Add share_reapply task - ON DEMAND for data.all admins #1151
Conversation
backend/dataall/modules/dataset_sharing/tasks/share_reapplier_task.py
Outdated
Show resolved
Hide resolved
|
Hi @noah-paige where do you think we should include the documentation about this feature? In the userguide, in the github pages or in both? I was going to go for both |
Can't hurt to do both! I was thinking definitely in the UserGuide under the shares page where we have a section discussing verify and re-apply of shares For GH Pages if you think there is a good place to add docs as well I think it would be helpful |
There was a problem hiding this comment.
Tested deploy and running the reapply task on demand - all looks good!
Ideally we would have a way to default to the correct VPC, Private Subnet, and Security Group selections but looking at CDK docs I am not sure that is possible
As long as we have good documentation of how to run task ad-hoc and how to retrieve the network configuration (maybe via SSM getParam calls?) then I think we are good with this issue
|
…1064) ### Feature or Bugfix IMPORTANT -⚠️ ⚠️ ⚠️ IMPORTANT: Users MUST upgrade their data.all Environments and Datasets if they want to enable multiple_environments_same_account pivot roles! We need to make it very clear in the release notes. Otherwise a good hint that indicates if an environment is updated is that when opening the Environment/Stack tab they get an error of the type: `An error occurred (AWSResourceNotFound) when calling GET_STACK_LOGS operation: Logs could not be found for this stack` -⚠️ ⚠️ ⚠️ IMPORTANT: For data.all **CREATED** datasets, this PR introduces a change in the IaC that BREAKS the KMS policy for folder and bucket sharing. The share will appear as unhealthy if we verify it and will be fixed by re-applying the share. To automate this process we recommend users to: - 1. Update data.all to new version - 2. Update all Environment and Dataset stacks - 3. trigger the `share-verifier` task in ECS - 4. trigger the `share-reapplier` task in ECS introduced in PR #1151 -⚠️ After upgrading, there will be some useless LakeFormation permissions granting permissions to the deleted `dataallPivotRole-cdk` because LakeFormation does not delete the permissions of deleted IAM roles. In addition, Lake Formation keeps the old pivot role as datalake admin flagged as invalid (see pic below). The permissions do not really harm anyone and can be deleted manually. If you are a user and are struggling cleaning-up or wish more support, please open a GitHub issue referencing this PR and we will address your challenges.  ### Detail #### Problem statement data.all =<2.2.0 is not designed to allow the creation of multiple data.all Environments in the same AWS account. However, there are customers that store and work with data in the same AWS account but in different regions. This PR is meant to enable that use-case solving its 2 blockers: - If using cdk-pivot roles, the second environment stack fails to deploy because there is already an existing dataallPivotRole-cdk IAM role created in the first environment stack. Explained in detail: #936 - If using manually created pivot roles, there is a limit ~5regions that can be onboarded. The failure is caused by the inline policies that CDK adds to the pivot role for the DLQ SQS queues and X-trace. Explained in detail: #1048 ## Design Our recommendation is to use cdk-created pivot roles because their policies can be more restrictive and manual errors of deploying CFN stacks are avoided. To solve #936 and use CDK pivot role in a multi-environment same account setup we have 2 options: 1. re-use the same IAM pivot role for all environments in the account: environment 1 deploys the pivot role nested stack and the subsequent environments detect that there is an IAM pivot role already created and use the existing one. The main advantage is its simplicity, we keep using the same IAM role and there is no need for backwards compatibility or changes in the code to assume a different role. But it has some important drawbacks: - it does not solve #1048 - issues with deletion of environment 1 ---> handle environment 2 updates. Environments depend on each other :'( - permissions of the pivot role refer to environment datasets.... ---> how will the pivot role get updated for other environments?? Not as simple as it looks. 