-
Notifications
You must be signed in to change notification settings - Fork 32
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Upload new file: 搞懂容器技术的基石: namespace (上) | MoeLove.md via simpread
- Loading branch information
Showing
1 changed file
with
283 additions
and
0 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,283 @@ | ||
| > 本文由 [简悦 SimpRead](http://ksria.com/simpread/) 转码, 原文地址 [moelove.info](https://moelove.info/2021/12/10/%E6%90%9E%E6%87%82%E5%AE%B9%E5%99%A8%E6%8A%80%E6%9C%AF%E7%9A%84%E5%9F%BA%E7%9F%B3-namespace-%E4%B8%8A/) | ||
| > 大家好,我是张晋涛。 目前我们所提到的容器技术、虚拟化技术(不论何种抽象层次下的虚拟化技术)都能做到资源层面上的隔离和限制。 对于容…… | ||
| 大家好,我是张晋涛。 | ||
|
|
||
| 目前我们所提到的容器技术、虚拟化技术(不论何种抽象层次下的虚拟化技术)都能做到资源层面上的隔离和限制。 | ||
|
|
||
| 对于容器技术而言,它实现资源层面上的限制和隔离,依赖于 Linux 内核所提供的 cgroup 和 namespace 技术。 | ||
|
|
||
| 我们先对这两项技术的作用做个概括: | ||
|
|
||
| * cgroup 的主要作用:管理资源的分配、限制; | ||
| * namespace 的主要作用:封装抽象,限制,隔离,使命名空间内的进程看起来拥有他们自己的全局资源; | ||
|
|
||
| [在上一篇文章中,我们重点聊了 cgroup](https://zhuanlan.zhihu.com/p/434731896) 。本篇,我们重点来聊 namespace 。 | ||
|
|
||
| [](#namespace-是什么)[Namespace 是什么?](#contents:namespace-是什么) | ||
| ----------------------------------------------------------- | ||
|
|
||
| 我们引用 [wiki](https://en.wikipedia.org/wiki/Linux_namespaces) 上对 namespace 的定义: | ||
|
|
||
| > Namespaces are a feature of the Linux kernel that partitions kernel resources such that one set of processes sees one set of resources while another set of processes sees a different set of resources. The feature works by having the same namespace for a set of resources and processes, but those namespaces refer to distinct resources. | ||
| namespace 是 Linux 内核的一项特性,它可以对内核资源进行分区,使得一组进程可以看到一组资源;而另一组进程可以看到另一组不同的资源。该功能的原理是为一组资源和进程使用相同的 namespace,但是这些 namespace 实际上引用的是不同的资源。 | ||
|
|
||
| 这样的说法未免太绕了些,简单来说 namespace 是由 Linux 内核提供的,用于进程间资源隔离的一种技术。将全局的系统资源包装在一个抽象里,让进程(看起来)拥有独立的全局资源实例。同时 Linux 也默认提供了多种 namespace,用于对多种不同资源进行隔离。 | ||
|
