![]()
An automation web crawling framework for retrieving for Extracting Central Bankers' Speeches on the Website of Bank for International Settlements (https://www.bis.org) based on Selenium and Chrome browser.
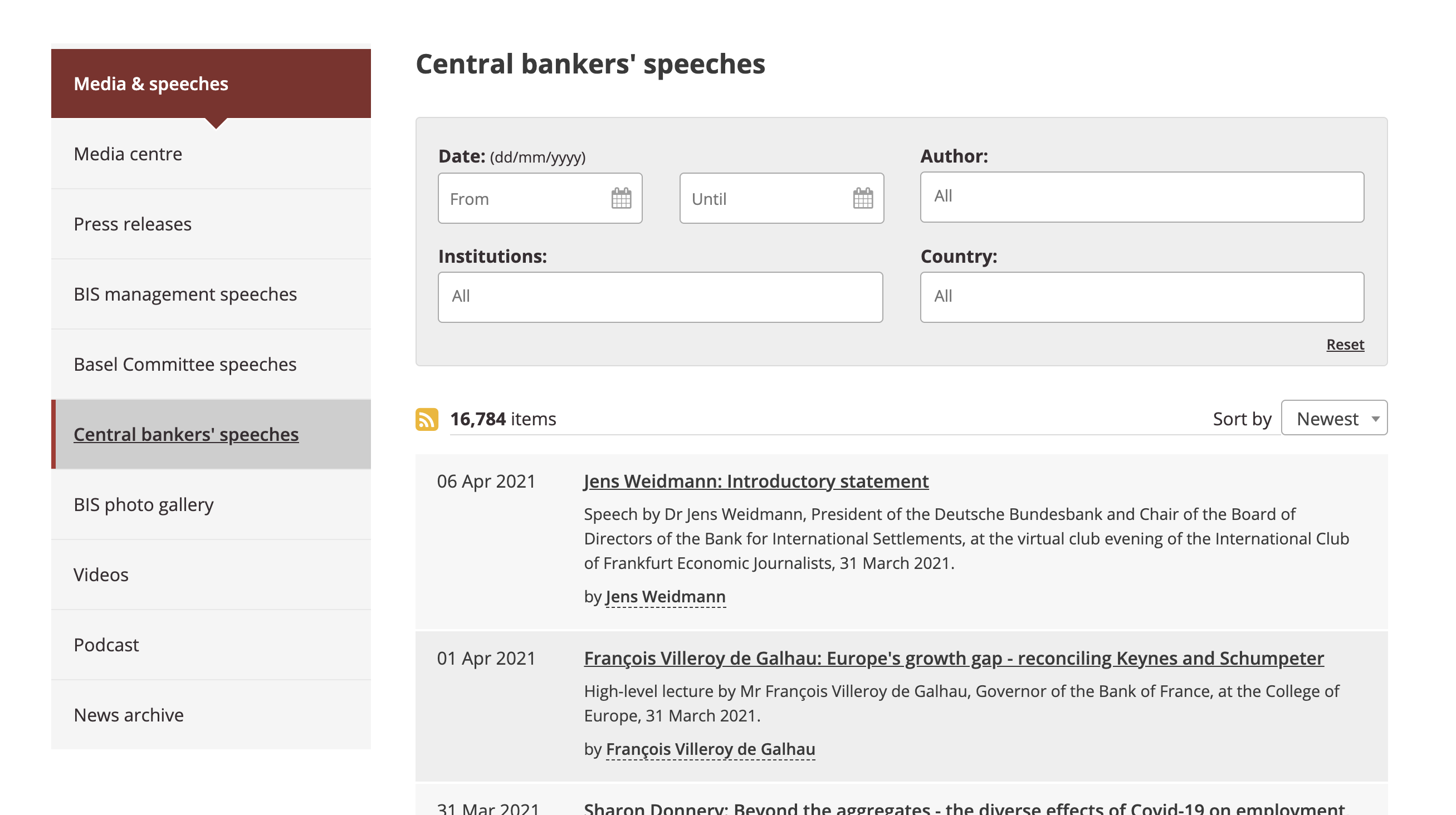
- Need to install Anaconda Navigator and Python>=3.9 beforehand. And then, open the terminal and download
bisCrawlerrepository by usinggit clone. About how to use git and Github, please have a look at this Tutorial for Beginners.
git clone git@github.com:davidycliao/bisCrawler.git
- Copy the commands below and paste them into the terminal:
# Change the directory by typing `cd` command once `bisCrawler` repository is downloaded.
cd bisCrawler
# Create the enviroment by using conda and name the enviroment `bisCrawler`.
conda create -n bisCrawler python=3.9
- Activate the pre-named enviroment. Alternatively, the environment for bisCrawler can be opened via Anaconda Navigator
conda activate bisCrawler
- Install the dependencies from
requirements.txtusingpipmethond.
