代表i没有加入到一个朋友圈,从该点开始,dfs找出他的所有朋友
count ++;
dfs(M, mark, i);//执行一次,构建一条朋友圈
}
}
return count;
}
private void dfs(int[][] M, int[] mark, int i) {
mark[i] = 1;//将i放到朋友圈
for (int j = 0; j < M[0].length; j ++) {
if (M[i][j] == 1 && mark[j] == 0) {
//如果i和j是朋友,但是j没有加入该朋友圈,dfs去构建朋友圈
dfs(M, mark, j);
}
}
}
}并查集
class Solution {
public int findCircleNum(int[][] M) {
UnionFind uf = new UnionFind(M);
int m = M.length;
int n = M[0].length;
for (int i = 0; i < m; i ++) {
for (int j = 0; j < n; j ++) {
if (M[i][j] == 1) {
//这里太暴力了,暂时没有优化,速度那是慢的一匹
//上面的dfs是优化过的,换了个思路,当然也可以按照下面暴力求解
for (int k = 0; k < m; k ++) {
if (M[k][j] == 1) {
uf.union(i * n + j, k * n + j);
}
}
for (int k = 0; k < n; k ++) {
if (M[i][k] == 1) {
uf.union(i * n + j, i * n + k);
}
}
}
}
}
return uf.getCount();
}
}
class UnionFind {
private int count;
private int[] roots;
private int[] rank;
public UnionFind(int[][] M) {
int m = M.length;
int n = M[0].length;
count = 0;
roots = new int[m * n];
rank = new int[m * n];
Arrays.fill(roots, -1);
for (int i = 0; i < m; i ++) {
for (int j = 0; j < n; j ++) {
if (M[i][j] == 1) {
roots[i * n + j] = i * n + j;
count += 1;
}
}
}
}
public int getCount() {
return this.count;
}
public void union(int p, int q) {
int proot = find(p);
int qroot = find(q);
if (qroot != proot) {
if (rank[proot] > rank[qroot]) {
roots[qroot] = proot;
} else if (rank[proot] < rank[qroot]) {
roots[proot] = qroot;
} else {
roots[proot] = qroot;
rank[qroot] += 1;
}
count -= 1;
}
}
private int find(int i) {
int root = i;
while (root != roots[root]) {
root = roots[root];
}
while (i != roots[i]) {
int tmp = roots[i];
roots[i] = root;
i = tmp;
}
return root;
}
}运用你所掌握的数据结构,设计和实现一个 LRU (最近最少使用) 缓存机制。它应该支持以下操作: 获取数据 get 和 写入数据 put 。
获取数据 get(key) - 如果密钥 (key) 存在于缓存中,则获取密钥的值(总是正数),否则返回 -1。
写入数据 put(key, value) - 如果密钥不存在,则写入其数据值。当缓存容量达到上限时,它应该在写入新数据之前删除最近最少使用的数据值,从而为新的数据值留出空间。
进阶:
你是否可以在 O(1) 时间复杂度内完成这两种操作?
示例:
LRUCache cache = new LRUCache( 2 /* 缓存容量 */ );
cache.put(1, 1);
cache.put(2, 2);
cache.get(1); // 返回 1
cache.put(3, 3); // 该操作会使得密钥 2 作废
cache.get(2); // 返回 -1 (未找到)
cache.put(4, 4); // 该操作会使得密钥 1 作废
cache.get(1); // 返回 -1 (未找到)
cache.get(3); // 返回 3
cache.get(4); // 返回 4
代码
class LRUCache {
private LinkedHashMap<Integer, Integer> map;
private int remain;
public LRUCache(int capacity) {
this.map = new LinkedHashMap<>(capacity);
this.remain = capacity;
}
public int get(int key) {
if (!map.containsKey(key)) return -1;
int v = map.remove(key);
map.put(key, v);
return v;
}
public void put(int key, int value) {
if (map.containsKey(key)) {
map.remove(key);
} else {
if (this.remain > 0) this.remain --;
else removeOldestEntry();
}
map.put(key, value);
}
private void removeOldestEntry() {
Iterator<Integer> it = this.map.keySet().iterator();
int oldestKey = -1;
if (it.hasNext()) {
oldestKey = it.next();
}
map.remove(oldestKey);
}
}
/**
* Your LRUCache object will be instantiated and called as such:
* LRUCache obj = new LRUCache(capacity);
* int param_1 = obj.get(key);
* obj.put(key,value);
*/