|
||
| 在之前,我们单独使用 namespace 的场景比较有限,但 namespace 却是容器化技术的基石。 | ||
|
|
||
| 我们先来看看它的发展历程。 | ||
|
|
||
| [](#namespace-的发展历程)[Namespace 的发展历程](#contents:namespace-的发展历程) | ||
| ---------------------------------------------------------------- | ||
|
|
||
|  | ||
|
|
||
| **图 1 ,namespace 的历史过程** | ||
|
|
||
| ### [](#最早期---plan-9)[最早期 - Plan 9](#contents:最早期---plan-9) | ||
|
|
||
| namespace 的早期提出及使用要追溯到 Plan 9 from Bell Labs ,贝尔实验室的 Plan 9。这是一个分布式操作系统,由贝尔实验室的计算科学研究中心在八几年至 02 年开发的(02 年发布了稳定的第四版,距离 92 年发布的第一个公开版本已 10 年打磨),现在仍然被操作系统的研究者和爱好者开发使用。在 Plan 9 的设计与实现中,我们着重提以下 3 点内容: | ||
|
|
||
| * 文件系统:所有系统资源都列在文件系统中,以 Node 标识。所有的接口也作为文件系统的一部分呈现。 | ||
|
|
||
| * Namespace:能更好的应用及展示文件系统的层次结构,它实现了所谓的 “分离” 和 “独立”。 | ||
|
|
||
| * 标准通信协议:9P 协议(Styx/9P2000)。 | ||
|
|
||
|
|
||
|  | ||
|
|
||
| **图 2 ,Plan 9 from Bell Labs 图标** | ||
|
|
||
| ### [](#开始加入-linux-kernel)[开始加入 Linux Kernel](#contents:开始加入-linux-kernel) | ||
|
|
||
| Namespace 开始进入 Linux Kernel 的版本是在 2.4.X,最初始于 2.4.19 版本。但是,自 2.4.2 版本才开始实现每个进程的 namespace。 | ||
|
|
||
|  | ||
|
|
||
| **图 3 ,Linux Kernel Note** | ||
|
|
||
|  | ||
|
|
||
| **图 4 ,Linux Kernel 对应的各操作系统版本** | ||
|
|
||
| ### [](#linux-38-基本实现)[Linux 3.8 基本实现](#contents:linux-38-基本实现) | ||
|
|
||
| Linux 3.8 中终于完全实现了 `User` Namespace 的相关功能集成到内核。这样 Docker 及其他容器技术所用到的 namespace 相关的能力就基本都实现了。 | ||
|
|
||
| 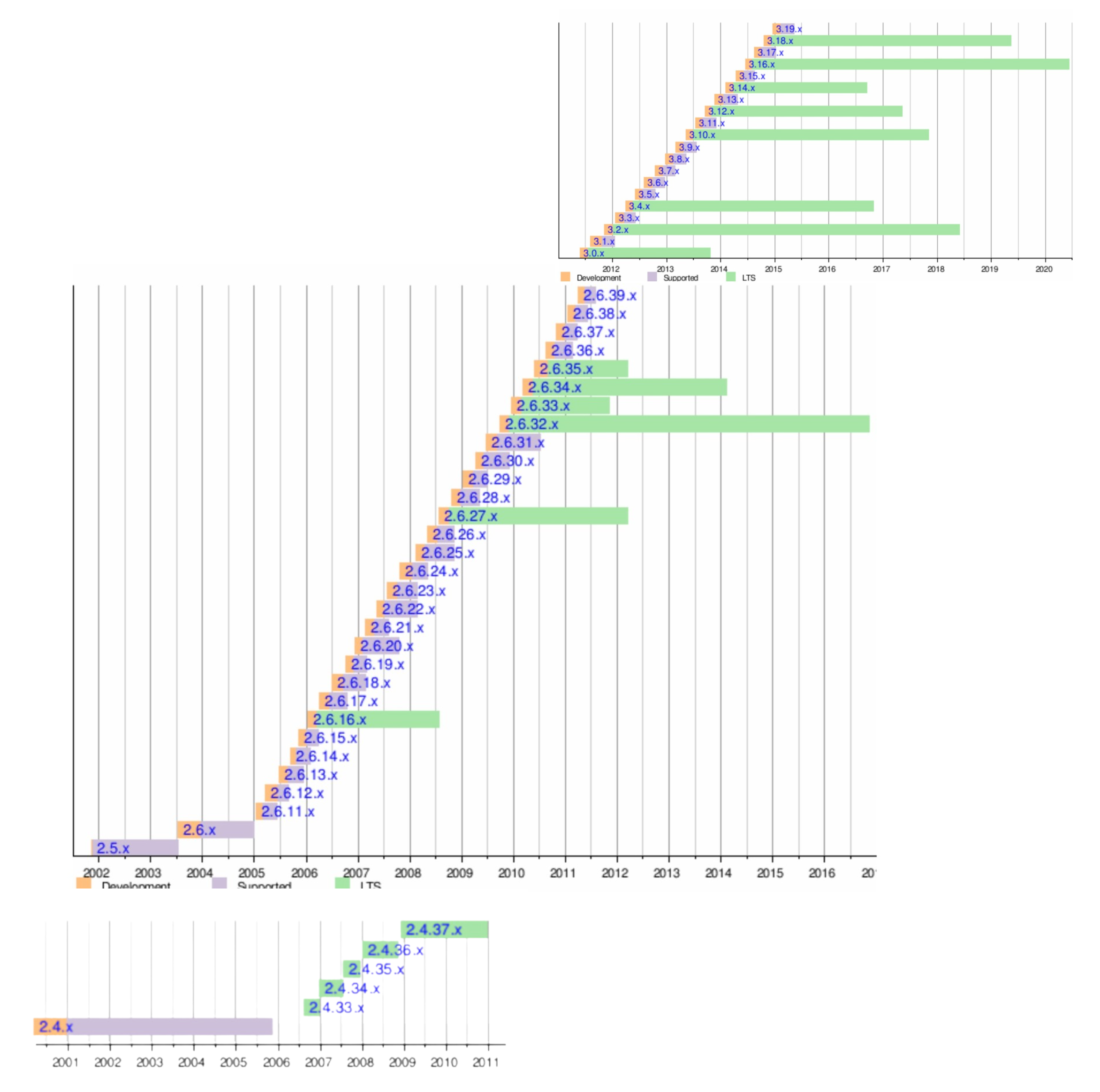 | ||
|
|
||
| **图 5 ,Linux Kernel 从 2001 到 2013 逐步演变,完成了 namespace 的实现** | ||
|
|
||
| [](#namespace-类型)[Namespace 类型](#contents:namespace-类型) | ||
| ------------------------------------------------------- | ||
|
|
||
| <table><thead><tr><th>namespace 名称</th><th>使用的标识 - Flag</th><th>控制内容</th></tr></thead><tbody><tr><td>Cgroup</td><td>CLONE_NEWCGROUP</td><td>Cgroup root directory cgroup 根目录</td></tr><tr><td>IPC</td><td>CLONE_NEWIPC</td><td>System V IPC, POSIX message queues 信号量,消息队列</td></tr><tr><td>Network</td><td>CLONE_NEWNET</td><td>Network devices, stacks, ports, etc. 