pip install -r requirements.txt
- Call
bisCrawlerModuel
- In the terminal:
# Note: you need to run it in the terminal where you activated the enviroment.
python bisCrawler.py
- In Jupyter Notebook:
from bisCrawler import scraper
scraper()
- When Running bisCrawler
When bisCrawler is running, you will be asked which page you would like to scrape (please, type any single digit from 1 to last page). Then bisCrawler will automatically generate pandas dataframe to restore the banker speeches and the urls to the textual document.
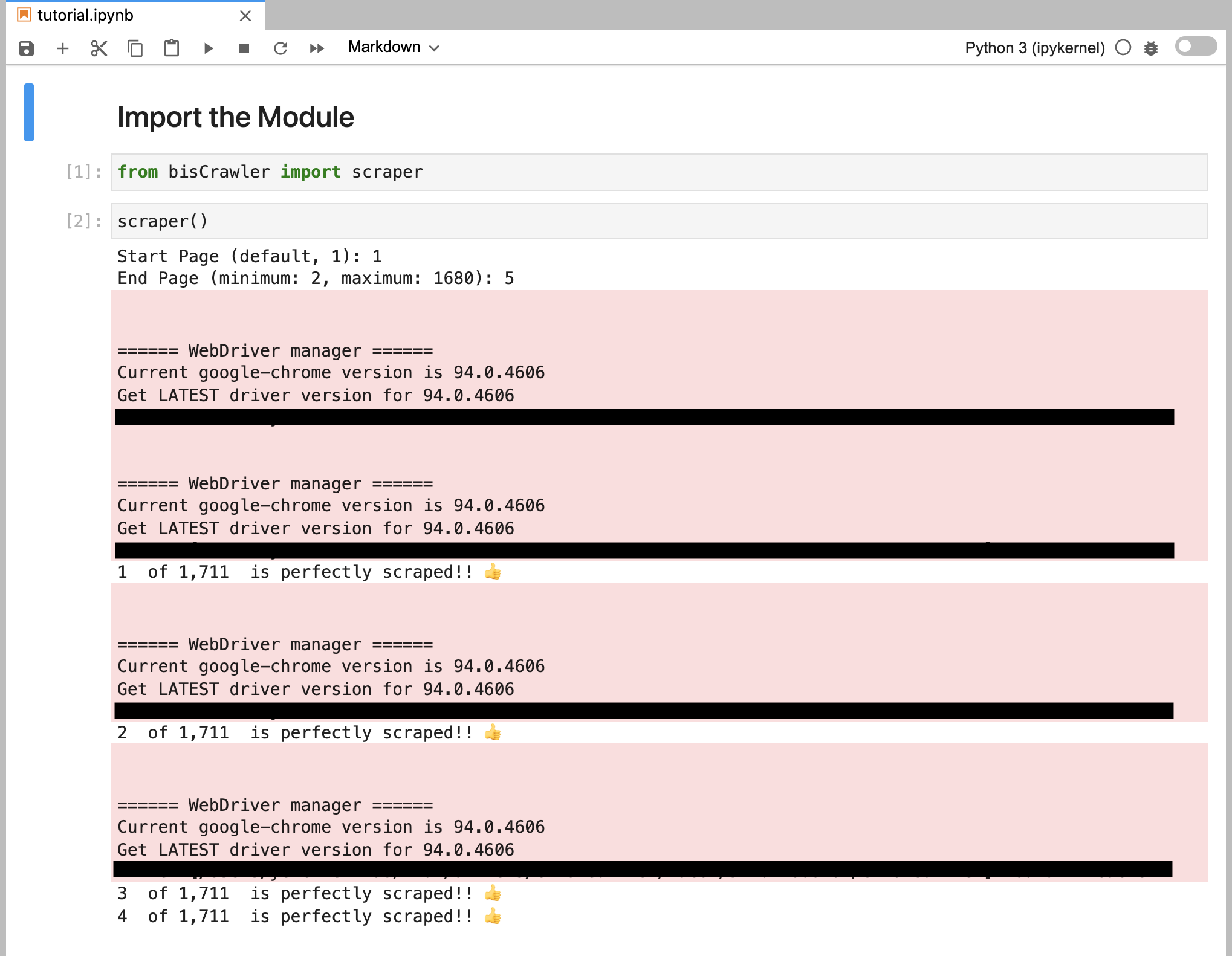
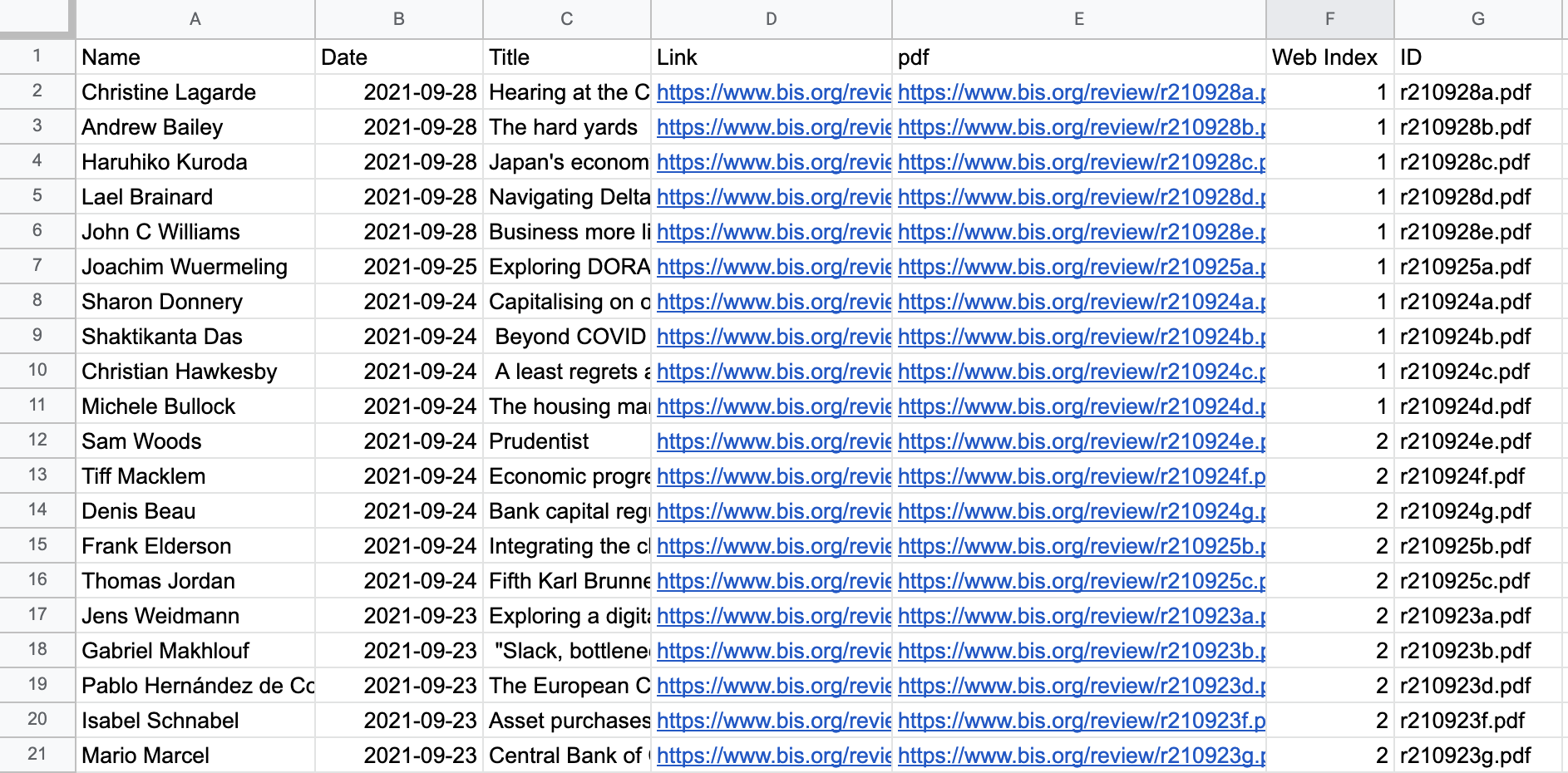
This designed crawler automatically webscrapes the central bankers' speeches from the offical website, including a bunch of information with regards to each name of central banker, date and title and corresponding url to the textual document.

The scraped dataframe will be stored as central_bank_speeches.csv in the bisCrawler folder.
Please cite this page if you use this toolkit for your research.
For example, with BibTeX:
@misc{bisCrawler,
howpublished = {\url{https://github.com/davidycliao/bisCrawler}},
title = {bisCrawler: An Automation Webcrawler for Extracting Central Bankers' Speeches},
author = {David Yen-Chieh Liao and Li Tang},
publisher = {GitHub},
year = {2021}
}