2. deploy one IAM pivot role for each environment. Each environment deploys a separate pivot role stack. All role assumption boto3 calls need to be updates to use a different pivot role depending on the environment. It keeps each pivot role restricted to its environment, there is no coupling between environments and no #1048 policy limit issues. As disadvantages we can point out: - more code changes, passing info between calls and boto3 methods - backwards compatibility with original `dataallPivotRole-cdk` role. #### Design decisions Despite having disadvantages, this PR implements option 2 because it is more robust in the long-term. It also has advantages in terms of security as it "isolates" regions; we can take it further an define pivot role policies with the specified region. In addition, we reduce the impact of IAM size service quotas as each role is dedicated to one environment only. To minimize the code changes and impact, I have used the `region` to differentiate between pivot roles in the same account. At first I added the `environmentUri` to the pivot role name, but it made it very difficult to use in the boto3 `aws` clients. We would need to modify all the client calls to input the `environmentUri`. That's why I re-used the `region` which was already a parameter of most clients. This PR does not handle multiple environments using the manual pivot role. Meaning that it does not expect that each environment has a dedicated `dataallPivotRole-region`. It works as usual with one `dataallPivotRole` for all environments. We want to favor CDK-pivot roles and slowly move away from manual pivot roles. #### Backwards compatibility As preventive measurement, this PR introduces a `config.json` parameter to configure the usage of `cdk_pivot_role_multiple_environments_same_account`. The default value is `False`, thus the changes introduced in this PR are not mandatory and customers can migrate whenever they have the need. UPDATE FROM REVIEW: If we see that the backwards compatibility is smooth we will discard the parameter. This is a good enhancement and does not remove any functionality for customers. ## TESTING On an existing deployment with 2 environments and datasets (imported and created) and multiple shares, update the codebase. All modules are active and enabled in the environments. Part 1: `dataallPivotRole-cdk` continues working - [X] Update environment with no parameter `cdk_pivot_role_multiple_environments_same_account`--> check it updates and keeps deploying the `dataallPivotRole-cdk` - [X] Update environment with `cdk_pivot_role_multiple_environments_same_account`= `False` --> check it keeps deploying the `dataallPivotRole-cdk` - [X] Check IAM permissions of dataallPivotRole-cdk`(still contain KMS and S3 statements relative to imported dataset) and ensure it is the LF admin and has dataset permissions in LF. - [x] Create new dataset --> check new permissions are added to `dataallPivotRole-cdk` - [X] CloudFormation get stack (in Environment view) --> boto3 calls use the remote_session pointing at `dataallPivotRole-cdk` Part 2: `dataallPivotRole-cdk-region` migration infrastructure - [X] change `cdk_pivot_role_multiple_environments_same_account`to `True` and update environment. Environment updates the pivot role stack and creates NEW `dataallPivotRole-cdk-region` - as expected, in CloudFormation we see the message `Requested update requires the creation of a new physical resource; hence creating one` - [X] IAM permissions of `dataallPivotRole-cdk-region` --> check that imported datasets in the environment are present in the policy statements - [X] Ensure `dataallPivotRole-cdk-region` is a LF admin - it happens right after environment update - [X] Update created dataset stack and check that `dataallPivotRole-cdk-region` has LF permissions to the dataset. Check that KMS key policy includes the new pivot role. Finally check that the trust policy of the dataset IAM role includes the new pivot role:  - [X] Update imported dataset