网络设备,协议栈,端口等等</td></tr><tr><td>Mount</td><td>CLONE_NEWNS</td><td>Mount points 挂载点</td></tr><tr><td>PID</td><td>CLONE_NEWPID</td><td>Process IDs 进程号</td></tr><tr><td>Time</td><td>CLONE_NEWTIME</td><td>时钟</td></tr><tr><td>User</td><td>CLONE_NEWUSER</td><td>用户和组 ID</td></tr><tr><td>UTS</td><td>CLONE_NEWUTS</td><td>系统主机名和 NIS(Network Information Service) 主机名(有时称为域名)</td></tr></tbody></table> | ||
|
|
||
| ### [](#cgroup-namespaces)[Cgroup namespaces](#contents:cgroup-namespaces) | ||
|
|
||
| Cgroup namespace 是进程的 cgroups 的虚拟化视图,通过 `/proc/[pid]/cgroup` 和 `/proc/[pid]/mountinfo` 展示。 | ||
|
|
||
| 使用 cgroup namespace 需要内核开启 `CONFIG_CGROUPS` 选项。可通过以下方式验证: | ||
|
|
||
| ``` | ||
| (MoeLove) ➜ grep CONFIG_CGROUPS /boot/config-$(uname -r) | ||
| CONFIG_CGROUPS=y | ||
| ``` | ||
|
|
||
| cgroup namespace 提供的了一系列的隔离支持: | ||
|
|
||
| * 防止信息泄漏(容器不应该看到容器外的任何信息)。 | ||
|
|
||
| * 简化了容器迁移。 | ||
|
|
||
| * 限制容器进程资源,因为它会把 cgroup 文件系统进行挂载,使得容器进程无法获取上层的访问权限。 | ||
|
|
||
|
|
||
| 每个 cgroup namespace 都有自己的一组 cgroup 根目录。这些 cgroup 的根目录是在 `/proc/[pid]/cgroup` 文件中对应记录的相对位置的基点。当一个进程用 `CLONE_NEWCGROUP`(clone(2) 或者 unshare(2)) 创建一个新的 cgroup namespace 时,它当前的 cgroups 的目录就变成了新 namespace 的 cgroup 根目录。 | ||
|
|
||
| ``` | ||
| (MoeLove) ➜ cat /proc/self/cgroup | ||
| 0::/user.slice/user-1000.slice/session-2.scope | ||
| ``` | ||
|
|
||
| 当一个目标进程从 `/proc/[pid]/cgroup` 中读取 cgroup 关系时,每个记录的路径名会在第三字段中展示,会关联到正在读取的进程的相关 cgroup 分层结构的根目录。如果目标进程的 cgroup 目录位于正在读取的进程的 cgroup namespace 根目录之外时,那么,路径名称将会对每个 cgroup 层次中的上层节点显示 `../` 。 | ||
|
|
||
| 我们来看看下面的示例(这里以 cgroup v1 为例,如果你想看 v2 版本的示例,请在留言中告诉我): | ||
|
|
||
| 1. 在初始的 cgroup namespace 中,我们使用 root (或者有 root 权限的用户),在 freezer 层下创建一个子 cgroup 名为 `moelove-sub`,同时,将进程放入该 cgroup 进行限制。 | ||
|
|
||
| ``` | ||
| (MoeLove) ➜ mkdir -p /sys/fs/cgroup/freezer/moelove-sub | ||
| (MoeLove) ➜ sleep 6666666 & | ||
| [1] 1489125 | ||
