ENH: Transfer data to cuda with non_blocking=True #31
Conversation
Transfering the target data to the cuda device with non_blocking=True should speed things up because the targets can transfer while the model is training.
|
Thanks for the PR. I googled around and found no one complaining about negative side effects and in the right conditions it improves performance; which begs the question of why I created a post in the PyTorch discussion forum asking the question and will wait a few days to see if someone can answer it before merging this PR. I'm guessing that there's no particular reason, but I just want to make sure. |
|
Yes, I also had a search and tried to see if there were possible negative downsides. I also don't understand why the default is |
|
I haven't found any issue directly related to use However, according to the statement in official documentation since v0.4.0, the parameter
For detailed explanation, I found this post saying:
And there are some issues about setting With things mentioned above, I guess this is why
Nevertheless, I second this idea since it benefits users. |
Thanks for finding this! Not an obvious place for it to be documented.
Yes, we could do that. It does indeed make more sense to add it to However, there is always a small cost to adding more user-facing parameters to the API (more documentation for the user to read, and a small cognitive burden of considering whether to change this extra parameter). If you think that nobody will ever have a need to change the parameter from a default value of |
|
Yeah, you're right. Since And I did a quick search and found some interesting things:
Honestly, it's a bit hard to tell which approach is proper to be applied. But considering things you mentioned, it seems better to keep the API as simple as possible. Also, there is obviously no issue related to using Besides, I wrote a simple script for this topic, and there are also something interesting worth digging deeper: https://colab.research.google.com/drive/12hE2b9chFeIeHtqcbW0ZCSGLQK0GyFF6
Since it's not a benchmark made under strict conditions, it's just for reference only. |
|
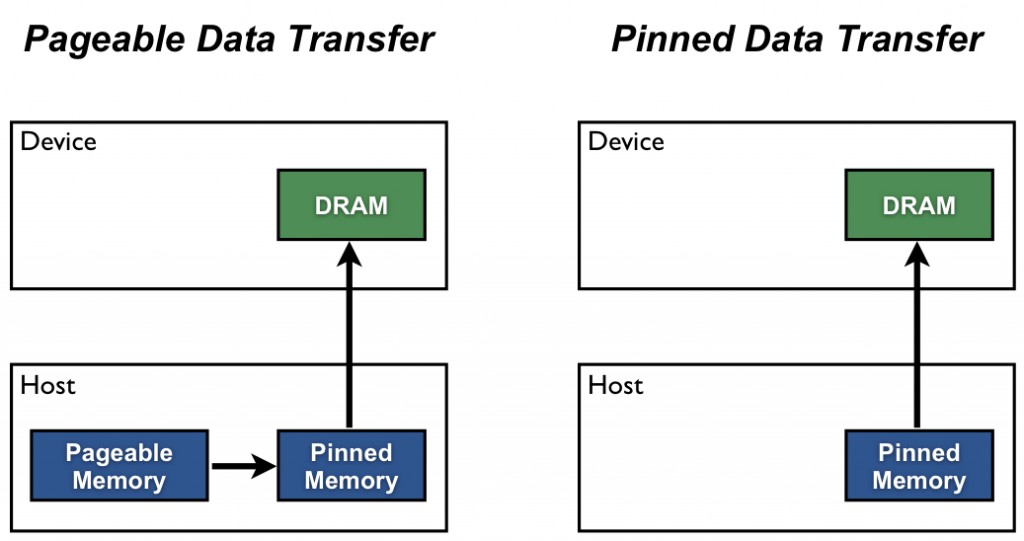
In the CUDA programming model, asynchronous data transfer always requires pinned memory. Therefore, setting non_blocking=True always sends that data to pinned memory first. This might strain pinned memory if using 3D data or other very large mini-batches. |
|
@veritas9872 could you give more details on what "strain pinned memory" means? |
|
@davidtvs Pinned memory is non pageable memory allocated by CUDA. Allocating too much of it causes the system to slow down and in extreme cases even to crash. Most 2D deep learning applications do not allocate that much pinned memory so it is not much of a problem. However, the same holds for pre-fetching. The cases where pinned memory can be overloaded are also the cases where pre-fetch is most important, in cases where a large amount of data has to be sent to device. |
|
@veritas9872 thanks for the explanation. So if I understand correctly there should be no downside to So in summary, it should be safe for us to just have always |
That's exactly what I was thinking. Also thanks @veritas9872 for the explanation. |
I agree that non_blocking=True is a good idea but I would like to correct one misconception. Setting pin_memory=False will still allocate pinned memory before asynchronous transfer. There is simply no going around pinning memory before asynchronous transfer. See cudaMemcpy for details. There may be an advantage in that only the main process will be able to set pinned memory instead of all of the DataLoader's worker processes. I am not sure how DataLoader handles it. If DataLoader only allocates pinned memory for the main process anyway, there will be no difference. Finally, there must be an option to setting non_blocking=False and disabling asynchronous transfer and pre-fetch for extremely large 3D volumes or other such cases. While this would also cause severe delays, I have had several cases where using asynchronous transfer simply could not be made to work due to the size of the data. Training slowly is better than having the computer go dark again and again. |
|
Okay, thanks for the feedback everyone, especially @veritas9872. I've now added a This should provide the best user experience, as the transfer will automatically be asynchronous if possible, but the behaviour can be disabled in the rare cases that it causes a problem. |
This parameter controls whether to use the non_blocking flag when transferring data from the CPU to the CUDA device. In general, it is fine to use a non_blocking transfer, but the option to disable it is provided in case the user has problems with very large tensors allocated to pinned memory.
Codecov Report
@@ Coverage Diff @@
## master #31 +/- ##
=========================================
Coverage ? 66.66%
=========================================
Files ? 2
Lines ? 219
Branches ? 0
=========================================
Hits ? 146
Misses ? 73
Partials ? 0
Continue to review full report at Codecov.
|

|
Merged, thanks @scottclowe for the PR and to everyone else for the discussion 🥇 |
@veritas9872 Thanks for pointing that out! From the documentation of
Then I found this post said:
Back to the post How to Optimize Data Transfers in CUDA C/C++, there is a figure just telling what you said: As for this doubt:
I've tried my best to trace the source code, and here is what I found: # This setting is thread local, and prevents the copy in pin_memory from
# consuming all CPU cores.
torch.set_num_threads(1)It seems that this line prevents pinned memory being allocated by other worker threads. But it's just a guess, I haven't figure out how to test it. Anyway, many thanks to all of you. This PR makes me learn a lot. 😄 |
Transfering the target data to the cuda device with
non_blocking=Trueshould speed things up because the targets can transfer while the model is training.I was considering adding an
__init__argument to control whether to use a non-blocking transfer, but as far as I am aware there are no negative consequences of always usingnon_blocking=True, so I have changed it to be always enabled.