
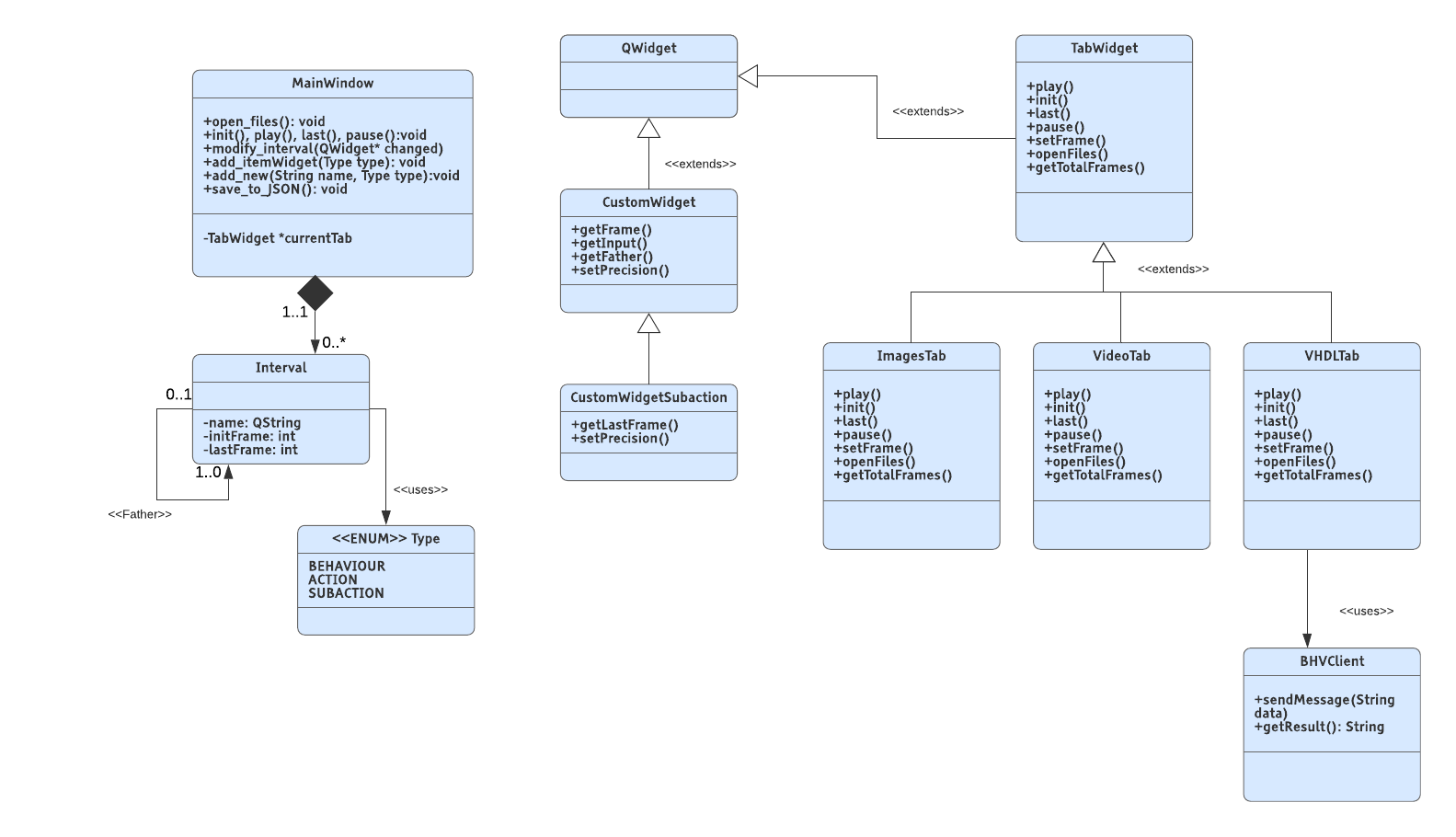
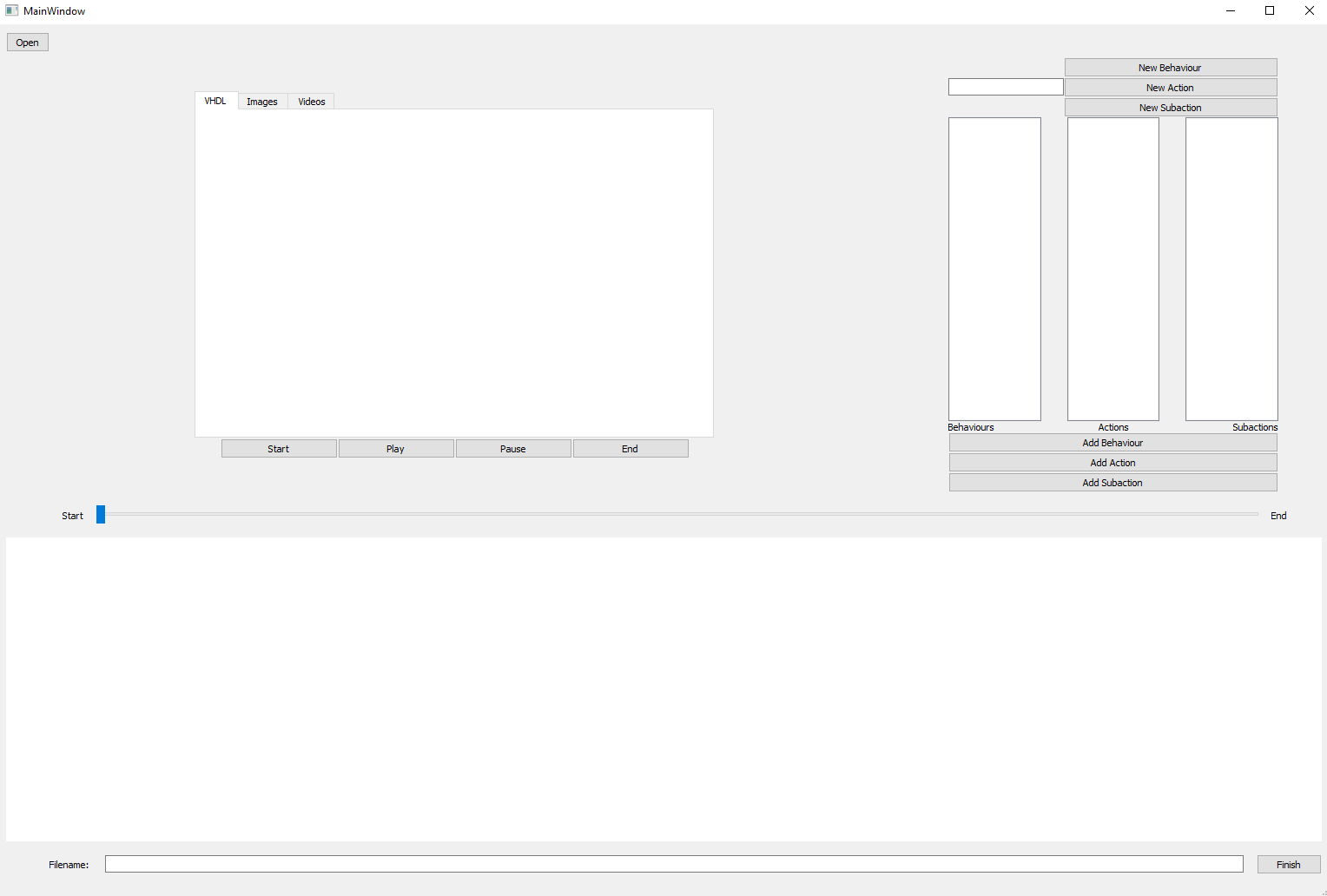
This is a Qt project that makes possible to give a frame annotation level, reporting in each frame which behaviour, action and subaction is happening. As result, a behaviour analysis dataset is obtained. This information can be used to train Deep Learning or classical oriented algorithms.
There are a maximum of three action tagging levels, meaning that the tool can create a hierarchy of actions of height 3: behavior, actions and subactions. The behavior is composed by actions, and for accomplishing those actions, many subactions are defined. For example, a behavior could be making a tea. All the actions would be: moving the cup from place to place, warm water, filling it...etc. In the case on moving cup from place, resulting subactions are: moving left arm up, closing left hand...etc.
When we are dealing with Deep learning, it is interesting to have a big amount of diverse data. If the data lacks of variability, the training process would be difficult to succeed. Data augmentation is one of the best techniques to improve data by incorporating variation. We propose an extension of the Action Manual Tagger which returns augmented data.

For example, with this video data augmentation pipeline, one possible variation is changing image contrast to make the DL model invariant to light changes. Furthermore, the use of shifts, rotations and cropping can help the data to be more spatially varied. Applying this operations, the neural network trained with this data learns not to focus to fixed locations of an image.
The video data augmentation is an extension of applying image data augmentation over the same frames of a full video. Each operation processed over the first frame is also applied to the rest of the video. Therefore, the typical operations over images can be used on videos as well : rotation, translation, vertical and horizontal flip, cropping, changes in brightness, add noise or blur, among others.