| (MoeLove) ➜ echo 1489125 > /sys/fs/cgroup/freezer/moelove-sub/cgroup.procs | ||
| ``` | ||
|
|
||
| 2. 我们在 freezer 层下创建另外一个子 cgroup,名为 `moelove-sub2`, 并且再放入执行进程号。可以看到当前的进程已经纳入到 `moelove-sub2`的 cgroup 下管理了。 | ||
|
|
||
| ``` | ||
| (MoeLove) ➜ mkdir -p /sys/fs/cgroup/freezer/moelove-sub2 | ||
| (MoeLove) ➜ echo $$ | ||
| 1488899 | ||
| (MoeLove) ➜ echo 1488899 > /sys/fs/cgroup/freezer/moelove-sub2/cgroup.procs | ||
| (MoeLove) ➜ cat /proc/self/cgroup |grep freezer | ||
| 7:freezer:/moelove-sub2 | ||
| ``` | ||
|
|
||
| 3. 我们使用 `unshare(1)` 创建一个进程,这里使用了 `-C`参数表示是新的 cgroup namespace, 使用了 `-m`参数表示是新的 mount namespace。 | ||
|
|
||
| 4. 从用 unshare(1) 启动的新 shell 中,我们可以在 `/proc/[pid]/cgroup` 文件中看到,新 shell 和以上示例中的进程: | ||
|
|
||
| 5. 从上面的示例中,我们可以看到新 shell 的 freezer cgroup 关系中,当新的 cgroup namespace 创建时,freezer cgroup 的根目录与它的关系也就建立了。 | ||
|
|
||
| ``` | ||
| [email protected]:~# cat /proc/self/mountinfo | grep freezer | ||
| 1238 1230 0:37 /.. /sys/fs/cgroup/freezer rw,nosuid,nodev,noexec,relatime - cgroup cgroup rw,freezer | ||
| ``` | ||
|
|
||
| 6. 第四个字段 ( `/..`) 显示了在 cgroup 文件系统中的挂载目录。从 cgroup namespaces 的定义中,我们可以知道,进程当前的 freezer cgroup 目录变成了它的根目录,所以这个字段显示 `/..` 。我们可以重新挂载来处理它。 | ||
|
|
||
| ### [](#ipc-namespaces)[IPC namespaces](#contents:ipc-namespaces) | ||
|
|
||
| IPC namespaces 隔离了 IPC 资源,如 System V IPC objects、 POSIX message queues。每个 IPC namespace 都有着自己的一组 System V IPC 标识符,以及 POSIX 消息队列系统。在一个 IPC namespace 中创建的对象,对所有该 namespace 下的成员均可见(对其他 namespace 下的成员均不可见)。 | ||
|
|
||
| 使用 IPC namespace 需要内核支持 CONFIG_IPC_NS 选项。如下: | ||
|
|
||
| ``` | ||
| (MoeLove) ➜ grep CONFIG_IPC_NS /boot/config-$(uname -r) | ||
| CONFIG_IPC_NS=y | ||
| ``` | ||
|
|
||
| 可以在 IPC namespace 中设置以下 `/proc` 接口: | ||
|
|
||
| * `/proc/sys/fs/mqueue` - POSIX 消息队列接口 | ||
|
|
||
| * `/proc/sys/kernel` - System V IPC 接口 (msgmax, msgmnb, msgmni, sem, shmall, shmmax, shmmni, shm_rmid_forced) | ||
|
|
||
| * `/proc/sysvipc` - System V IPC 接口 | ||