stack and check that `dataallPivotRole-cdk-region` has LF permissions to the dataset. Bucket policy and KMS policies are not managed by data.all in the creation of dataset. Finally check that the trust policy of the dataset IAM role includes the new pivot role  Part 3: `dataallPivotRole-cdk-region` migration data sharing - [X] Click on verify permissions for one of the shares (imported dataset) --->⚠️ verification shows table as unhealthy, folder appears as healthy. When users click on re-apply share, it grants permissions to the new pivot role in the cross account database and resource link and it appears as healthy again. See detail in Issues found section. - [X] Add new table to share in the same share --> check that share is successful - [X] Add bucket to share --> check that share is successful - KMS policy contains new pivot role! - [X] Revoke one table --> check share is successful - to ensure LF permissions work - [X] Revoke one folder --> check share is successful - to ensure LF permissions work - [X] Revoke one bucket --> check share is successful - to ensure LF permissions work - [X] click on verify permissions in the other share (created dataset) -->⚠️ in the dataset_stack, the KMS key policy has been wiped out, so bucket and access point shares are unhealthy!  (This part is fixed, see details below) After re-applying shares:  ` Failed to get kms key id of alias/loc-new-uqo3m5oh: An error occurred (AccessDeniedException) when calling the DescribeKey operation: User: arn:aws:sts::796821004569:assumed-role/dataallPivotRole-cdk-eu-west-1/dataallPivotRole-cdk-eu-west-1 is not authorized to perform: kms:DescribeKey on resource: arn:aws:kms:eu-west-1:796821004569:key/d00a9763-7fd0-4845-81d6-863d20714888 because no resource-based policy allows the kms:DescribeKey action` Part4: `dataallPivotRole-cdk-region` in boto3 calls - especially IAM and Quicksight that required some additional development. - [X] IAM - Add consumption role and check its policies attached - [X] CloudFormation - get stack logs in any Stack tab - check client - [X] Athena dataset client - Preview table - [X] Glue dataset client - Start crawler - [X] Glue profiling client - Run profiling job --> it triggers the profiling job but there is an issue unrelated to this PR related to the profiling script int he S3 bucket of the environment: `key: profiling/code/jars/deequ-2.0.0-spark-3.1.jar.The specified key does not exist` - [X] S3 location client - Create folder - check that s3 prefix gets created in S3 - [X] S3 dataset client - Get Dataset AWS creds - also checks that the dataset role can be assumed by the new pivot role --> for backwards compatibility dataset stack MUST be updated. - [X] LF dataset clients + S3 bucket policy client - Create Dataset - [X] IAM + data sharing clients (KMS, LF, RAM, S3, GLUE) - Share new items, revoke items, create new share. --> same error on KMS key for bucket share. - [x] Quicksight - Create Quicksight session in dashboards - it checks not only the client but the Quicksight identity region - [ ] SageMaker Notebooks - create and open Notebook 🔴 Error: 'Could not find any VPCs matching...' it fails on creation - [X] SageMaker ML Studio + EC2 base client - create and open ML Studio user - [X] Athena - run query in Worksheets - [ ] Remote session in Pipelines - Create Pipeline 2 types: CDK and non-CDK (tested below) Additional testing in AWS + support PRs (Update April 8th) - deploy #1151 as well - [X] Deploy in AWS CICD pipeline succeeds - [x] Revoke shared bucket without verify/reapply (after update environments and datasets) - [x] Revoke shared folder without verify/reapply (after update environments and datasets) - [x] Revoke shared table without verify/reapply (after update environments and datasets) - I checked the logs and before the revoke it grants the pivot role permissions to the db - [X] Verify shared table succeeds and does not fail because of missing pivot role permissions (test Fix in PR: #1149 ) - [X] Deploy #1150 - Verify shared folder and bucket shows unhealthy for data.all created datasets, admins go to data.all and trigger ECS task share-reapplier, verify shared folder and bucket