Add Real-Time License Plate Detector Example Project (YOLOv3, CRAFT, CRNN) #803
Conversation
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Member
|
@RobertLucian this is really awesome! I'll go through it now and let you know if I have any feedback, but on first glance it looks great. |
Member
Author
|
As agreed, the client has been moved to a separate repository here: For verifying that the deployed models work as expected on AWS w/ cortex, this half of the project has gotten a This verification is useful before going heavy with the client app from the other repo (check the above link). |
deliahu
approved these changes
Feb 19, 2020
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
3 participants
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
There will be a follow-up article in one or two days on this subject. I've linked the article in the README, but momentarily, it leads to a 404.
This PR contains the project I've been working on for the past few months.
It's a system, be it physical or purely software-based, to which a video stream can be fed into and in real time a feedback stream is broadcasted to the browser which contains overlayed boxes representing the detected/recognized license plates in traffic. If the license plate is also recognized, a text containing its recognition is placed adjacent to the bounding box.
Here's a video of it.
And here's how the embedded system is sitting on my car's rear-view mirror. Obviously, all these parts have been 3D printed - they are custom-built.
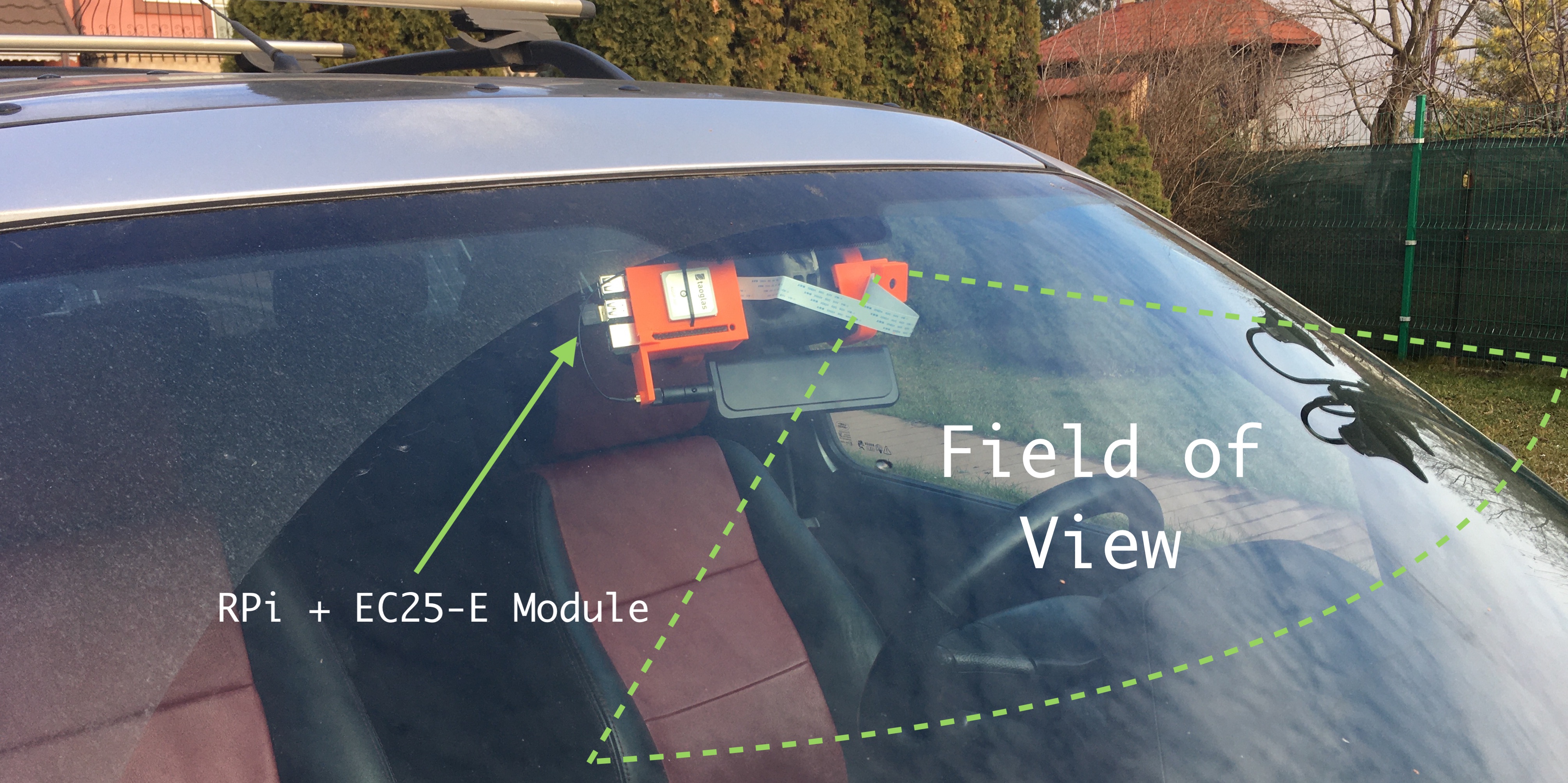
Other related photos about this project can be found here. I've uploaded them on imgur.
The video source for this app can either be a video file or a camera (more specifically, a Raspberry Pi Camera). The video file is treated as a continuous stream on which it must be acted immediately, much like a camera's port is. The video file support has been added for those that don't have a Raspberry Pi + Pi Camera + others laying around. I've also linked in a video you can download to experiment with.
The models used in this project are: YOLOv3, CRAFT text detector and CRNN text recognizer.
The only model which has been fine-tuned is the YOLOv3 one. I've generated a dataset by cruising around the town with my dashcam device and then fine-tuned the model to detect license plates. The dataset can be found here. The newly tuned model has been PRed to this repo and is now a part of it.
When it's working optimally (aka there are enough instances in the pool to handle a given amount of frames/s), the average latency I have experienced from the moment the frame is captured up until it's displayed in the browser (with all the bounding boxes and recognized texts) it takes about 0.5-0.7 seconds. The downside for now is that for a single stream going at 30 fps and a resolution of 480x270, about 20 GPU-equipped instances are required. If optimized (half precision, multiprocessed web API server, more vCPUs, tinyYOLOv3?), I wouldn't see why running a stream on a single instance wouldn't work (heck I think even 2 streams would be doable at that point on a single GPU).
Suggestion: the text recognition requests can be disabled within the app by leaving the CRNN API endpoint address empty (
""). Useful if you don't want to spin up that many GPUs.checklist:
make testandmake lintsummary.md(view in gitbook after merging)