|
|
||
|
|
||
| 当 IPC namespace 被销毁时(空间里的最后一个进程都被停止删除时),在 IPC namespace 中创建的 object 也会被销毁。 | ||
|
|
||
| ### [](#network-namepaces)[Network namepaces](#contents:network-namepaces) | ||
|
|
||
| Network namespaces 隔离了与网络相关的系统资源(这里罗列一些): | ||
|
|
||
| * network devices - 网络设备 | ||
|
|
||
| * IPv4 and IPv6 protocol stacks - IPv4、IPv6 的协议栈 | ||
|
|
||
| * IP routing tables - IP 路由表 | ||
|
|
||
| * firewall rules - 防火墙规则 | ||
|
|
||
| * /proc/net (即 /proc/PID/net) | ||
|
|
||
| * /sys/class/net | ||
|
|
||
| * /proc/sys/net 目录下的文件 | ||
|
|
||
| * 端口、socket | ||
|
|
||
| * UNIX domain abstract socket namespace | ||
|
|
||
|
|
||
| 使用 Network namespaces 需要内核支持 CONFIG_NET_NS 选项。如下: | ||
|
|
||
| ``` | ||
| (MoeLove) ➜ grep CONFIG_NET_NS /boot/config-$(uname -r) | ||
| CONFIG_NET_NS=y | ||
| ``` | ||
|
|
||
| 一个物理网络设备只能存在于一个 Network namespace 中。当一个 Network namespace 被释放时(空间里的最后一个进程都被停止删除时),物理网络设备将被移动到初始的 Network namespace 而不是上层的 Network namespace。 | ||
|
|
||
| 一个虚拟的网络设备 (veth(4)) ,在 Network namespace 间通过一个类似管道的方式进行连接。这使得它能存在于多个 Network namespace,但是,当 Network namespace 被摧毁时,该空间下包含的 veth(4) 设备可能被破坏。 | ||
|
|
||
| ### [](#mount-namespaces)[Mount namespaces](#contents:mount-namespaces) | ||
|
|
||
| Mount namespaces 最早出现在 Linux 2.4.19 版本。Mount namespaces 隔离了各空间中挂载的进程实例。每个 mount namespace 的实例下的进程会看到不同的目录层次结构。 | ||
|
|
||
| 每个进程在 mount namespace 中的描述可以在下面的文件视图中看到: | ||
|
|
||
| * `/proc/[pid]/mounts` | ||
|
|
||
| * `/proc/[pid]/mountinfo` | ||
|
|
||
| * `/proc/[pid]/mountstats` | ||
|
|
||
|
|
||
| 一个新的 Mount namespace 的创建标识是 CLONE_NEWNS ,使用了 clone(2) 或者 unshare(2) 。 | ||
|
|
||
| * 如果 Mount namespace 用 clone(2) 创建,子 namespace 的挂载列表是从父进程的 mount namespace 拷贝的。 | ||
| * 如果 Mount namespace 用 unshare(2) 创建,新 namespace 的挂载列表是从调用者之前的 moun namespace 拷贝的。 | ||
|
|
||
| 如果 mount namespace 发生了修改,会引起什么样的连锁反应?下面,我们就在 **共享子树**中谈谈。 | ||
|
|
||
| 每个 mount 都被可以有如下标记 : | ||
|
|
||
