{kind=link}
Code for the CVPR 2019 paper Few-Shot Learning with Localization in Realistic Settings. Due to the sheer number of independent moving parts and user-defined parameters, we are providing our code as a series of interactive Jupyter notebooks rather than automated Python scripts.
If you find this code or paper useful to your research work, please consider citing it using the following bibtex:
@InProceedings{Wertheimer_2019_CVPR,
author = {Wertheimer, Davis and Hariharan, Bharath},
title = {Few-Shot Learning With Localization in Realistic Settings},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2019}
}
This code requires Pytorch and torchvision 1.0.0 or higher with cuda support, and Jupyter.
It has been tested on Ubuntu 16.04.
The meta-iNat and tiered meta-iNat ("Supercategory meta-iNat") datasets can be downloaded from here, or constructed manually.
To construct meta-iNat from scratch, you must download the iNat2017 dataset. Download and unpack the iNat2017 training/validation images, and the training bounding box annotations, to a directory of your choice. The images and bounding box annotations can be found here.
If you are constructing meta-iNat from scratch, begin by running the Setup notebook, which constructs the meta-iNat dataset or a variant according to user-defined parameters. The default parameters reproduce the meta-iNat dataset used in the paper. If you downloaded meta-iNat directly, you can skip this step.
The Train notebook trains an ensemble of learners in parallel, according to user-defined parameters. The default parameters reproduce the best-performing model in the paper (batch folding, covariance pooling, and few-shot localization).
The Evaluate notebook tests your trained models on the reference/query images, according to user-defined parameters. It is highly recommended that your parameters for evaluating a given model match the ones used to train it. The default parameters for the evaluation code match those for the training code.
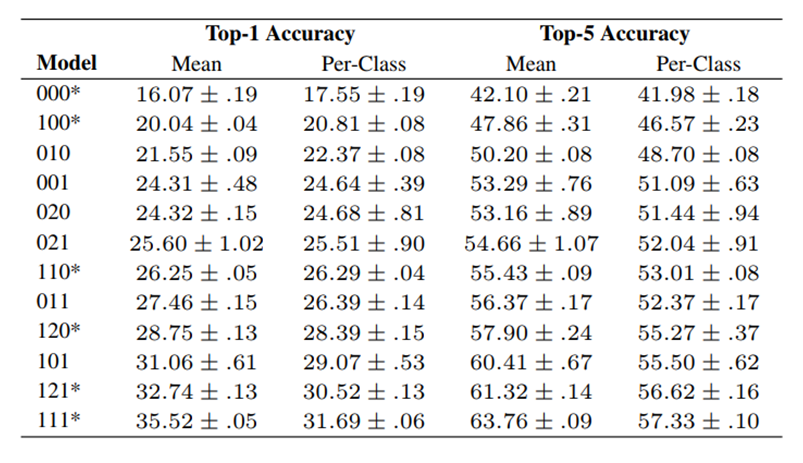
Three-digit model names indicate the presence or absence of batch folding, localization, and covariance pooling, in that order. For example, ‘101’ indicates a model with batch folding and covariance pooling, but no localization. '000' is a standard prototypical network. Because two versions of localization exist, we use ‘0’ to indicate no localization, ‘1’ for few-shot localization, and ‘2’ for unsupervised localization. A ‘*’ indicates a model presented in the main paper.