This package implements MWEM, a simple and practical algorithm for differentially private data release.
MIT Licensed. See LICENSE.md.
Open a Julia prompt and call:
Pkg.clone("https://github.com/mrtzh/PrivateMultiplicativeWeights.jl.git")
- Differentially private synthetic data preserving lower order marginals of an input data set
- Optimized in-memory implementation for small number of data attributes
- Scalable heuristic for large number of data attributes
- Easy-to-use interfaces for custom query sets and data representations
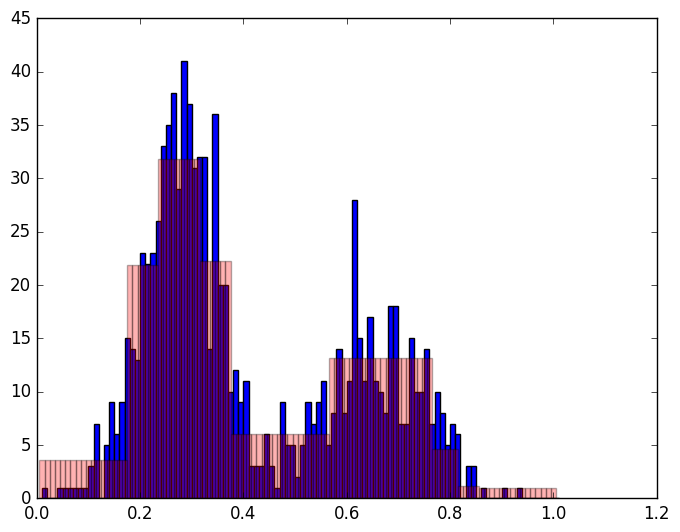
Check out histograms.ipynb for details on how to
use the algorithm to compute differentially private histogram approximations.
The package can also be used to create synthetic data that approximates the lower order marginals of a data set with binary features. For the sake of illustration, we create a random data set with hidden correlations. Columns correspond to data points.
d, n = 20, 1000
data_matrix = rand(0:1, d ,n)
data_matrix[3, :] = data_matrix[1, :] .* data_matrix[2, :]
We can run MWEM to produce synthetic data accurate for 1st, 2nd, 3rd order marginals of the source data.
using PrivateMultiplicativeWeights
mw = mwem(Parities(d, 3), Tabular(data_matrix))
This will convert the data to its explicit histogram representation of size 2^d and may not be useful when d is large. See section on factored histograms for an alternative when the dimension d is large.
We can convert synthetic data in histogram representation to a tabular (matrix) representation.
table = Tabular(mw.synthetic, n)
Compute error achieved by MWEM:
maximum_error(mw), mean_squared_error(mw)
Note that these statistics are not differentially private.
Parameters can be set flexibly with the MWParameters constructor:
mw = mwem(Parities(d, 3),
Tabular(data_matrix),
MWParameters(epsilon=1.0,
iterations=10,
repetitions=10,
verbose=false,
noisy_init=false))
Available parameters:
| Name | Default | Description |
|---|---|---|
epsilon |
1.0 |
Privacy parameter per iteration. Each iteration of MWEM is epsilon-differentially private. Total privacy guarantees follow via composition theorems. |
iterations |
10 |
Number of iterations of MWEM. Each iteration corresponds to selecting one query via the exponential mechanism, evaluating the query on the data, and updating the internal state. |
repetitions |
10 |
Number of times MWEM cycles through previously measured queries per iteration. This has no additional privacy cost. |
noisy_init |
false |
Histogram initalization through noise addition. This incurs an additional epsilon privacy cost. When noisy_init is set to false, the initialization is uniform. |
verbose |
false |
print timing and error statistics per iteration (information is not differentially private) |
The function MWParameters accepts any subset of parameters, e.g.,
MWParameter(epsilon=0.5, iterations=5).
By default, MWEM works with the histogram representation of a data sets. This
means that the data is represented by a vector whose length is equal to the size
of domain. For example, data consisting of d binary attributes would be
converted to an array of length 2^d. MWEM needs to store and array of this
length in main memory, which is often the computational bottleneck.
When the histogram representation is too large, try using factored histograms. Factored histograms maintain a product distribution over clusters of attributes of the data. Each component is represented using a single histogram. Components are merged as it becomes necessary. This often allows to scale up MWEM by orders of magnitude.
d, n = 100, 1000
data_matrix = rand(0:1, d, n)
data_matrix[3, :] = data_matrix[1, :] .* data_matrix[2, :]
mw = mwem(FactorParities(d, 3), Tabular(data_matrix))
Also see examples.jl.
There are two ways to define custom query sets.
Histogram queries are linear functions in the histogram representation of the
data. You can define custom query workloads by using
HistogramQueries(query_matrix) instead of Parities(d, 3). Here query matrix is an N x k matrix specifying the query set in its Histogram
representation, N is the histogram length and k is the k is the number of
queries.
To build query sets with your own implicit representations, sub-type
Query and Queries. Implement the functions specified in src/interface.jl.
See src/parities.jl for an example.
-
Parities(d, k)
Parities of
kout ofdattributes. This corresponds to approximatingk-way marginals of the original data. -
FactorParities(d, k)
Parities of
kout ofdattributes for factored histogram representation. -
RangeQueries(N)
Range queries corresponding to all interval queries over a histogram of length
N.
There are many ways to contribute to this repository:
- Experiments
- Additional query sets (e.g., two-dimensional range queries)
- Additional tests, debugging, optimization
- Additional documentation
The MWEM algorithm was presented in the following paper:
@inproceedings{HLM12,
author = "Moritz Hardt and Katrina Ligett and Frank McSherry",
title = "A simple and practical algorithm for differentially-private data release",
booktitle = {Proc.\ $26$th Neural Information Processing Systems (NIPS)},
year = {2012},
}