| * MS_SHARED - 与组内每个成员分享 events 。也就是说相同的 mount 或者 unmount 将自动发生在组内其他的 mounts 中。反之,mount 或者 unmount 事件 也会影响这次的 event 动作。 | ||
|
|
||
| * MS_PRIVATE - 这个 mount 是私有的。mount 或者 unmount events 都不会影响这次的 event 动作。 | ||
|
|
||
| * MS_SLAVE - mount 或者 unmount events 会从 master 节点传入影响该节点。但是这个节点下的 mount 或者 unmount events 不会影响组内的其他节点。 | ||
|
|
||
| * MS_UNBINDABLE - 这也是个私有的 mount 。任何尝试绑定的 mount 在这个设置下都将失败。 | ||
|
|
||
|
|
||
| 在文件 `/proc/[pid]/mountinfo` 中可以看到 `propagation` 类型的字段。每个对等组都会由内核生成唯一的 ID ,同一对等组的 mount 都是这个 ID(即,下文中的 X )。 | ||
|
|
||
| ``` | ||
| (MoeLove) ➜ cat /proc/self/mountinfo |grep root | ||
| 65 1 0:33 /root / rw,relatime shared:1 - btrfs /dev/nvme0n1p6 rw,seclabel,compress=zstd:1,ssd,space_cache,subvolid=256,subvol=/root | ||
| 1210 65 0:33 /root/var/lib/docker/btrfs /var/lib/docker/btrfs rw,relatime shared:1 - btrfs /dev/nvme0n1p6 rw,seclabel,compress=zstd:1,ssd,space_cache,subvolid=256,subvol=/root | ||
| ``` | ||
|
|
||
| * shared:X - 在组 X 中共享。 | ||
|
|
||
| * master:X - 对于组 X 而言是 slave,即,从属于 ID 为 X 的主。 | ||
|
|
||
| * propagate_from:X - 接收从组 X 发出的共享 mount。这个标签总是个 master:X 一同出现。 | ||
|
|
||
| * unbindable - 表示不能被绑定,即,不与其他关联从属。 | ||
|
|
||
|
|
||
| 新 mount namespace 的传播类型取决于它的父节点。如果父节点的传播类型是 MS_SHARED ,那么新 mount namespace 的传播类型是 MS_SHARED ,不然会默认为 MS_PRIVATE。 | ||
|
|
||
| 关于 mount namespaces 我们还需要注意以下几点: | ||
|
|
||
| (1)每个 mount namespace 都有一个 owner user namespace。如果新的 mount namespace 和拷贝的 mount namespace 分属于不同的 user namespace ,那么,新的 mount namespace 优先级低。 | ||
|
|
||
| (2)当创建的 mount namespace 优先级低时,那么,slave 的 mount events 会优先于 shared 的 mount events。 | ||
|
|
||
| (3)高优先级和低优先级的 mount namespace 有关联被锁定在一起时,他们都不能被单独卸载。 | ||
|
|
||
| (4)mount(2) 标识和 atime 标识会被锁定,即,不能被传播影响而修改。 | ||
|
|
||
| [](#小结)[小结](#contents:小结) | ||
| ------------------------- | ||
|
|
||
| 以上就是关于 Linux 内核中 namespace 的一些介绍了,篇幅原因,剩余部分以及 namespace 在容器中的应用我们放在下一篇中介绍,敬请期待! | ||
|
|
||
| 欢迎订阅我的文章公众号【MoeLove】 | ||
|
|
||
|  |