again, it should be healthy (Test #1150) 🚀 I triggered the share-verifier task manually and only the expected broken shares (created datasets - folder/bucket sharing) appeared as unhealthy Other less important items - open issues if needed - [X] Test Notebooks --> all good, it must have been something related to my local environment - [X] Test Pipelines --> all good we can get credentials - [ ] Test profiling jobs ---> another different error `ImportError: cannot import name 'ColumnProfilerRunner' from 'awsglue.transforms' (/opt/amazon/lib/python3.6/site-packages/awsglue/transforms/__init__.py)` --> open github issue ### Open Issues, remarks and questions - [X] ISSUE TO FIX: Folder and bucket permissions get wiped out when the dataset stacks get updated with the new KMS statements (see the issues above). Users need to re-apply the shares because after the upgrade they will be broken.⚠️ in order for this PR to be released we need to implement some ECS task or automation to re-apply all failed shares ---> [Issue](#1150) Using PR #1151 this issue can be remediated - [X] TO DECIDE: Should we make this feature configurable? If so, what is the deprecation timeline for `dataallPivotRole-cdk`? ---> At the moment: Yes, this can be configured so that users can decide when to do the upgrade. We will use the maintenance window implementation to update users about this change. - [X] ISSUE TO FIX: Bucket sharing or folder sharing in testing part3 will fail for imported datasets because the statement in the KMS policy `DATAALL_KMS_PIVOT_ROLE_PERMISSIONS_SID` is skipped in `dataall/modules/dataset_sharing/services/share_managers/s3_access_point_share_manager.py:535` keeping the reference to the old pivot role. One quick fix is to rename the Sid, but that will leave orphan resources referencing the old pivot role. A better fix is to ensure that the role is that sid is the one of the pivot role. --> 🟢 fixed - [X] ISSUE TO FIX: Missing `kms:DescribeKey` permissions for pivot role from KMS key policy making the share fail. I am not sure how this issue did not surface before. I think it has to due with the by default permissions in KMS vs the ones applied by data.all. `Failed to get kms key id of alias/loc-new-2-eo336u1r: An error occurred (AccessDeniedException) when calling the DescribeKey operation: User: arn:aws:sts::796821004569:assumed-role/dataallPivotRole-cdk-eu-west-1/dataallPivotRole-cdk-eu-west-1 is not authorized to perform: kms:DescribeKey on resource: arn:aws:kms:eu-west-1:796821004569:key/bb37c05a-0588-45f2-a9e4-4075392ee5e1 because no resource-based policy allows the kms:DescribeKey action ` --> permissions added in this [commit](0ba9a24) - [X] ISSUE TO FIX: Table health verification shows unhealthy after update: `Requestor arn:aws:iam::SOURCE_ACCOUNT:role/dataallPivotRole-cdk-eu-west-1 missing LF permissions: ALL for Glue DB Target: loc_imported_c2_kms_URI Requestor arn:aws:iam::TARGET_ACCOUNT:role/dataallPivotRole-cdk-eu-west-1 missing LF permissions: ALL for Glue DB Target: loc_imported_c2_kms_URI_shared ` The issue is solved when we click on `Re-Apply share` but it is a bit annoying that customers need to re-apply all their shares. I think we should introduce an ECS task to re-apply all shares. @anushka-singh already suggested this feature for other purposes --->based on @noah-paige's review, I think the best fix will be to ensure that the pivot role gets granted all the permissions in the verification task, that way the verification won't fail and the re-apply won't be necessary for cases in which the missing pivot role permissions are the source problem. ---> Fix in PR: #1149 -------- Less important - [X] ISSUE UNRELATED TO THIS PR: Run profiling job --> it triggers the profiling job but there is an issue unrelated to this PR related to the profiling script in the S3 bucket of the environment: `key: profiling/code/jars/deequ-2.0.0-spark-3.1.jar.The specified key does not exist` ---> confirm and create issue - [X] ISSUE TO INVESTIGATE: the permissions of the pivot role after the shares are reapplied seem incomplete: 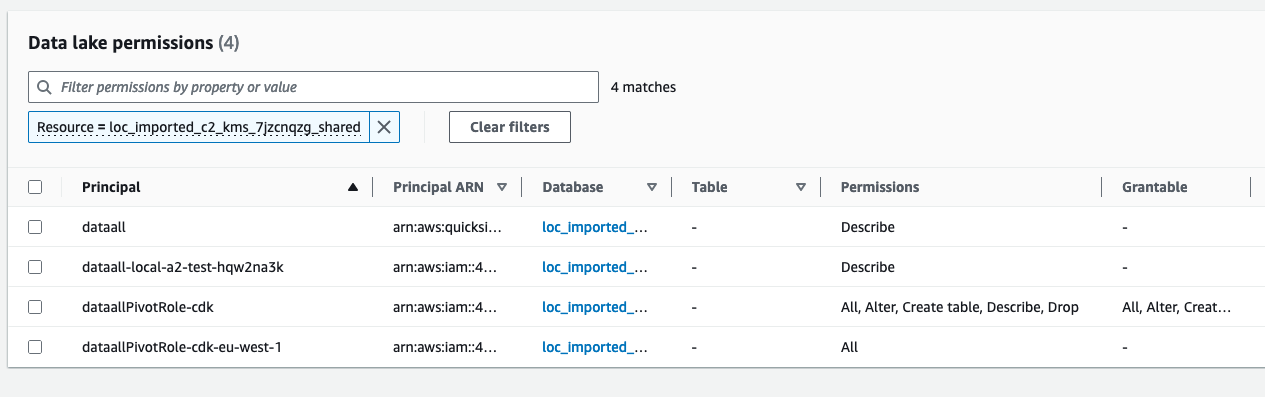 --> 🟢 It does not seem to have an impact on shares, all table sharing keeps on working as expected. ### Relates - #936 - #1048 ### Security Please answer the questions below briefly where applicable, or write `N/A`. Based on [OWASP 10](https://owasp.org/Top10/en/). - Does this PR introduce or modify any input fields or queries - this includes fetching data from storage outside the application (e.g. a database, an S3 bucket)? `No` - Is the input sanitized? `n/a` - What precautions are you taking before deserializing the data you consume? `n/a` - Is injection prevented by parametrizing queries? n/a - Have you ensured no `eval` or similar functions are used? `n/a` - Does this PR introduce any functionality or component that requires authorization? No - How have you ensured it respects the existing AuthN/AuthZ mechanisms? `n/a` - Are you logging failed auth attempts? `n/a` - Are you using or adding any cryptographic features? `No` - Do you use a standard proven implementations?`n/a` - Are the used keys controlled by the customer? Where are they stored?`n/a` - Are you introducing any new policies/roles/users? `Yes` - Have you used the least-privilege principle? How? -----> 🖐️ We use a dedicated IAM role for each data.all Environment onboarded to data.all. This role can access data in its region only. This way the blast radius of any attack is limited to a single AWS region. This PR improves the user experience to use cdk-Pivot role, which encourages users to avoid manual pivot role that has more open permissions and is more error prone. -----> This PR also introduces a tiny change on the IAM permissions of the Lambdas and ECS tasks of the backend. They can now assume `dataallPivotRole-cdk-*` to account for the multiple region roles. This change is still restrictive enough By submitting this pull request, I confirm that my contribution is made under the terms of the Apache 2.0 license.
### Feature or Bugfix - Feature ### Detail - Add details about multi-region pivot roles related to #1064 - Add details about SSM parameter account settings related to #1154 - Add details on all ECS tasks and commands on how to execute on demand task such as the one in #1151 ### Relates - #1064 - #1154 - #1151 ### Security Please answer the questions below briefly where applicable, or write `N/A`. Based on [OWASP 10](https://owasp.org/Top10/en/). `n/a` - Does this PR introduce or modify any input fields or queries - this includes fetching data from storage outside the application (e.g. a database, an S3 bucket)? - Is the input sanitized? - What precautions are you taking before deserializing the data you consume? - Is injection prevented by parametrizing queries? - Have you ensured no `eval` or similar functions are used? - Does this PR introduce any functionality or component that requires authorization? - How have you ensured it respects the existing AuthN/AuthZ mechanisms? - Are you logging failed auth attempts? - Are you using or adding any cryptographic features? - Do you use a standard proven implementations? - Are the used keys controlled by the customer? Where are they stored? - Are you introducing any new policies/roles/users? - Have you used the least-privilege principle? How? By submitting this pull request, I confirm that my contribution is made under the terms of the Apache 2.0 license.
Feature or Bugfix
Detail
Implements #1150
As explained in the issue description, this task is a resource of data.all admins that can run it on-demand using ECS commands or directly in the AWS console. We could extend how it is used:
share-verifiertask daily. We can add a one-liner that triggers the share-reapplier task at the end of the share-verifier task.Testing
Deploying in AWS:
share-reappliershare-reapplierfrom the AWS consoleshare-reapplierwithout any unhealthy share succeedsshare-reapplierwith unhealthy shares succeeds - reapplies the unhealthy sharesRelates
Security
Please answer the questions below briefly where applicable, or write
N/A. Based onOWASP 10.
fetching data from storage outside the application (e.g. a database, an S3 bucket)?
evalor similar functions are used?By submitting this pull request, I confirm that my contribution is made under the terms of the Apache 2.0 license.